
这是 2021 年性能专家 Brendan Gregg(《性能之巅》作者)在 USENIX 上做的关于 eBPF 工作原理的演讲。最近在找这方面的资料,演讲的内容看着是相当的不错,可以作为一个 eBPF 的大纲。
视频链接:LISA21 - BPF Internals (YouTube)。
演讲介绍

这次演讲将展示 eBPF 的工作原理,直到机器码层面。我(Brendan)之前没做过这方面的分享,其实这些内容看着也是挺简单的!(微笑)

我不会去讲 eBPF 的特定指令和功能,因为那些参考资料在网上都有了。我要分享的是:
- eBPF 在追踪方面(tracing)的示例。
- 示例中的所有组件是如何工作的。
eBPF 的历史

首先,简要介绍一下 BPF:BPF 来自 BSD,它最初代表的是 Berkeley Packet Filter(伯克利包过滤器)。这是一种鲜为人知的技术,用于加速 TCP dump 和包过滤,因为包的速率可能非常高。有了 BPF 后,用户空间就可以定义一个过滤器,然后将其编译成最高效的指令,并且这些指令会在包接收流程的最短路径(最靠近的位置)下运行。
这项技术有趣的是,它的工作原理就像是一个运行在内核中的虚拟机。

2013 年,BPF 得到了改进,而这种扩展的、现代化的 BPF,就是 eBPF。在规格层面上,eBPF 使用的字长从 32 位变成了 64 位,也有了更多的寄存器,以及几乎无限的存储(map 结构体)空间。eBPF 也不再是只附着(attach)在包上,现在它可以附着在许多不同的事件源上,并在 Linux 内核的内部运行许多的(用户实现的 eBPF)程序。

总之 BPF/eBPF 已经不再是代表包过滤的单一事物,它现在指的是在 Linux 内核中安全、高效执行程序的一种通用环境。一般来说 BPF 和 eBPF 这两个名词可以混用,下文开始也会混用。
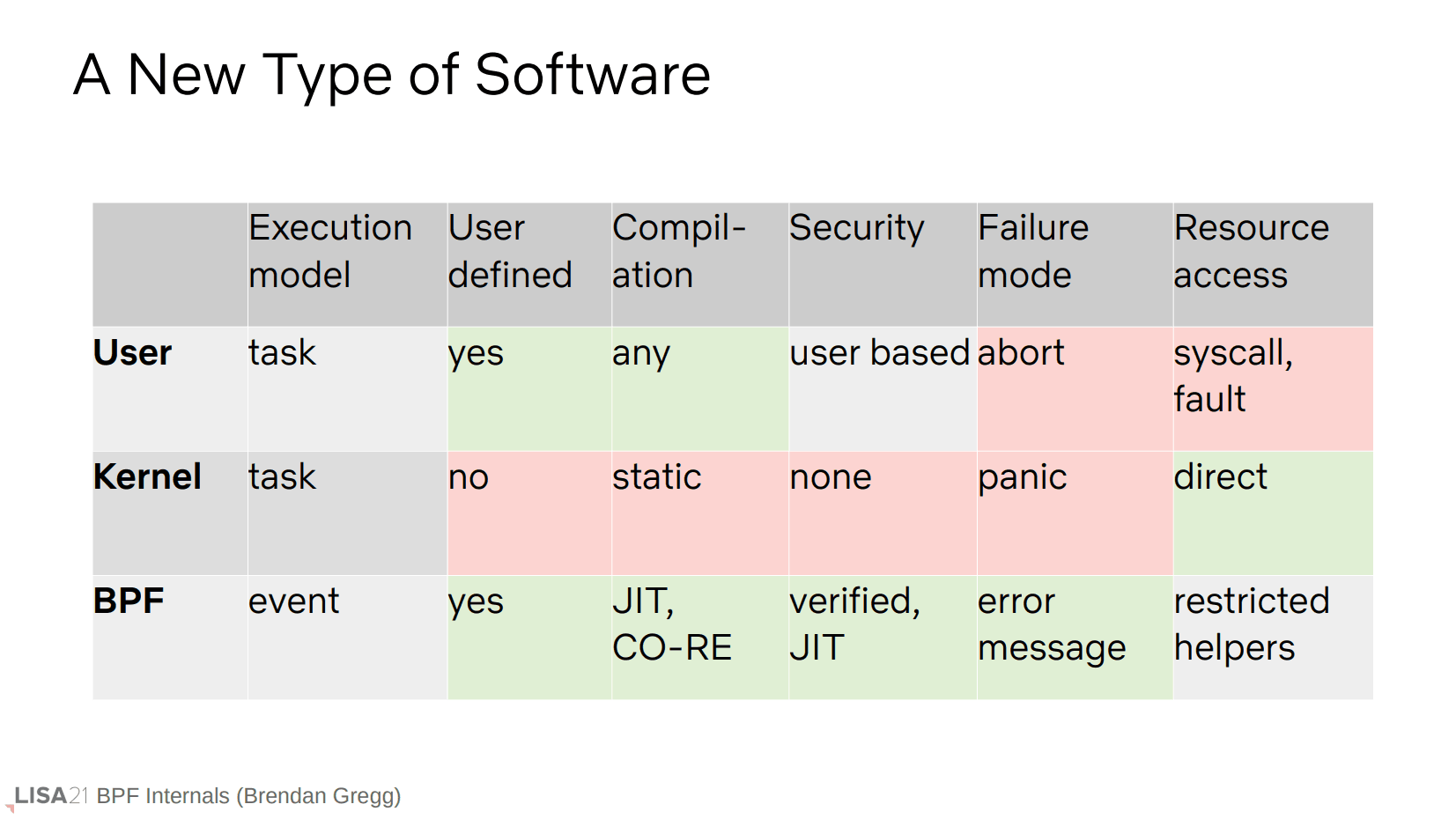
前面提到的程序指的是 BPF 程序,具体优势见上表的 BPF 表项。简单来说是比用户空间程序更快,比内核(代码/模块)更安全(但是也更受限)。一个显著的区别是 BPF 程序是基于事件执行的,大概意思是它不能主动调用,只能附着到事件,当事件到来后由内核调用。
NOTE: CO-RE 指的是一次编译,到处运行。
eBPF 的追踪
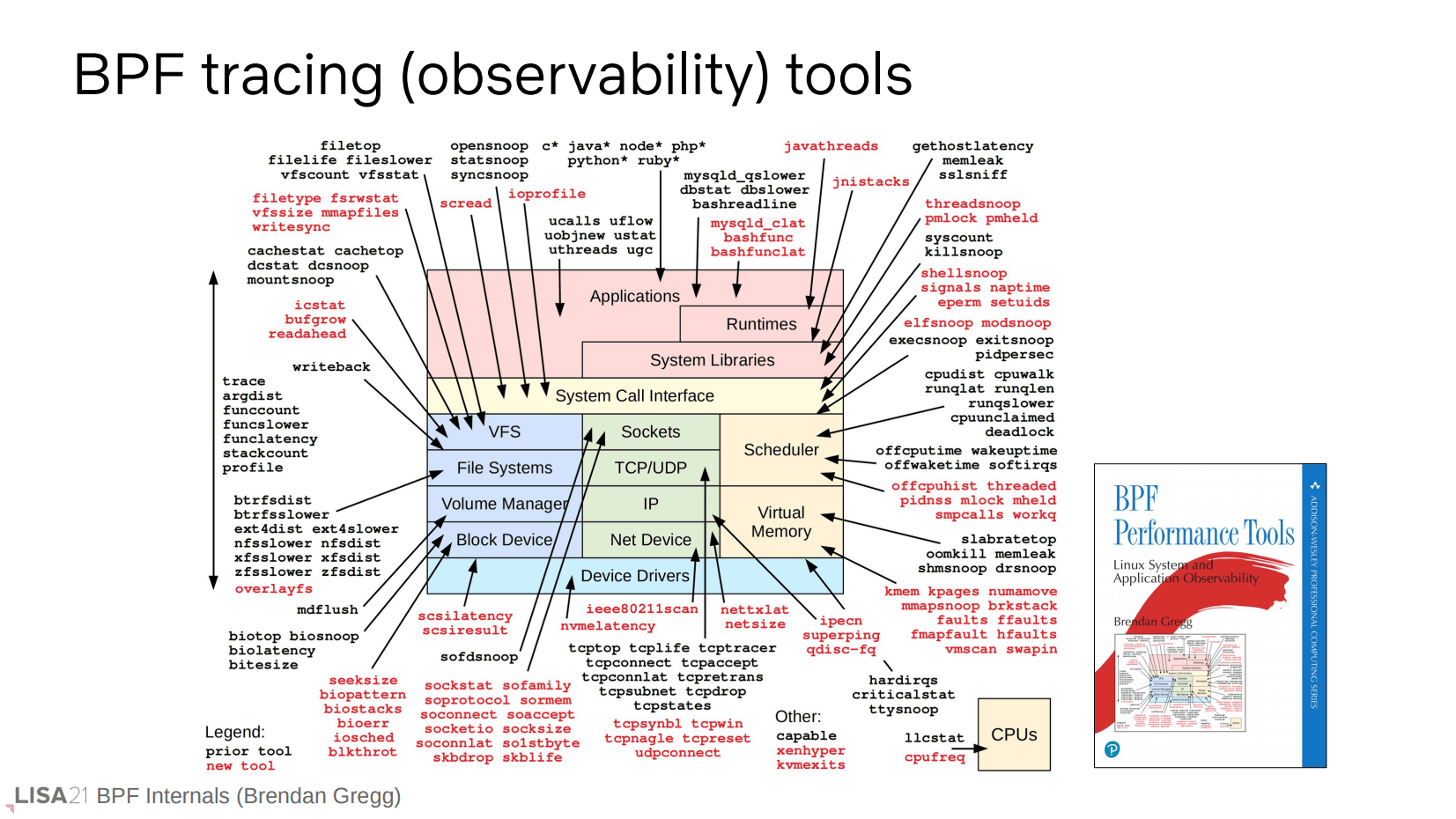
作者也写了很多开箱即用的性能观测(追踪)工具,可以到 Github 翻一下 bcc 和 bpftrace 项目的 tools 目录,有需要直接拿来用就好。

这是一些 eBPF 前端工具的使用建议。这些前端的功能和复杂度自上而下递增。
eBPF 的内部

现在开始讲解 eBPF 内部的工作原理。
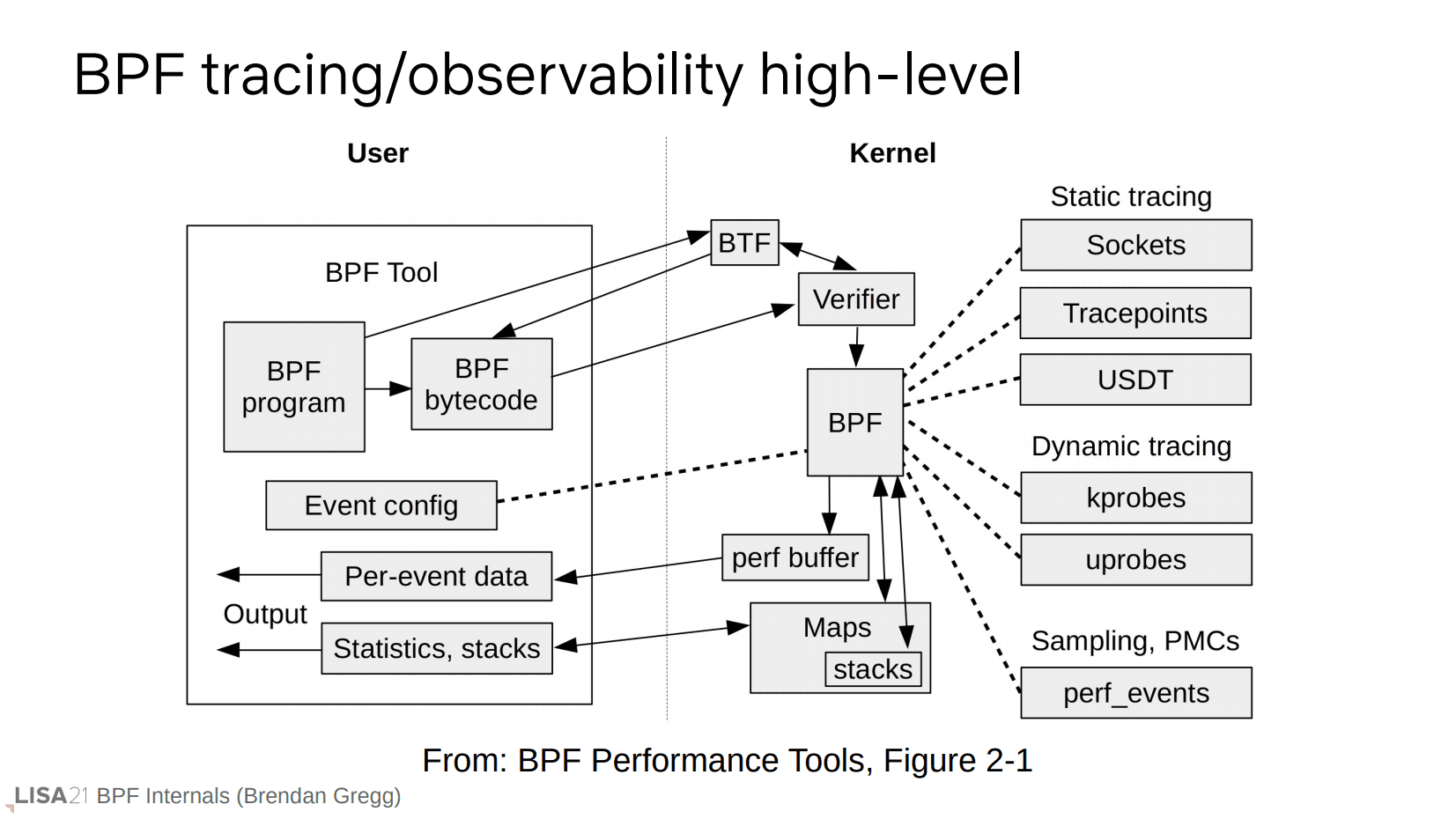
上图是一个追踪工具的简化工作流程。在图的示例中,用户空间里的 BPF 工具有一个 BPF 程序,它被转换为了 BPF 字节码。紧接着字节码被传输到内核部分的验证器(verifier),这个过程可能用到 BTF(byte type format)用于提供结构体信息。验证通过后可以连接到不同的事件源(图右侧),这些事件是在用户空间就已经决定好的,并且在执行过程中,可以通过 perf buffer 或者 map 进行内核态到用户空间的传输(看箭头,前者单向,后者双向)。

后面会用到这些术语,观众先提前做下检查。
bpftrace 示例

这是一个由 bpftrace 封装的追踪程序。它通过 kprobe 追踪内核的 do_nanosleep 函数作为一个事件,每次触发都会输出 pid。

要完成这件事,需要搞明白三件小事:程序如何转换成字节码、内核事件怎样映射到字节码、以及如何把事件输出到用户态。
bpftrace 内部
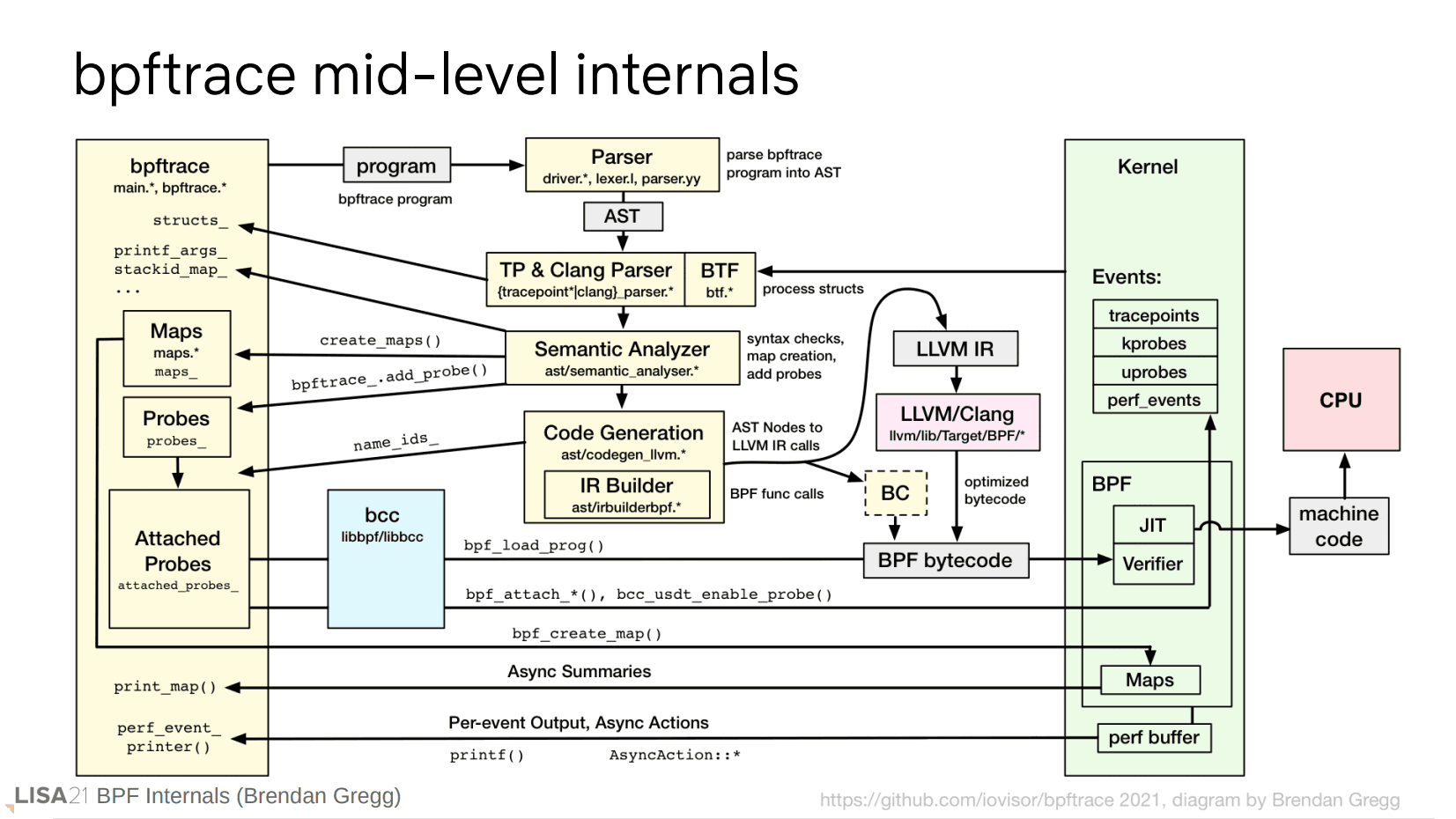
下面将解释这一整个过程,从程序转换(左上角 program)开始。
程序的转换
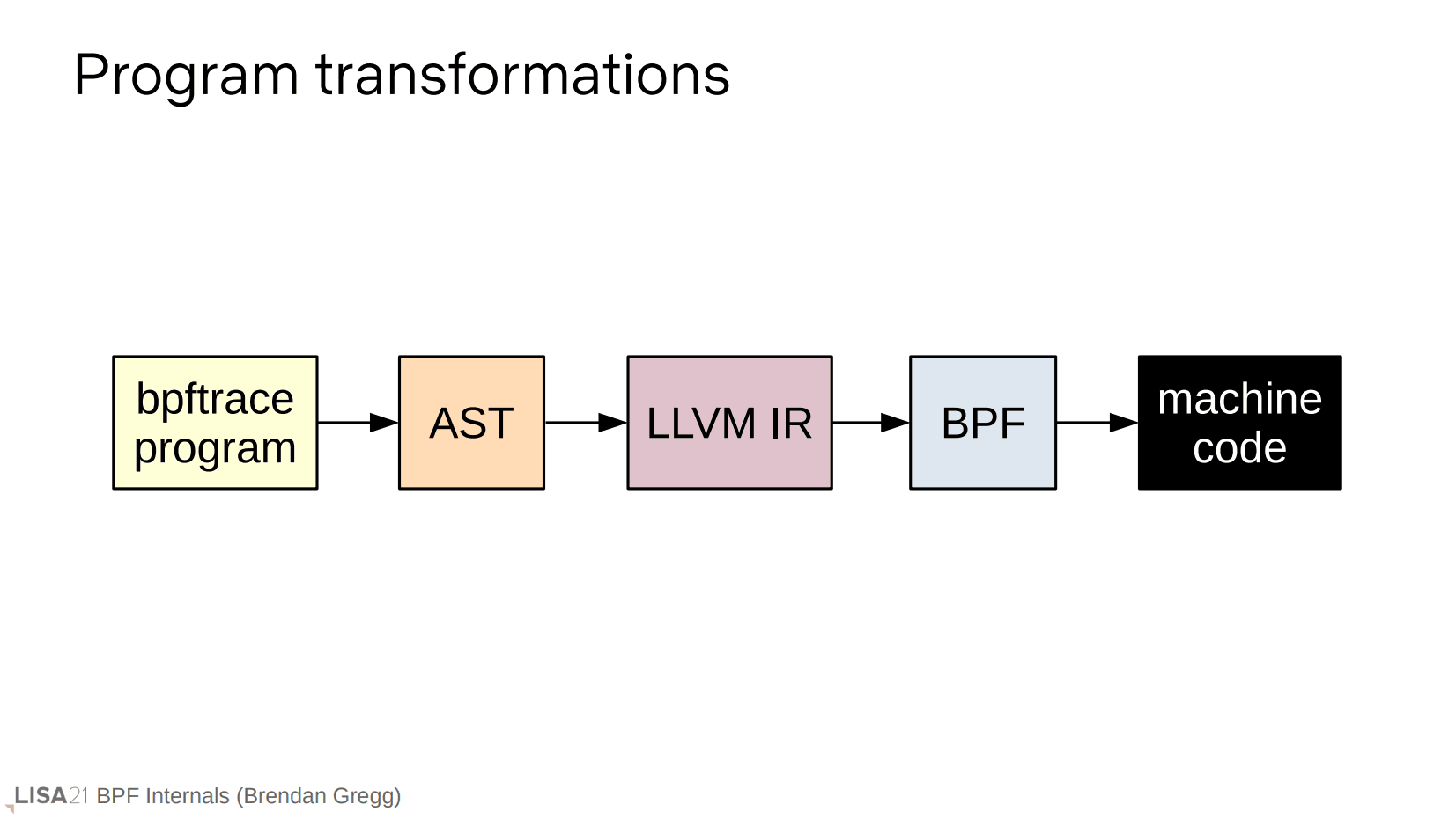
程序的转换经历以上的步骤。bpftrace 程序本身是一个 ASCII 文本,经由 AST 和 LLVM IR 而编译成 BPF 字节码。就是说,前面只有三行的 bpftrace 程序,是处于第一步的状态。
AST
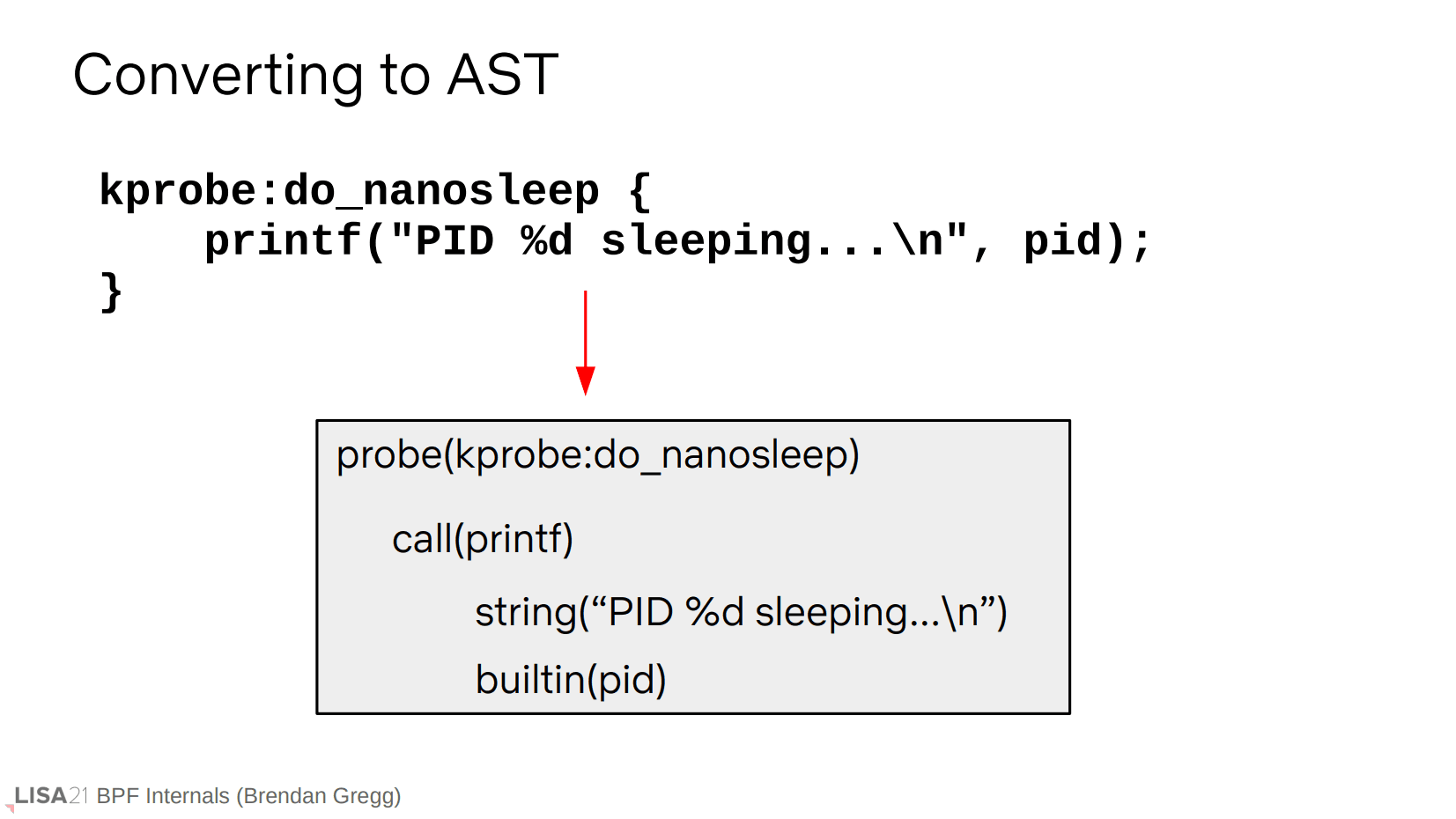
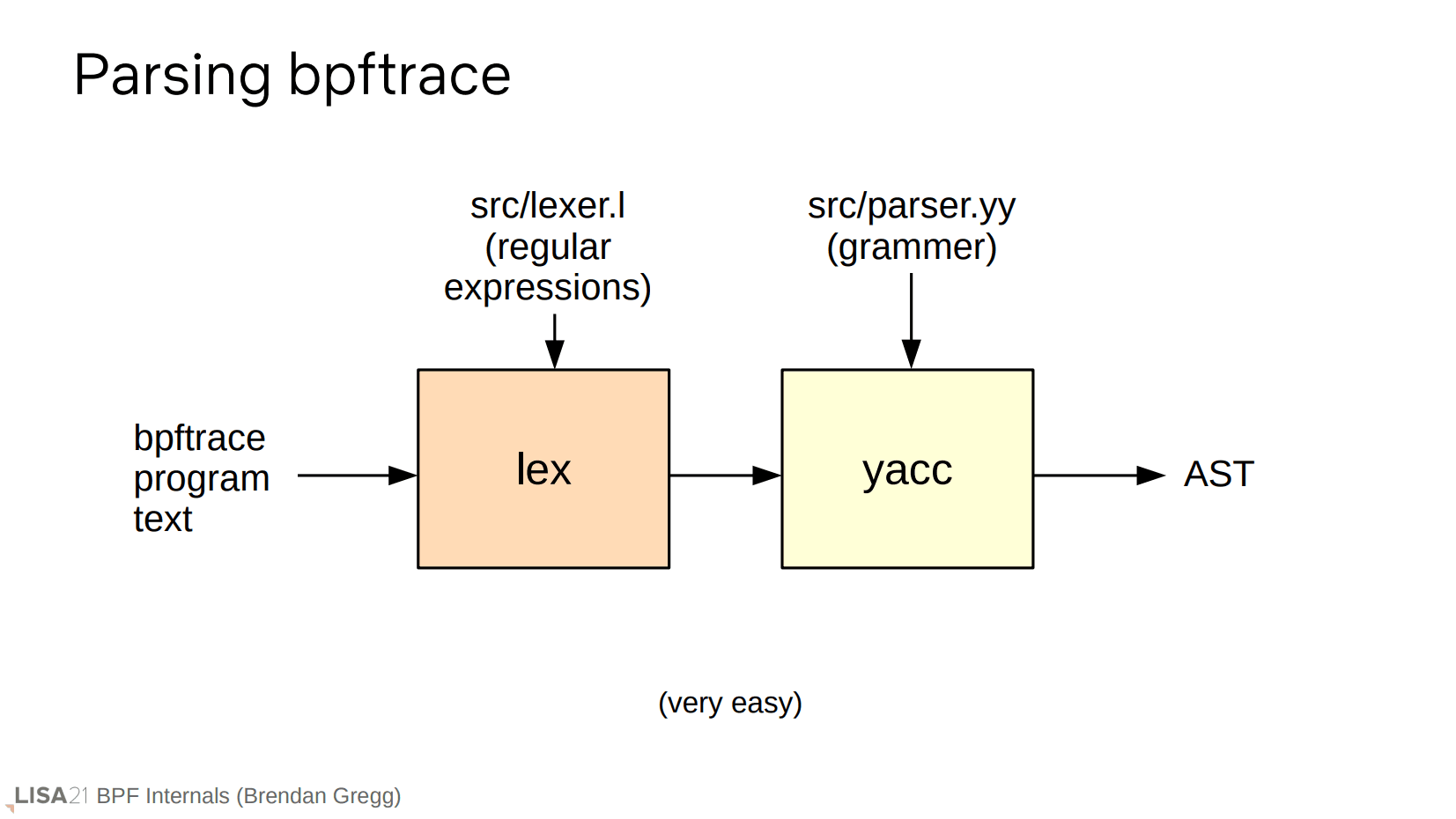
第二步是生成 AST。具体来说就是使用 lex 和 yacc。

在上面的示例中,由于使用了 pid(bpftrace 内置变量),因此在 lex 查表过程中识别为 builtin。

进一步在 yacc 中匹配就能分配一个关于 pid 的 AST 结点。

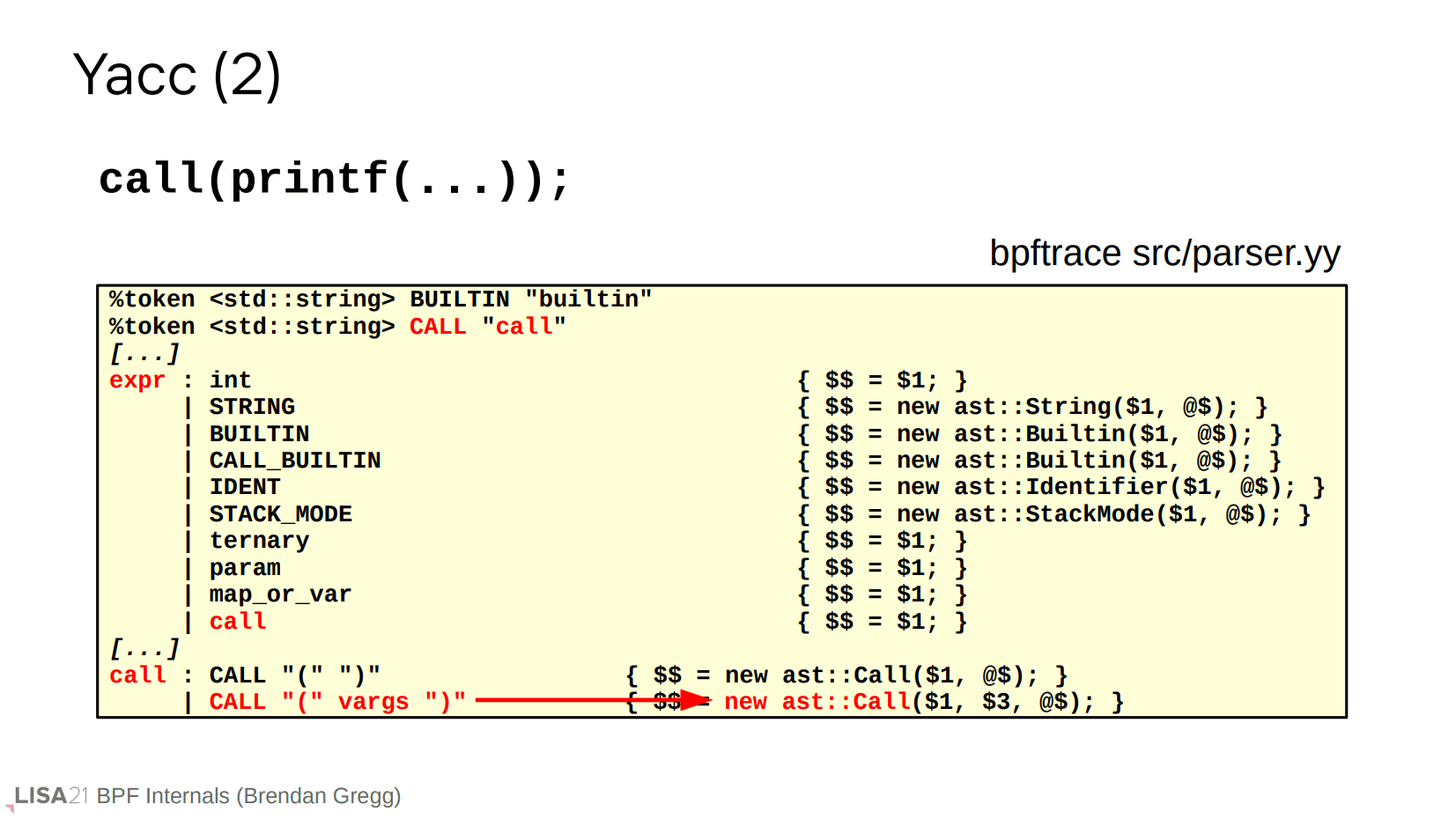
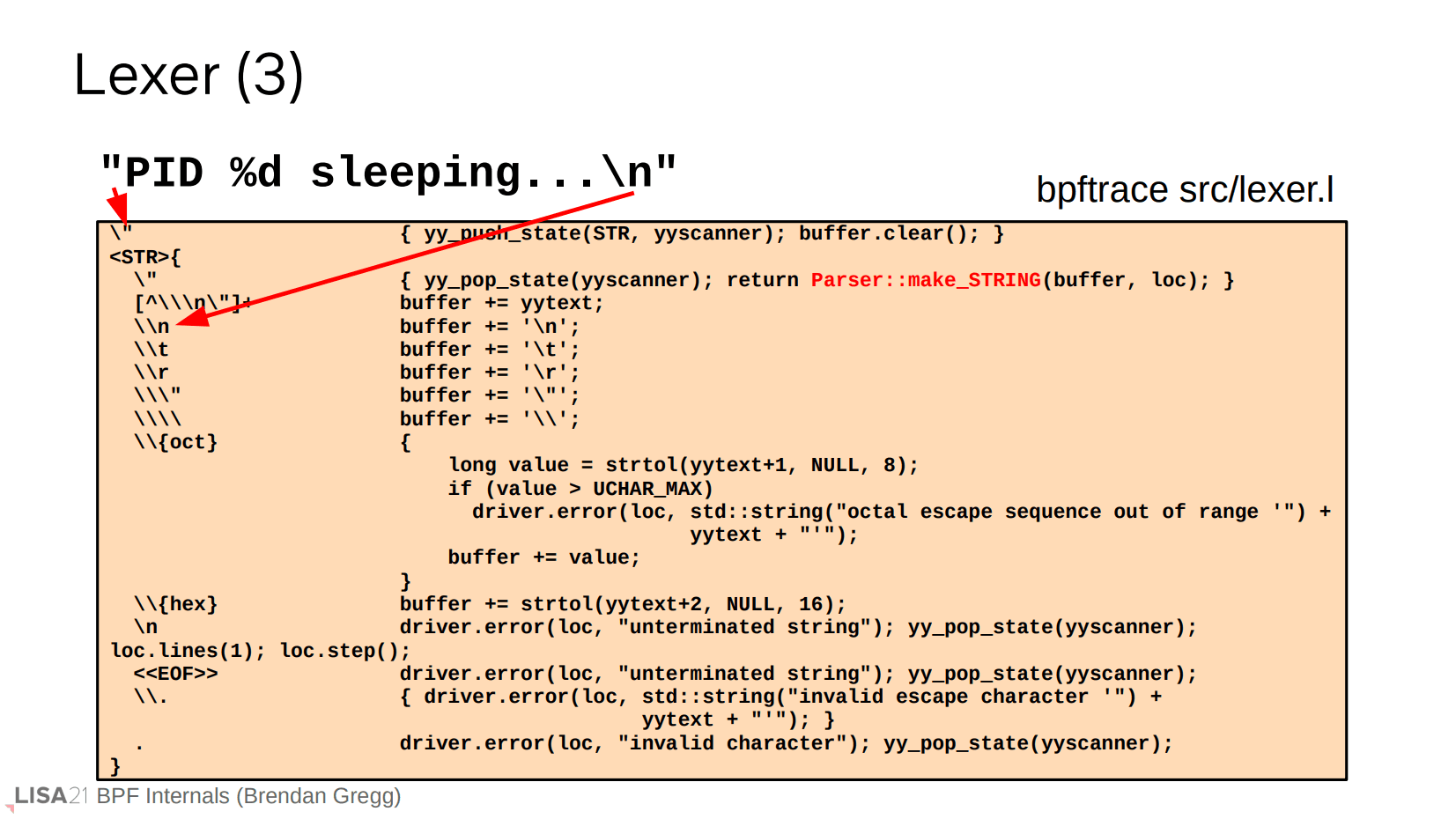
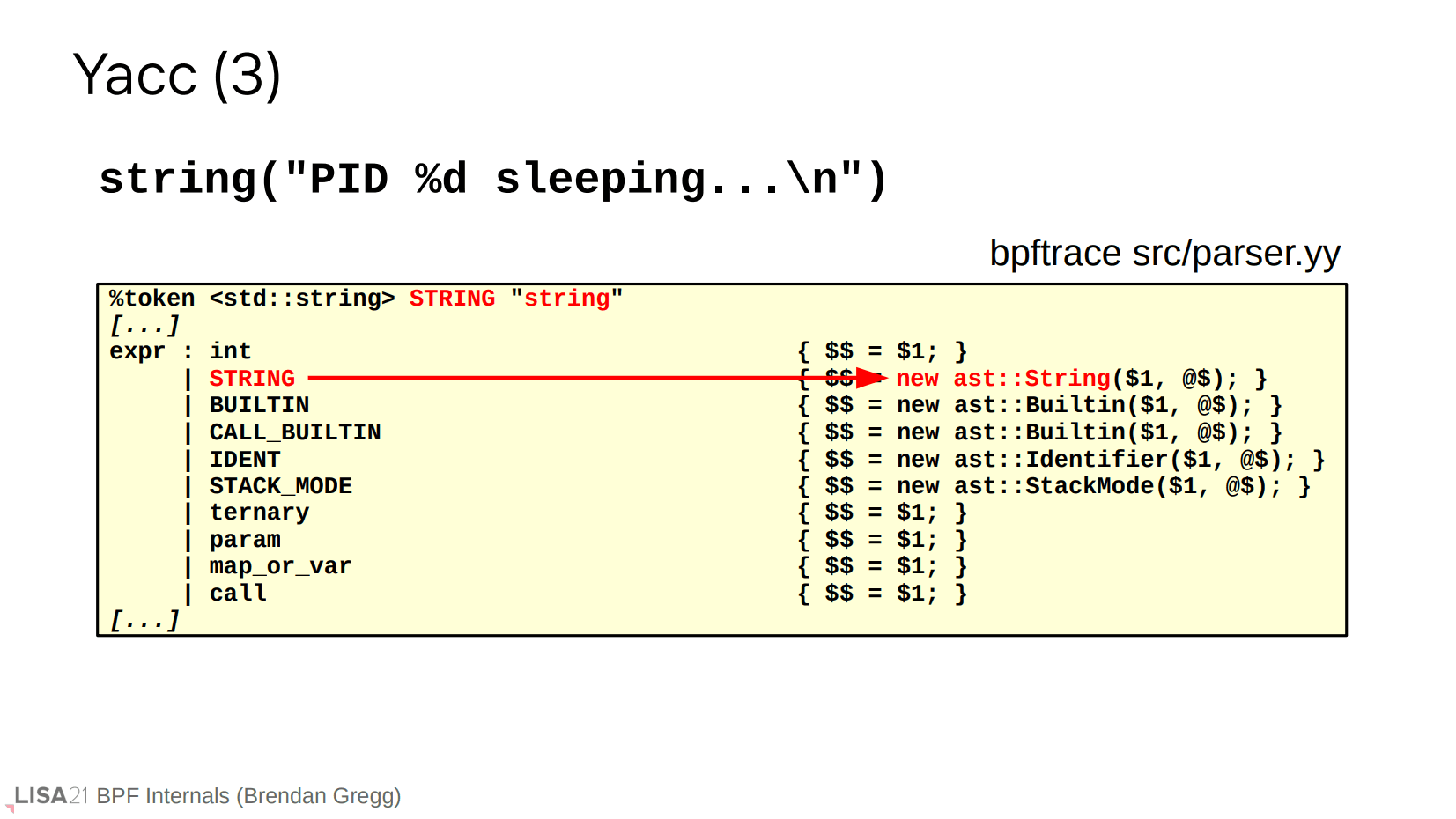
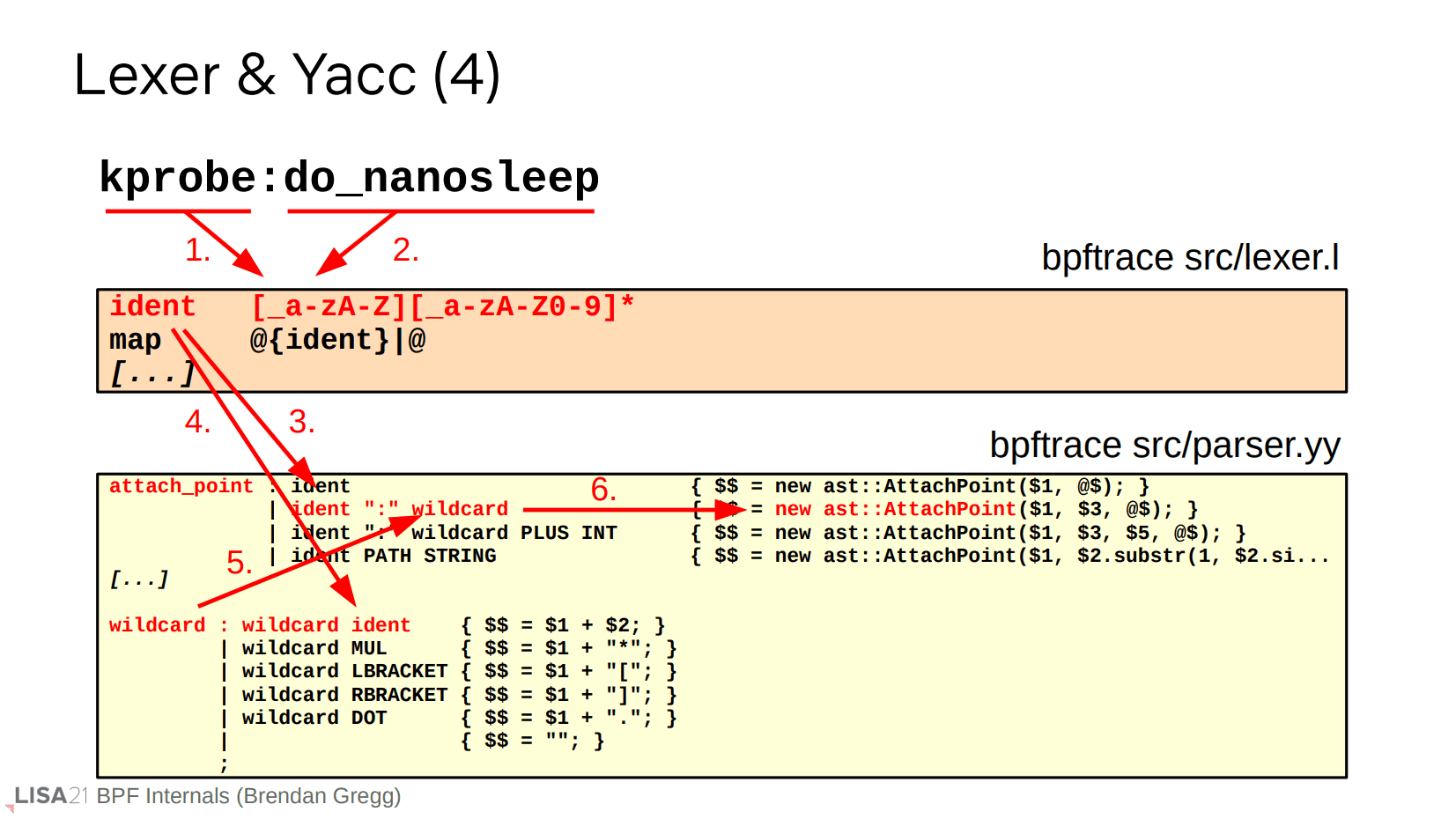
printf、字符串、甚至 kprobe 也是类似的过程。像 printf 这种表达式的调用可以存在变参,它们被直接传递到 AST 函数当中。注意 kprobe 区分了 ident 和 wildcard,使得探测点(探针)支持通配符形式,比如 kprobe:do_*。

这就是 AST 的最终形式。NOTE: AST 的结构示意可以使用 -d 查看。
Clang 解析器
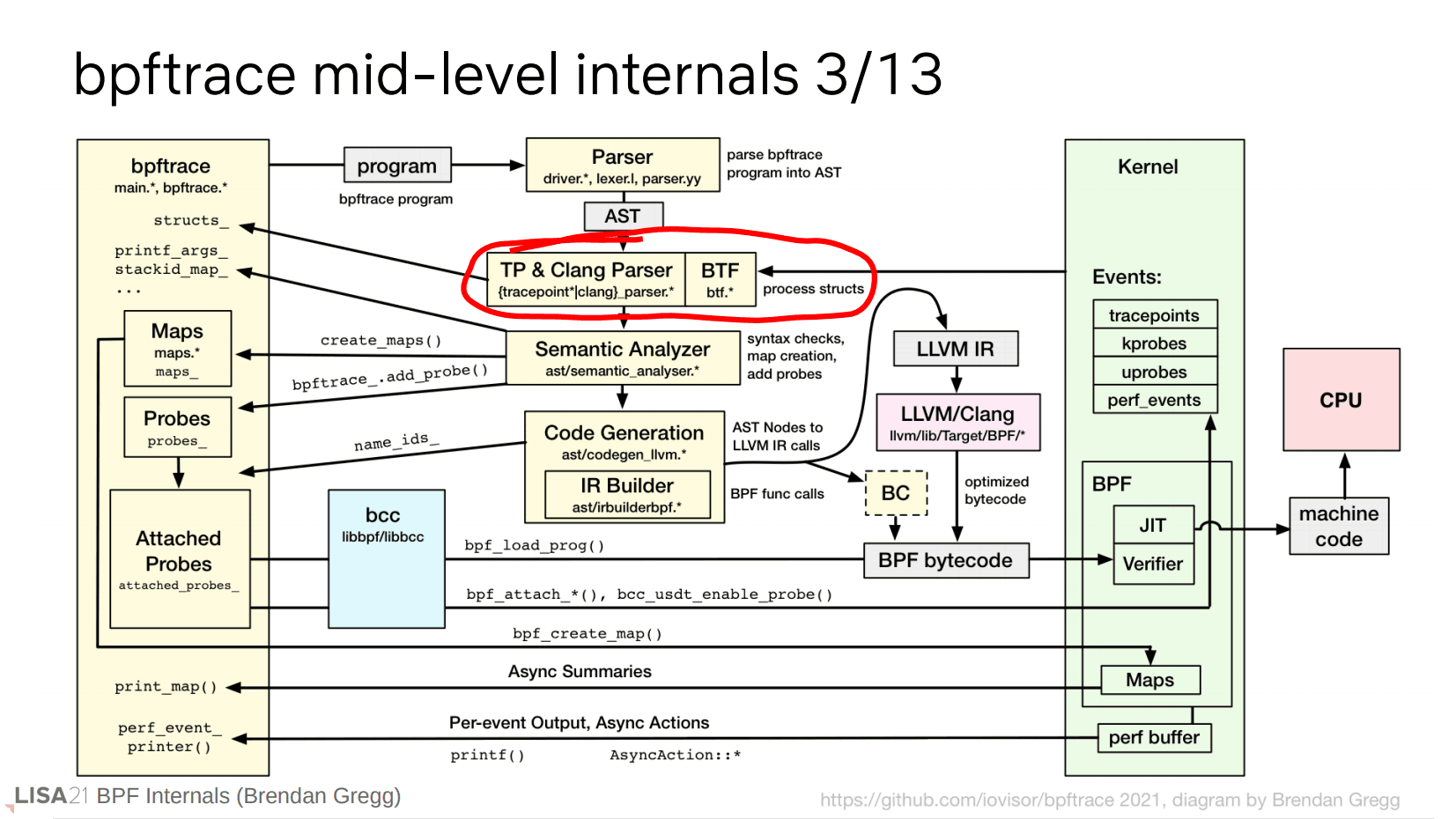
下一步是处理结构体,特别是在内核中,有时你可能会想要遍历结构体,或者是拿到追踪点的参数信息,我们使用 Clang parser 来完成这个过程。这一步将解引用得到正确的内存偏移量。但是我们的 bpftrace 程序没有用到结构体,因此忽略这个过程。
语义分析

再下一步是语义分析。要做的就是检查语法错误,以及调用一些内部函数来创建 map 和 probe。在本例中,分析器检测出了错误的 pidd 输入。
LLVM IR
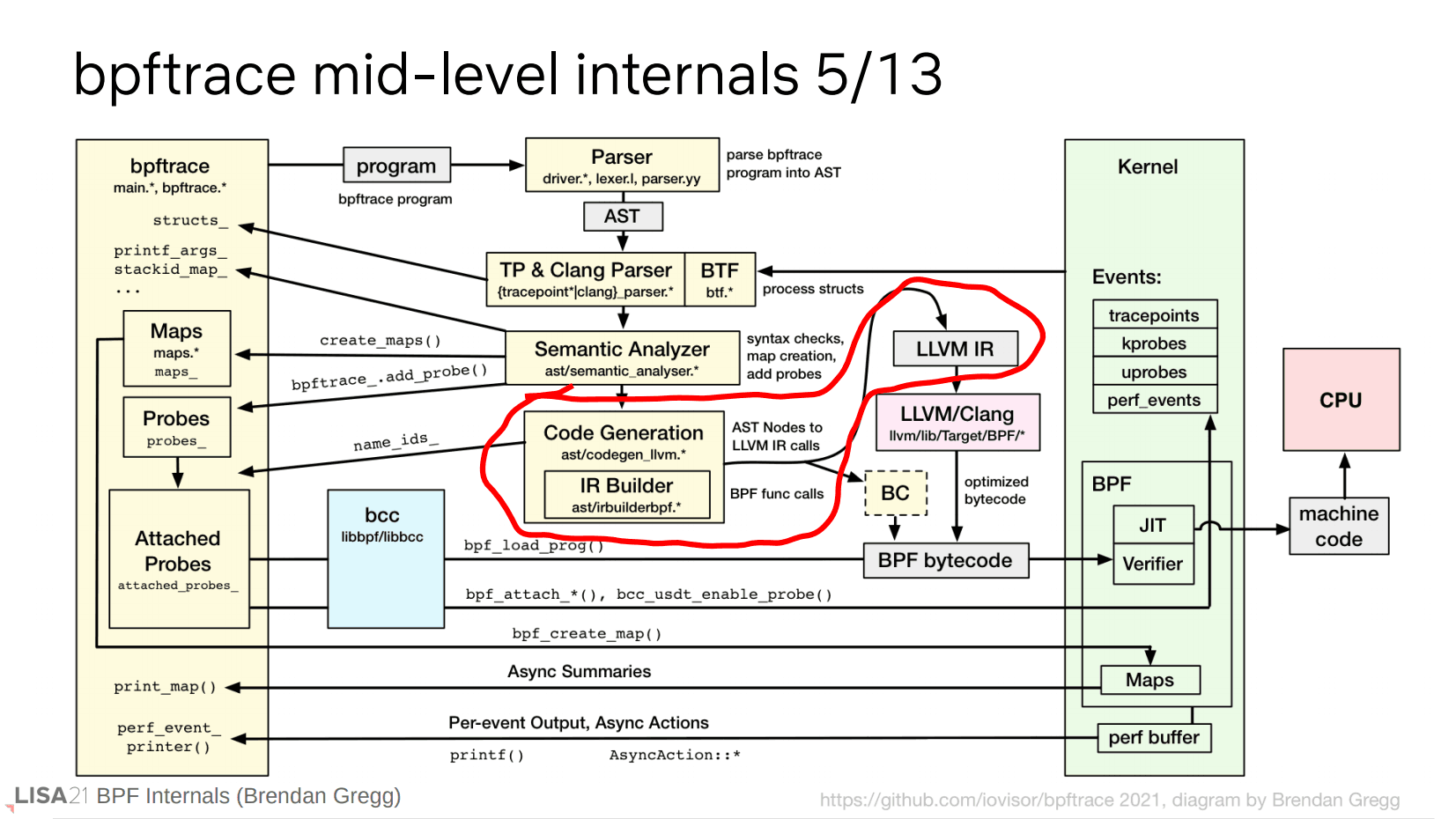
当通过语义分析后意味着有了一个合法(但未通过验证,这部分要生成字节码后再处理)的程序。现在可以接着生成 BPF 字节码,但是我们不是直接生成,而是利用 LLVM 编译器来生成,理由很简单,提供尽可能多的优化。LLVM 也事先支持了 BPF target,所以我们可以先预处理为 LLVM IR,剩下的字节码生成工作就交给 LLVM 完成。



要转换成 IR 就是一个遍历 AST 的过程。这个过程需要依赖于 libbpf,提供一些辅助函数。

遍历完 AST 后,你就能得到 LLVM IR。bpftrace 同样可以通过 -d 查看内部输出。
BPF 字节码
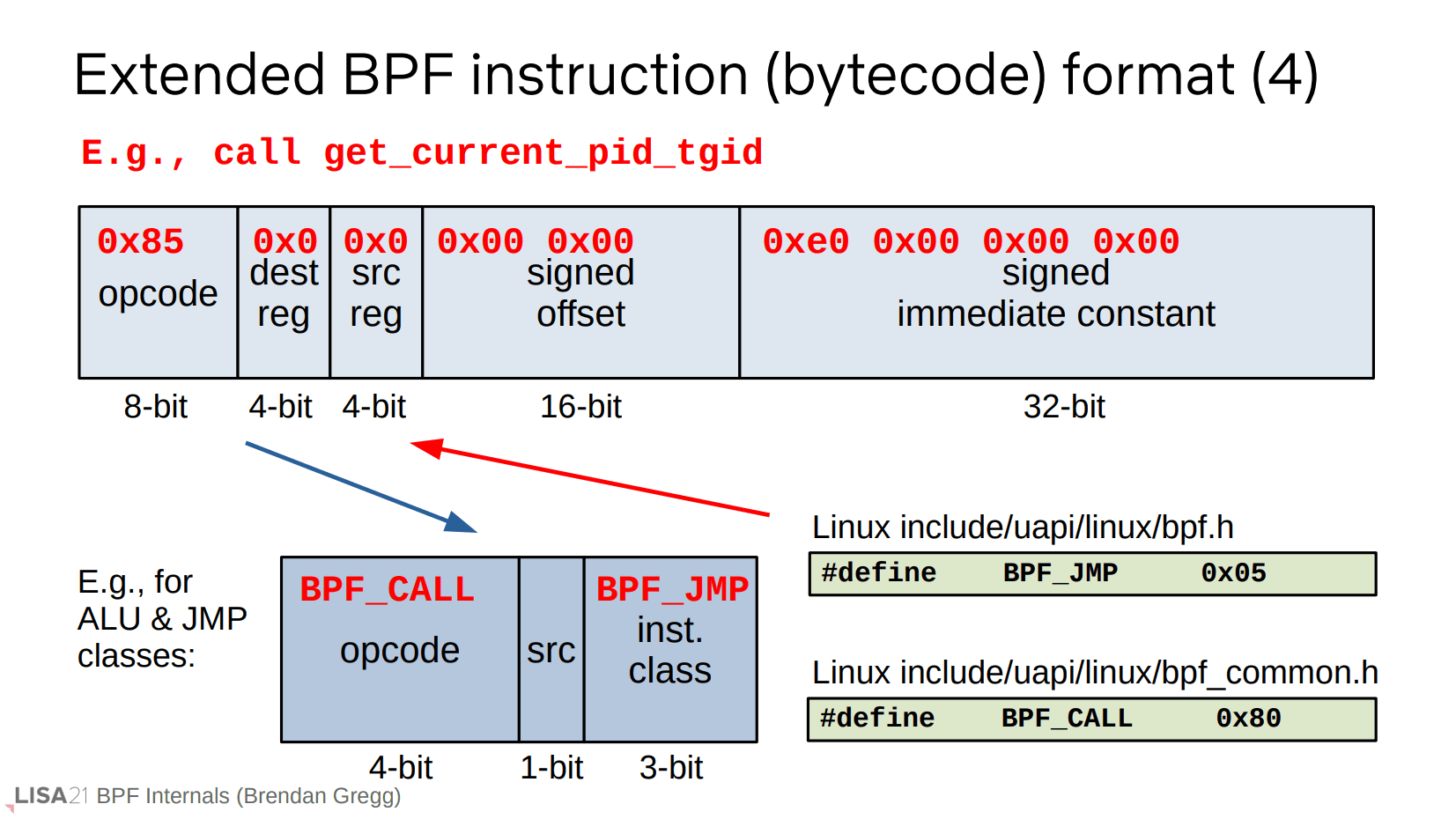
这里补充一下字节码的形式,其定义存放于 Linux 的头文件中。前面也提到了,eBPF 用到的指令宽度是 64 位。上面是一个 call get_current_pid_tgid 的示意图。

番外:BC
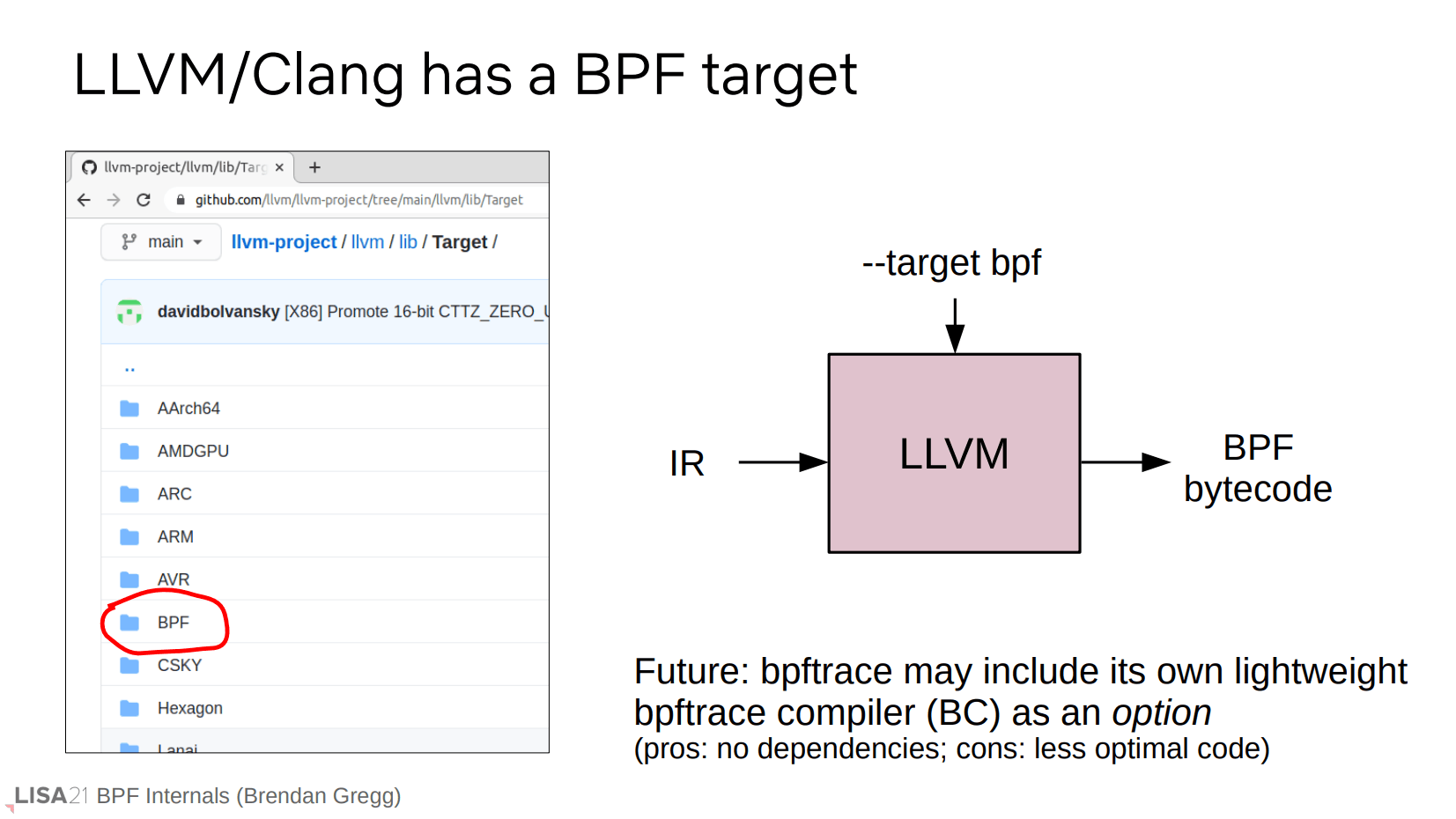
注意前面的流程图还有独立分支 BC,表示无依赖的 bpftrace compiler。这是因为 LLVM 过于庞大,在受限的嵌入式系统中,使用无依赖的编译器也许是更好的选择。缺点是不能得到更多的编译优化。
内核虚拟机
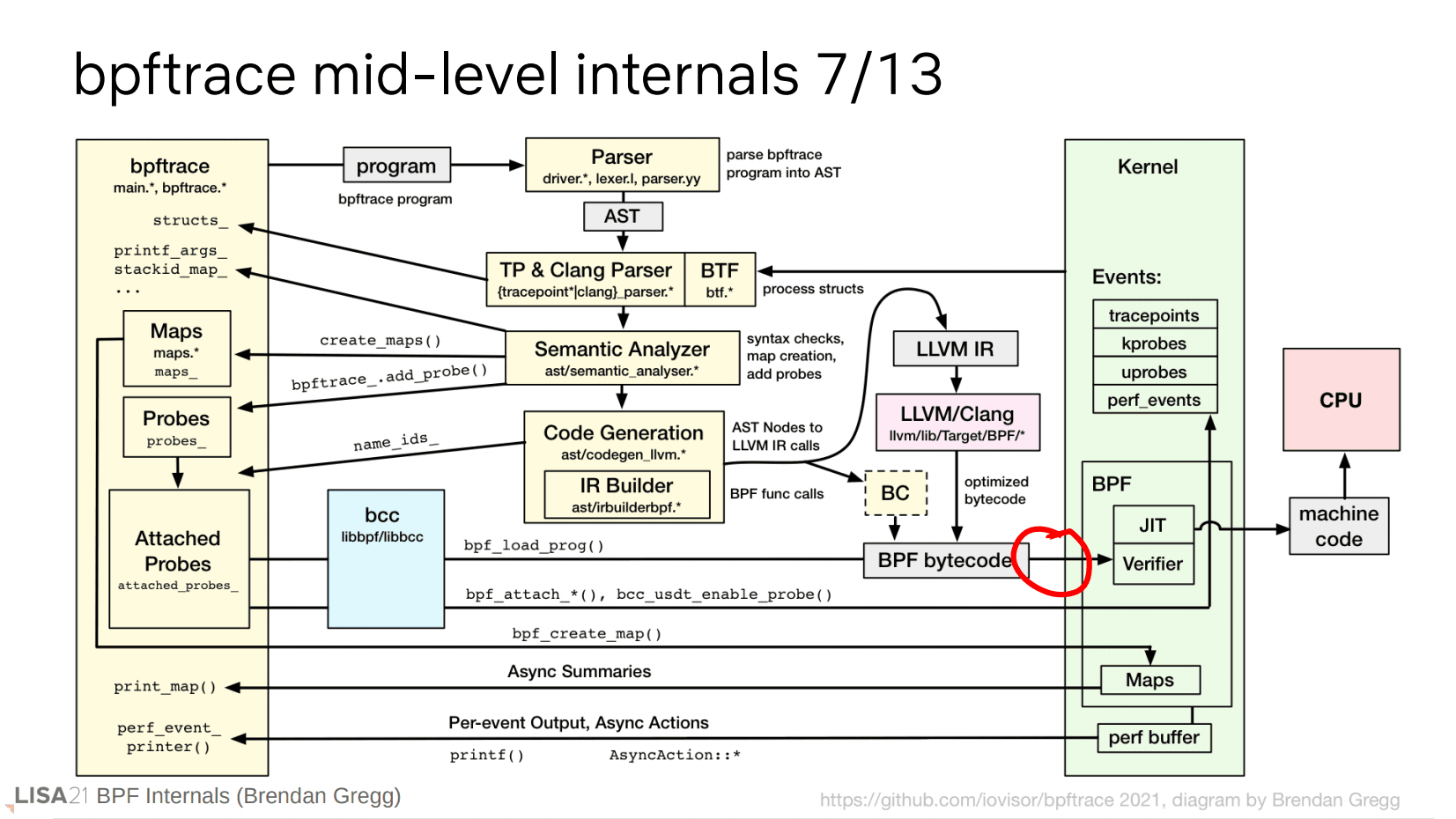
BPF 字节码生成后,就要传递给内核了。
bpf()

我们可以使用 strace 追踪 BPF 字节码的加载过程,简单来说这是一个 bpf() 系统调用。
BPF 内部
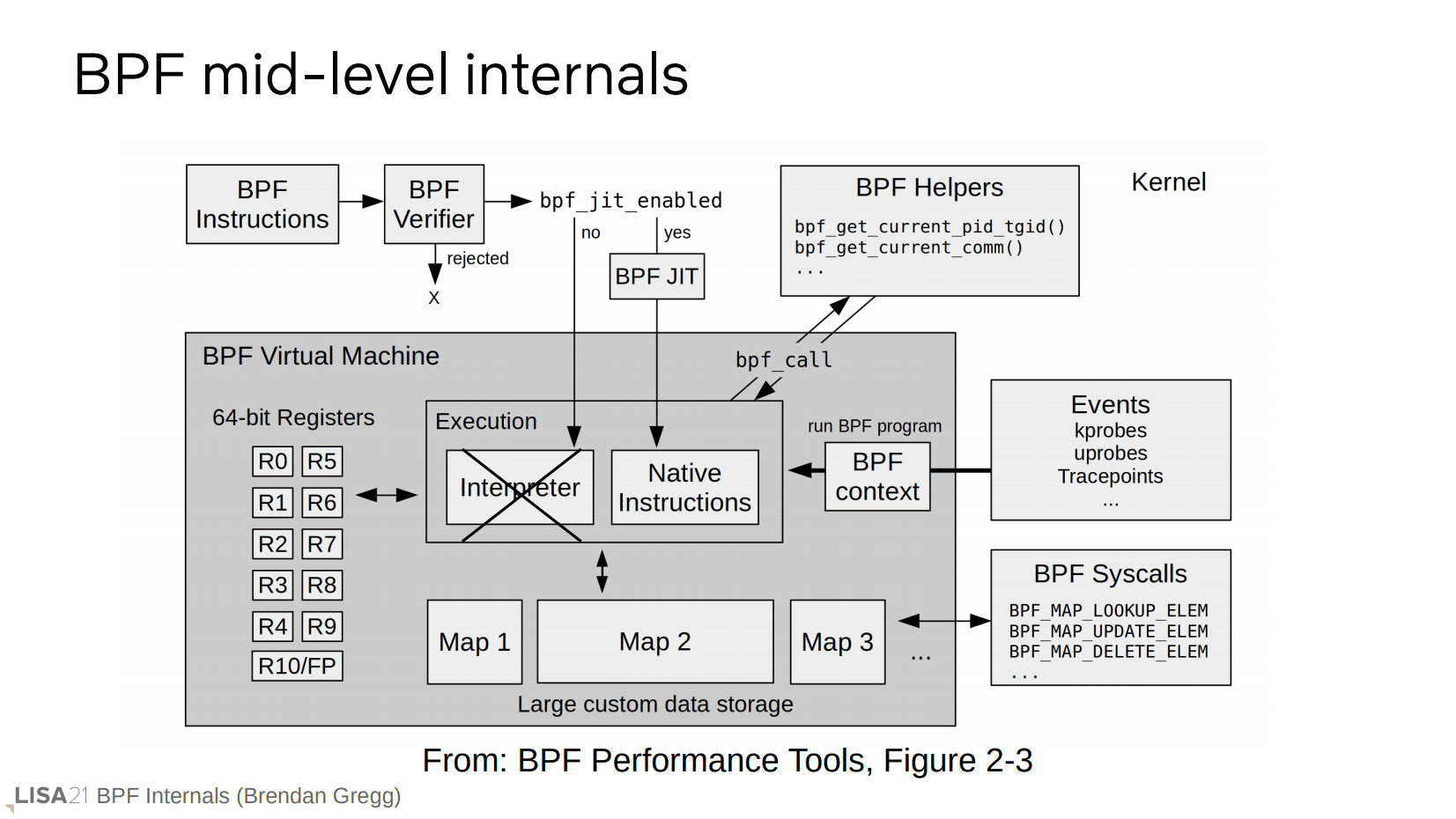
当字节码传递给内核时,工作流程如上所示。先是验证器确认,通过后可能经过 BPF JIT 来生成机器码(否则使用内核内置的解释器,但是新版的内核已经不再使用解释器)。鼓励使用 JIT 的理由是,它不仅更快,而且更安全。(只需在 JIT 侧修改代码就能解决漏洞?)
验证器

简单看一下验证器要验证什么。这是一个伪造的错误 BPF 指令,验证器在这里通过验证函数 ID 的范围来判断是否合法。

实际上验证器的工作非常繁琐,总之它要验证你的程序对于内核来说是无害的。
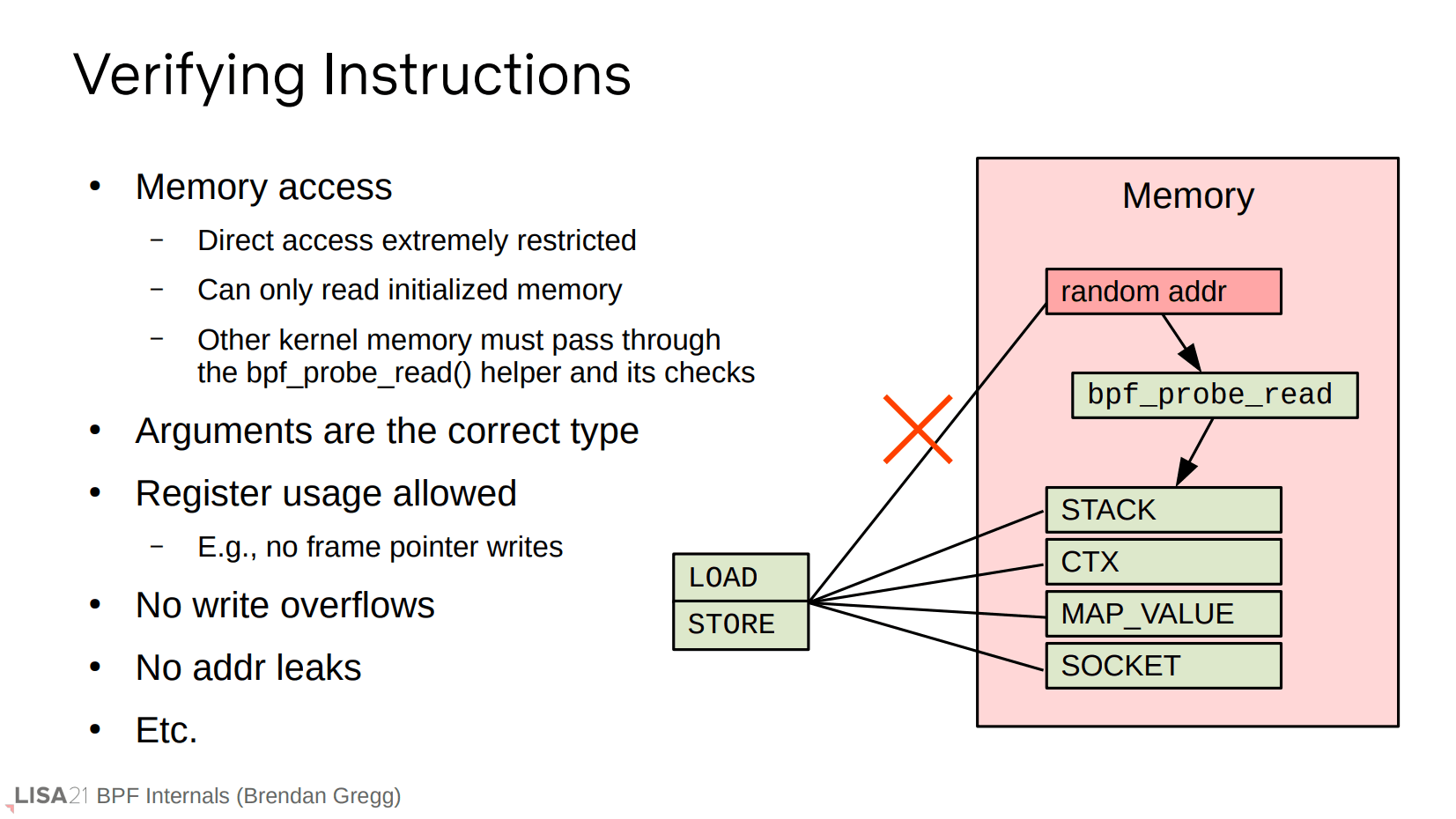
验证指令通常是指内存读写范围是否合法。如果需要读取磁盘、TCP 或者 task struct 信息,这种潜在的不安全行为则需要使用辅助函数 bpf_probe_read(),该函数会提供额外的安全检测,以确保内存访问是合法的。NOTE: man 手册建议使用 bpf_probe_read_user() 和 bpf_probe_read_kernel()。
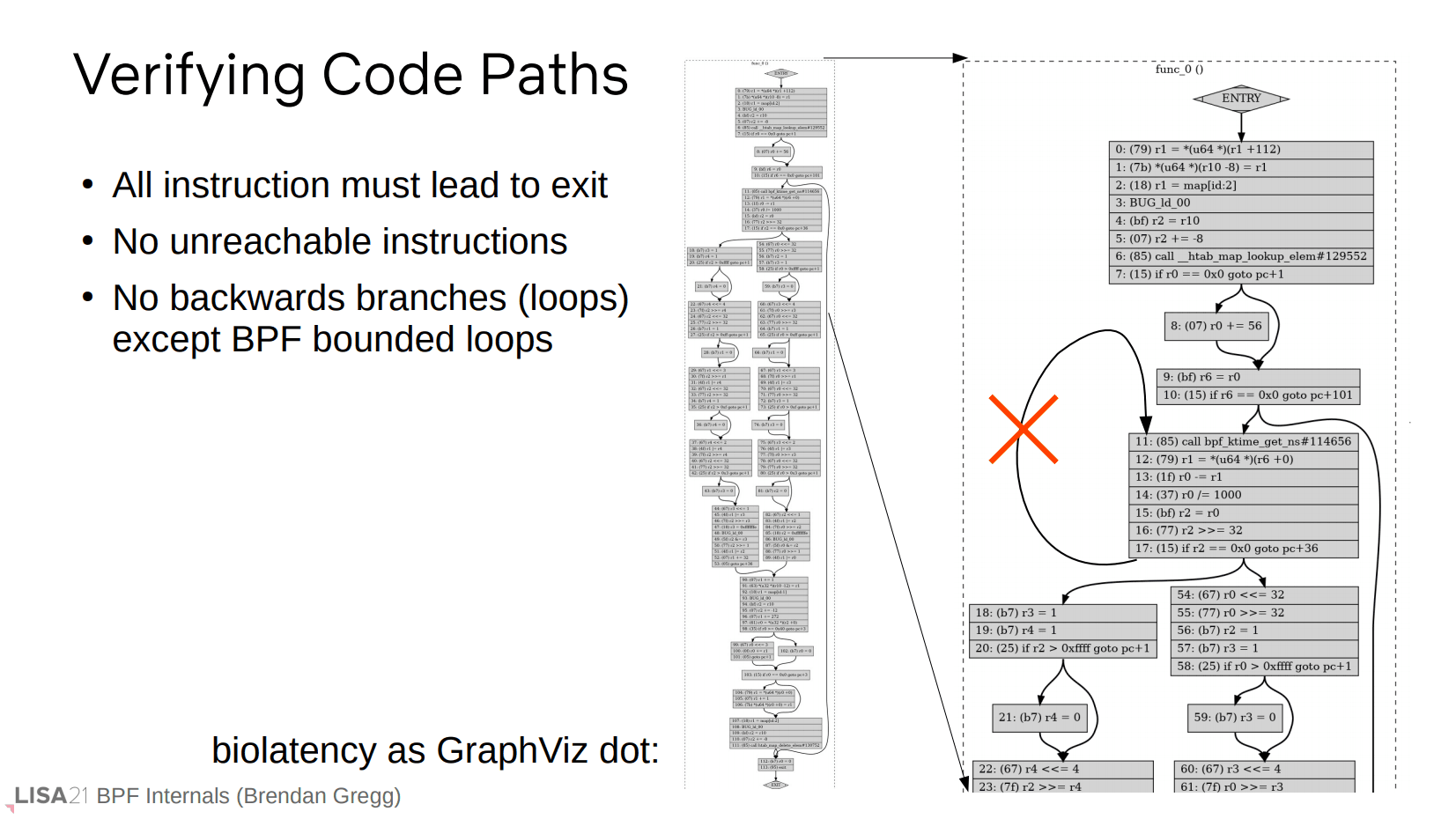
验证路径通常指你的代码路径必须是有限(可达)的,比如不允许无限循环,也不允许往回跳转。
字节码翻译
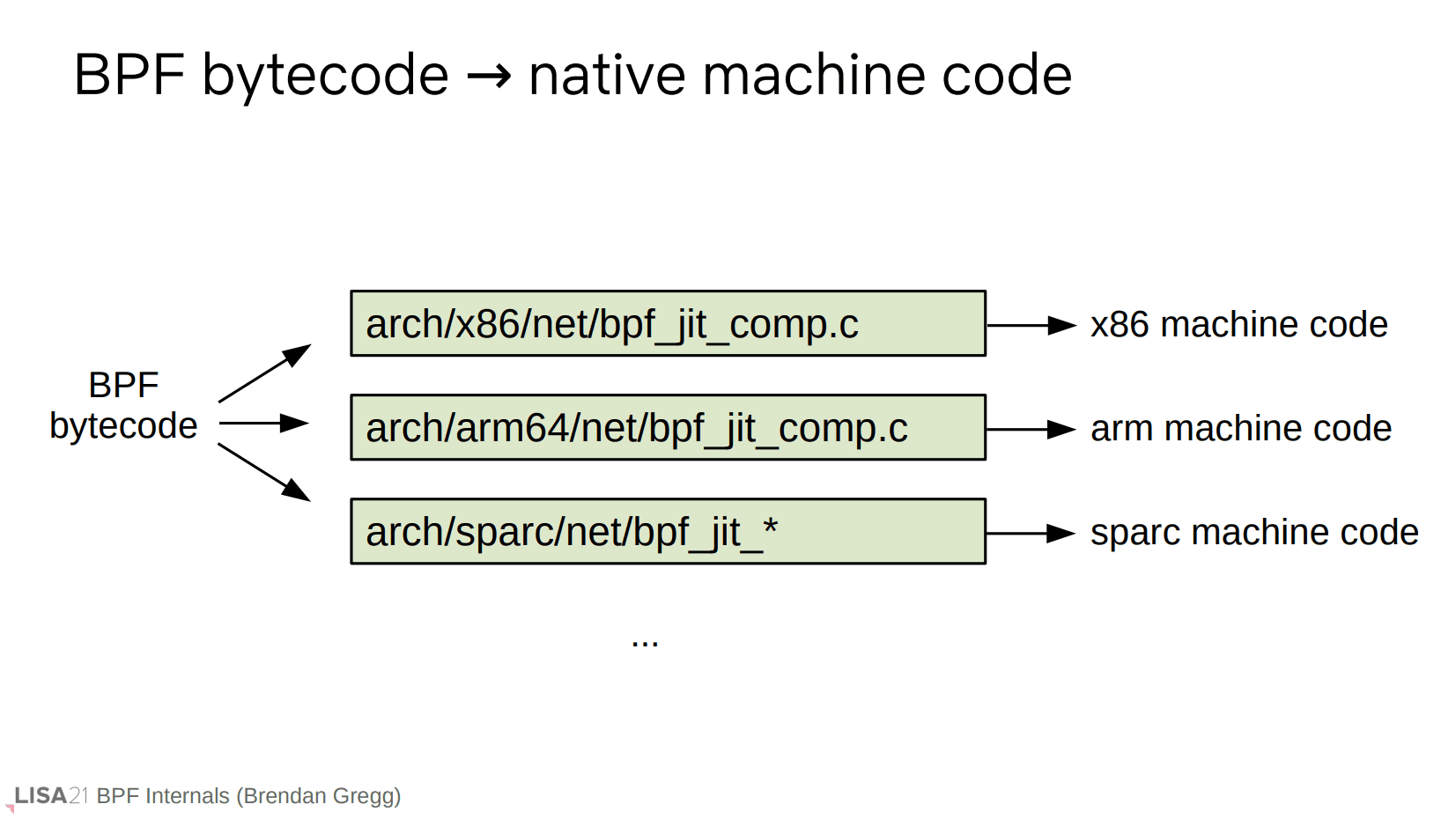
验证完成后,下一步就是字节码翻译成机器码。这些代码分布在内核对应的 arch/ 目录下。


以 x86 机器码为例,这里的翻译流程就是一个迭代所有 BPF 字节码并做映射的过程。示例中使用的 call 字节码指令被翻译成 0xe8,也就是 x86 对应的 call 指令。

同样可以使用 bpftool 提供人类可读的反汇编。
BPF 辅助函数

顺便提一下,我们所看到的并不是 BPF 程序的全部,还有 BPF 辅助函数。这是内核中已存在的函数。
事件的附着
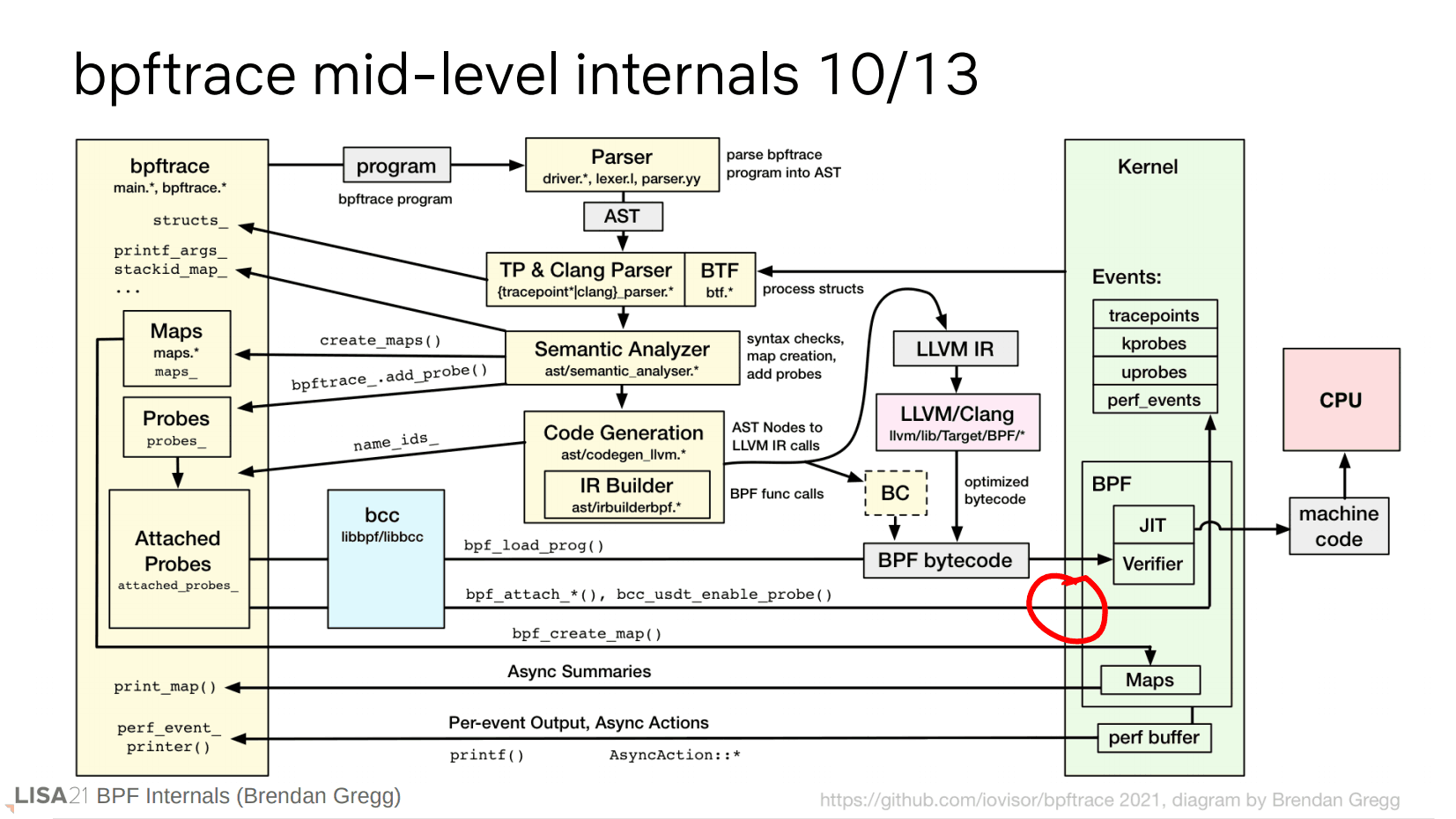
接下来我们来看一个 BPF 程序是如何附着到某些事件上的。
系统调用
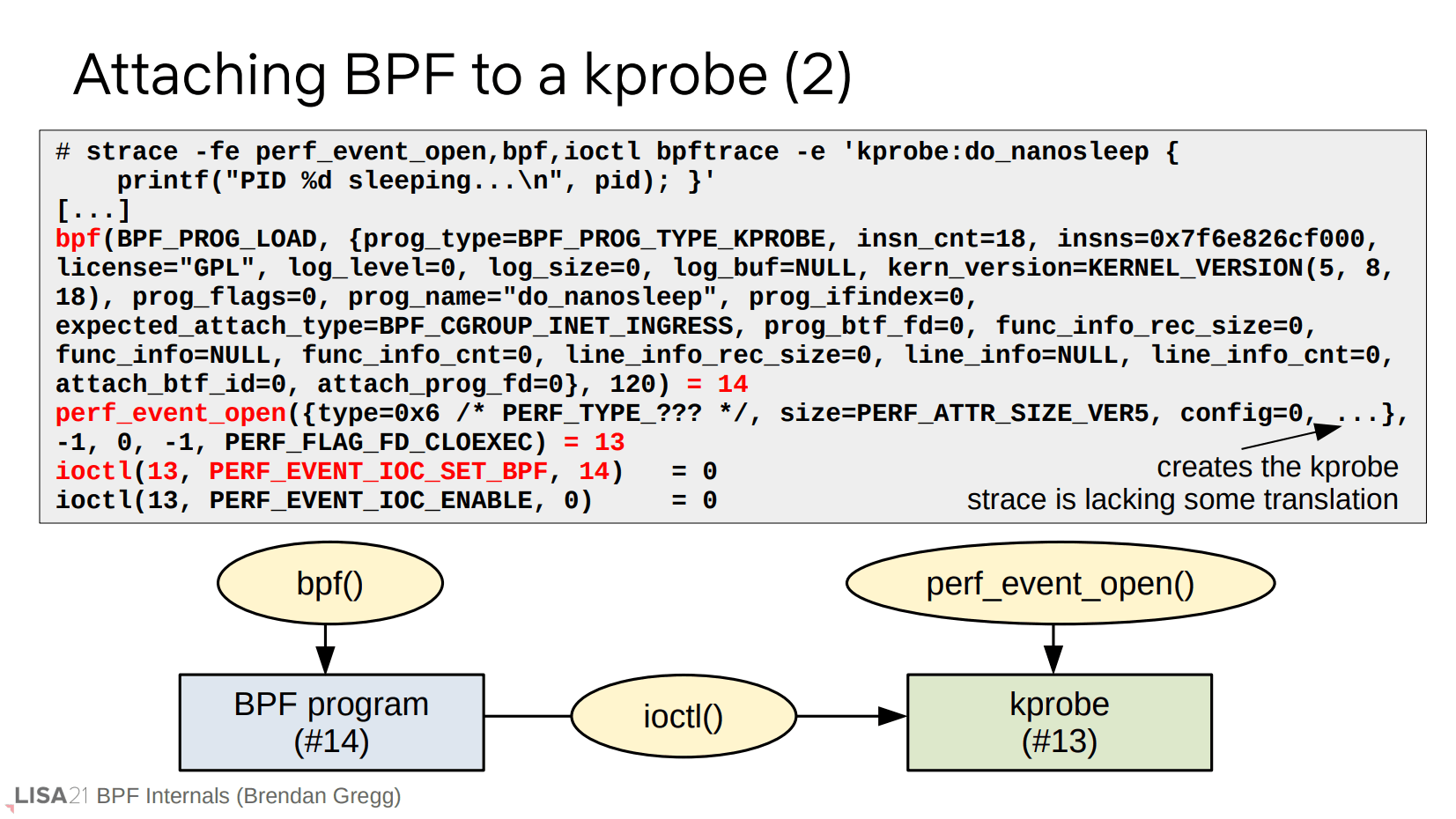
此前我们的 BPF 字节码成功加载,并且 bpf() 系统调用返回了 14,这是一个代表 BPF 程序的文件描述符。然后为创建 kprobe 而使用了 perf_event_open() 系统调用,并且返回了 13,这是一个代表对应已初始化的 kprobe 的文件描述符。再使用 ioctl() 来关联上这两个文件描述符。这就是一个整体的流程。
kprobe 实现

那么问题来了,kprobe 是怎么工作的?怎样让内核在调用函数时就触发探测点呢?

其实挺简单。上面是用 gdb 得到的 do_nanosleep 反汇编,注意到 __fentry__,这是一个 ftrace 函数。ftrace 是内核的另一种追踪器机制,我们在每个函数的开始处调用 fentry。但是并没有被实际调用到,因为这个 call 指令通常是在内核启动时就替换成一个 nop 操作,在需要时(ftrace 使能)再替换回 fentry。BPF/kprobe 利用了 ftrace 优化,只需将处理例程添加到 fentry 上即可。
tracepoint 实现

前面讨论的 kprobe 是一种动态追踪手段。这次我们使用不同的静态追踪手段:tracepoint。


与 kprobe 的工作方式不同,tracepoint 是集成在内核源代码中。这是上面示例的 block_rq_issue 事件,跟踪点需要提前定义在对应的头文件中。
tracepoint 是一种(尽最大努力)稳定的接口,所以我们倾向于使用 tracepoint 事件而不是 kprobe 具体的函数,前者能保证你的工具在数年内仍可工作,后者可能很快在后续内核版本就被改动。
但是并不是所有的函数都有预设的 tracepoint 事件,所以我们也会使用 kprobe 来覆盖这些场景。

我们如何在不增加开销的情况下将它们添加到内核中?实际上这非常容易。编译时,它会留下一条五字节长度的 nop 指令,除了占位什么都不做。当 tracepoint 使能时,这将被重写为 jmp 指令作为一个跳板,然后当你停止使用时,它又会被重写回 nop 指令。
数据的交互
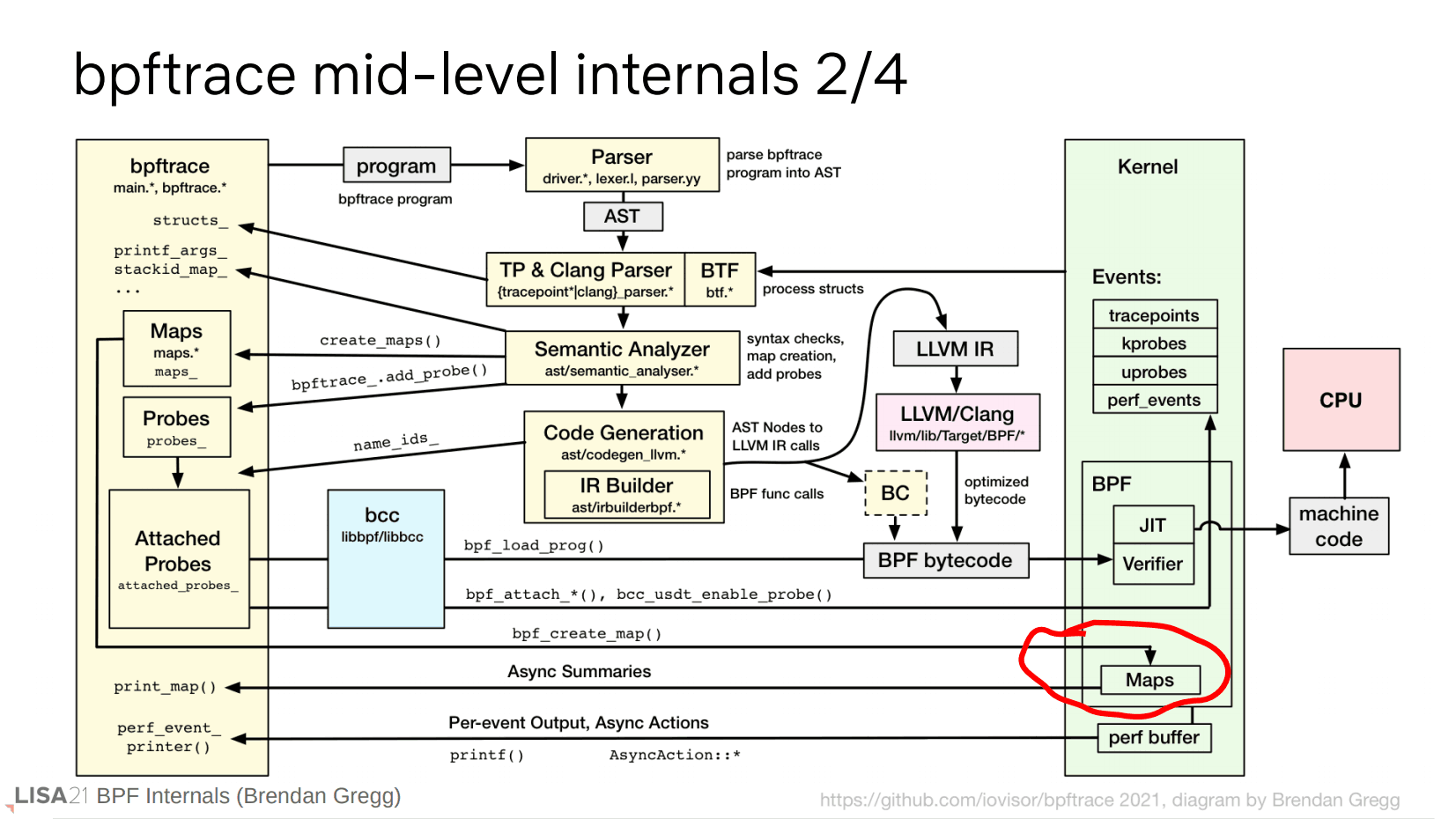
剩下的部分主要是数据的汇总和输出。
输出缓冲区
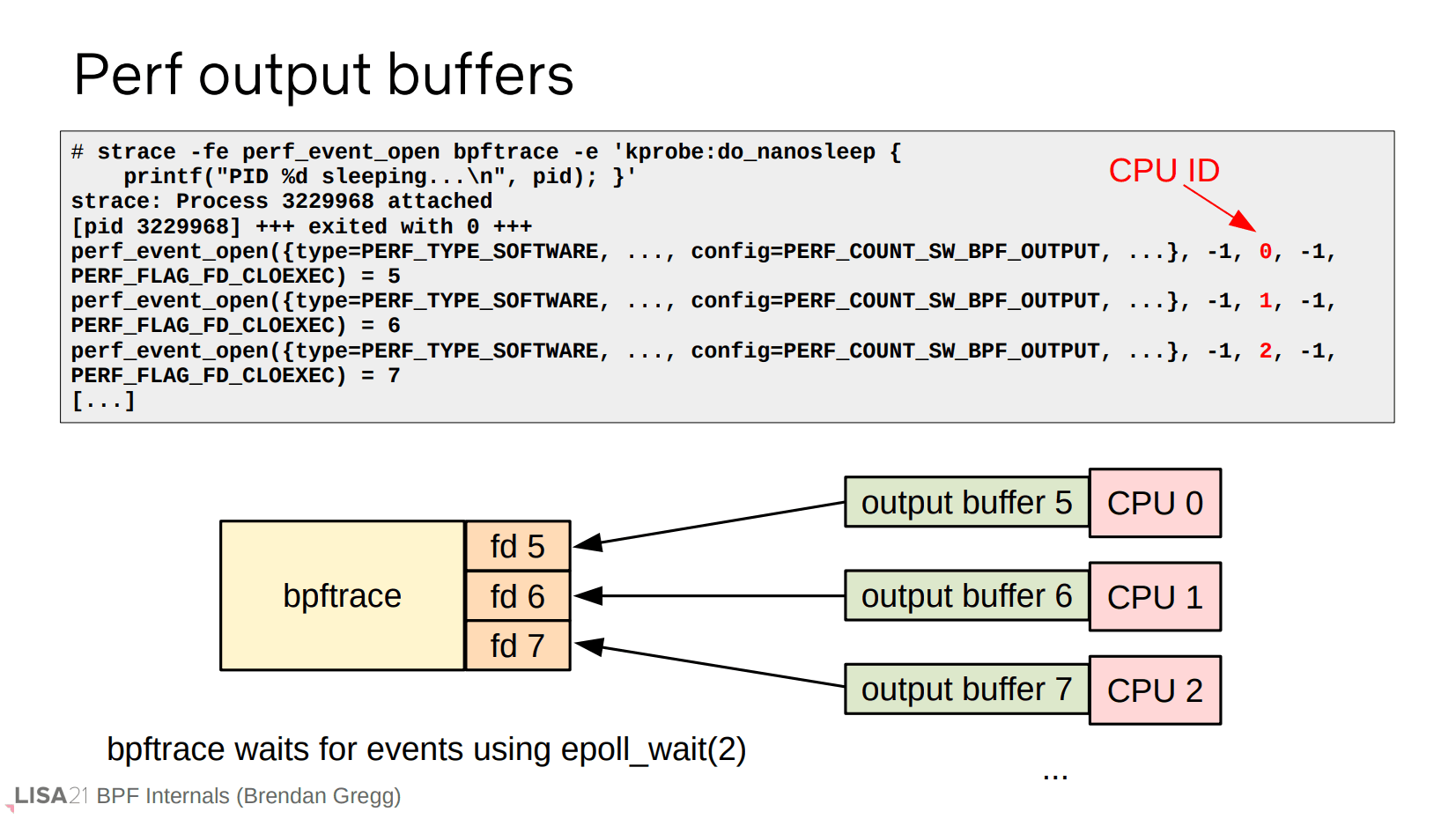
printf() 使用到的 perf buffer,大意是多个 per-CPU 的缓冲区(每个缓冲区对应一个文件描述符),然后用户空间通过 epoll_wait() 去收集,因此得到的数据可以是乱序的,需要自己排序处理。
NOTE: 社区提供了共享的 ring buffer 来解决乱序问题,这已经不是演讲范围内的内容。
map

前面的 tracepoint 例子中使用了 @,这定义了一个 map。

这就是 map 在 parser 上的定义。它可以有变量参数,也可以有一个或者多个的 key。
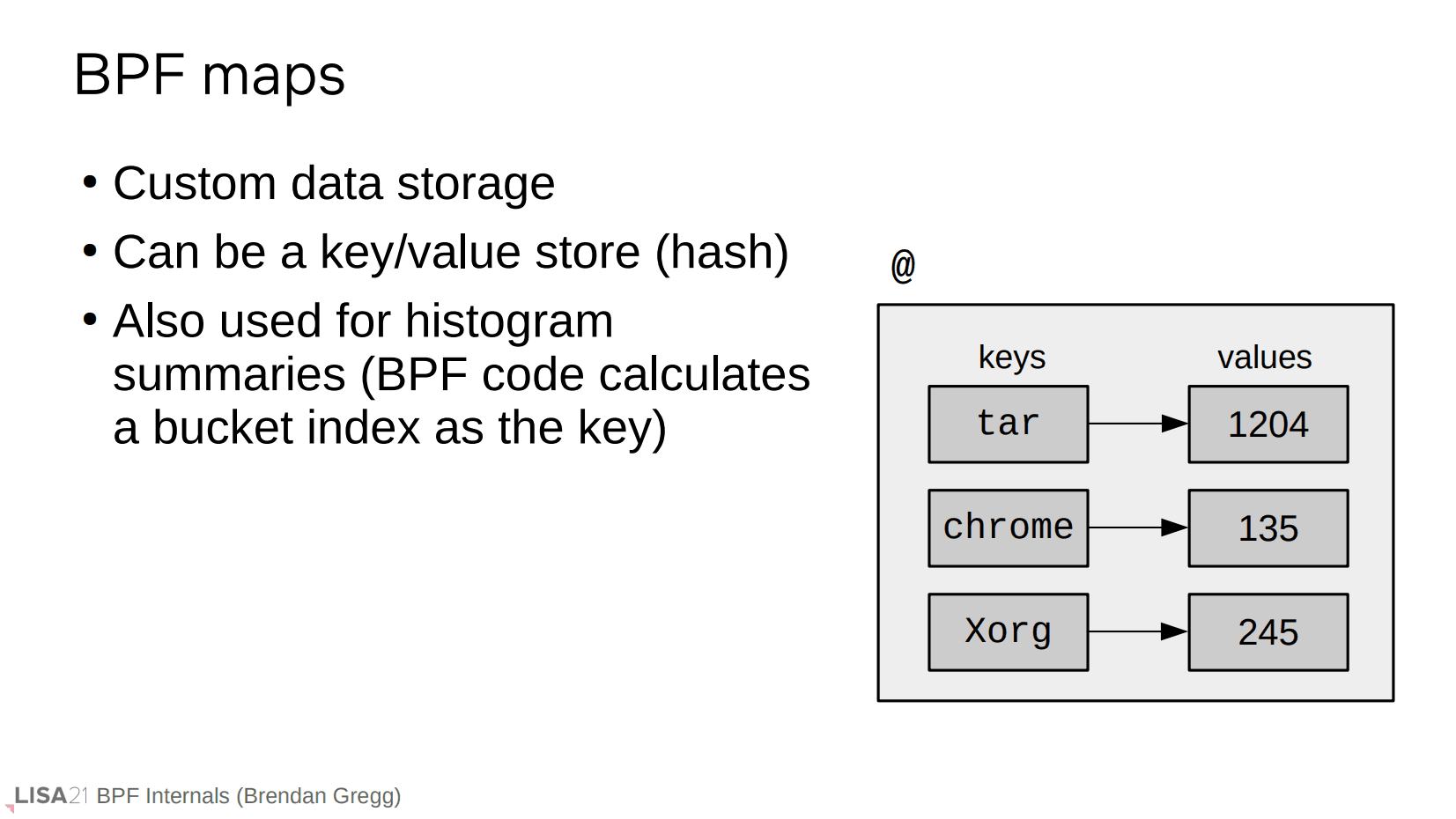
map 本身有多种类型,常用的就是 key/value hash 形式作为一个汇总输出。


map 可以从用户空间使用 bpf() 系统调用创建,并且在内核空间也有 BPF 辅助函数进行操作。
通过 strace 会发现 tracepoint 例子中使用的是一个 per-CPU hash 类型的 map。

需要注意的是,遍历 map 会产生大量 bpf() 系统调用,因此会有较高的开销。但是这个程序中只有退出时才一次性输出,因此是没问题的。

经过上面讨论的一系列流程,我们得到了最终的结果。