这篇文章用来分享我早段时间随便搞出来的协程轮子,实现放在 github 了:co
我本不想写这篇文章,看代码 (RTFSC) 就很足够了
我认为技术分享不是问题,但是现在没啥好分享还非要我分享,我觉得这公司很有问题
写都写了,那还是无责任放出来吧,内容质量我不管
随便指的是轮子本身造的简单,而不是说我写 bug 很随便
什么是协程
可以认为是用户态的线程,但是上下文切换的时机是靠调用方自身去控制
其控制上下文的原语有:resume 恢复和 yield 让出
从表面上来说,就好像一个函数的控制流可以随意分拆一样,即单个线程也能做到并发
void print1() {
std::cout << 1 << std::endl;
co::this_coroutine::yield();
std::cout << 2 << std::endl;
}
void print2(int i, co::Coroutine *co1) {
std::cout << i << std::endl;
co1->resume();
std::cout << "bye" << std::endl;
}
int main() {
auto &env = co::open();
auto co1 = env.createCoroutine(print1);
auto co2 = env.createCoroutine(print2, 3, co1.get());
co1->resume();
co2->resume();
return 0;
}
输出结果:
1
3
2
bye
也就是说,协程可以使得一个函数可以在任意调用处返回,并且恢复后从原来的返回处继续往下执行
严格上说,协程版本很多,比如无栈协程、有栈协程、共享栈协程,还有对称式和非对称式协程等等,这里只考虑有栈协程且为非对称式协程
别问为什么,问就是简单
为什么用协程
调度和时间片:这种切换对于内核来说是不可感知的,因此不会被 task 调度所影响,从内核的角度来看你的时间片永远是充分利用的。并且切换时机由自己控制,调度的时机相比内核的猜测会更加符合实际场合
粒度:并且协程一般是契合实际应用场合去控制上下文的粒度:比如你不需要任何浮点计算,那么可以不考虑浮点寄存器的保存和恢复。上下文的成本低了,性能就上来了
实际收益:在一些 IO 密集型的场合中,使用协程相比传统线程可以提高 800% 的性能(根据虎牙 libgo 跑分)
再简单点说,就是 performance
前置技能:汇编
PS. 为了简单,协程的实现不考虑跨平台,只考虑:
- Linux
- x86 64
汇编要看什么
实现协程绕不过汇编,当然这不需要学习汇编的全部内容
我认为在实现过程中了解以下部分就足够了:
- 栈维护的过程
- 函数调用约定(传递参数时用的寄存器)
- 控制流维护的简单原理(
caller和callee维护的返回地址以及rip寄存器) - 还有一些 ABI 上的细节
其中第一到第三点都是组合搭配的
调试
实现过程中可以用 gdb 来逐步指令级调试(注意要指令级别)
通常用这几个命令就够了
| 命令 | 说明 |
|---|---|
disassemble
| 查看当前执行指令 |
ni
| 指令级别的 next |
si
| 指令级别的 step |
info registers
| 查看当前寄存器状态 |
下面的汇编层面展示会用到 godbolt.org
这是一个很不错的编译器调试网站,所见即所得
栈
首先说一下栈的维护,有以下简单规则:
- 栈依靠两个寄存器去控制,即
rbp和rsp,它们指向进程的虚拟地址 - 但是用指令的时候不是直接去控制以上两个寄存器,可以用
push和pop指令 - 栈的使用是从高地址到低地址
- 栈寄存器通常指向程序的栈区,但是在协程实现时,我们这里会伪造”栈“
汇编结果如下
代码层面:

指令层面:

对于栈的使用
可以看以下每个函数的规律:每一段函数开始时,都会声明:
push %rbpmov %rsp, %rbp
这就是一个栈的维护
其中,push <any> 操作相当于:
sub $8, %rspmov <any>, (%rsp)
而 pop <any> 操作则相反
在复杂的嵌套场合中(比如 foo,里面还需要进一步调用 bar)
可能还会有 sub $<immediate>, %rsp 以及 leave
前者为了保护当前栈帧的信息,后者则相当于 8-10 行的反操作
不过这个在协程实现中不太重要,因为 callee 汇编代码要怎么写,我们自己可以控制
只是后面返回地址的保存也用到了栈,因此需要了解
参数传递
前面为了简单,函数都不接收参数
但是实现协程总得需要传递参数,就像函数一样
那么当调用一个函数时,到底怎样才能把传参传递给对应的函数?(callee 怎么从 caller 里拿数据?)
其实这个不看 ABI 文档的话,debug 一下也很容易知道
比如从这里扒一段代码
#include <cstdint>
int64_t f(int p1, int p2, int p3, int p4, int p5, int p6, int p7, int p8)
{
int x = 0;
int y = 0;
int64_t z = 0;
int64_t l = 0;
x++;
p1++;
p7++;
p8++;
return 0;
}
int main()
{
int64_t i = 0;
i++;
i = f(1, 2, 3, 4, 5, 6, 7, 8);
return 0;
}
放到 godbolt 去编
代码层面:

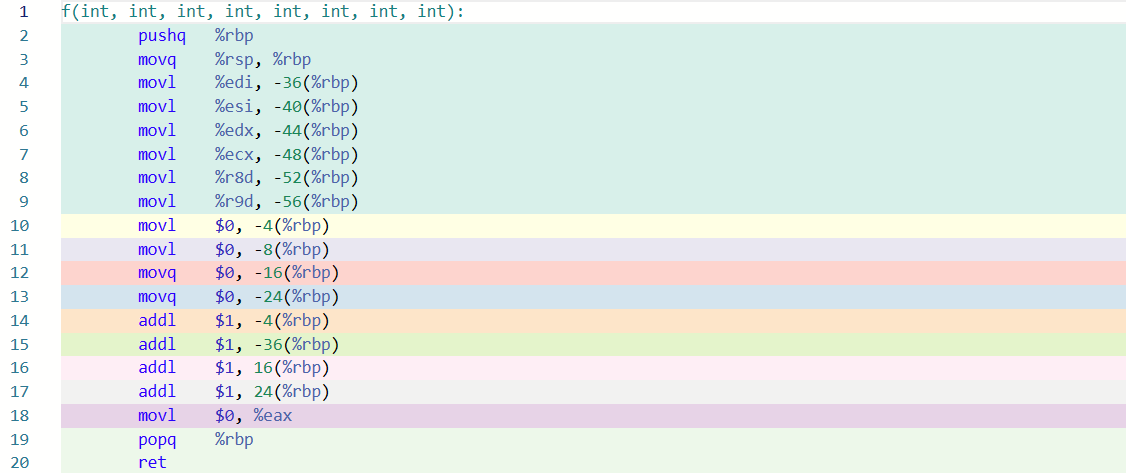
f 部分:
main 部分:
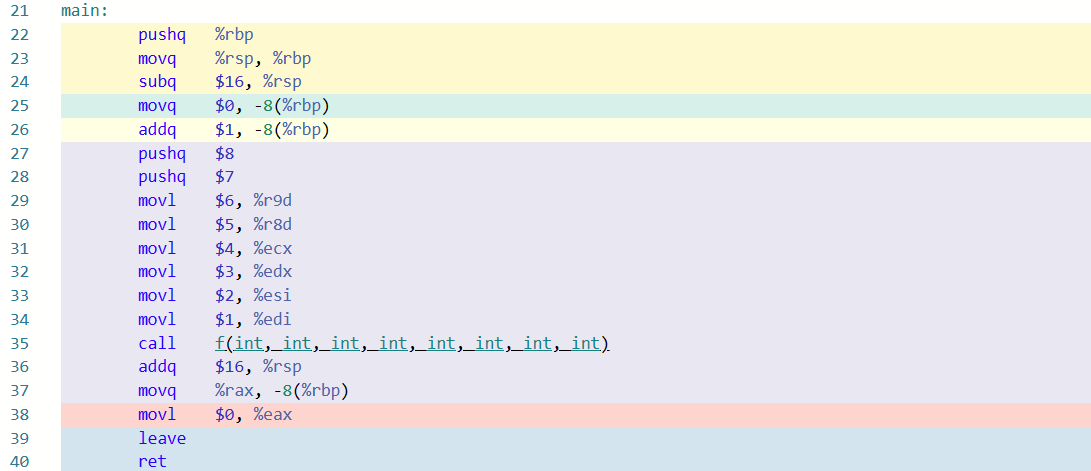
这里注重看 main 部分的 27 到 38 行:
- 第一个参数放
%rdi(34 行,把数值$1放到edi) - 第二个参数放
%rsi(33 行) - 第三个参数放
%rdx - 第四个参数放
%rcx - 第五个参数放
%r8d - 第六个参数放
%r9d - 超出部分通过栈来维护,并且是倒着放的(27-28 行),完成后需要恢复栈指针(36 行,
add $16, %rsp,相当于把 27-28 行占坑的部分pop出来) - 返回值(
f函数return的部分)约定是放在%rax,因此 37 行相当于完成了代码中i = f(...)获取结果的部分(int i位于-8(%rbp))
而到了 f 部分的指令,则按照约定依次从各个寄存器(以及栈)中拿出参数,完成传递过程
在后面的实现环节中,我们最多只用到 2 个传参,其它任意长的参数传递通过套一个中间层去绕过
因此只考虑 %rdi 和 %rsi
函数调用
通常调用一个函数就是用的 call 指令,后面紧跟着需要调用的函数地址
哪怕你写一个再简单不过的函数

也会有这样的代码

2-5 / 8-9 / 11-12 行前面解释了是栈的维护过程
剩下的就是第 6 行的 ret 和第 10 行的 call
可以看出,这是一个搭配使用:
caller要调用函数,则使用callcallee要返回函数,则使用ret
那么这 2 个指令到底又干了什么事情?
这其实就是操作控制流,即 %rip 寄存器
call <函数调用地址> 指令可认为是:
push %ripjmp <函数调用地址>
此时
%rip指向当前 call 代码地址的下一行
而搭配的 ret 则是反操作:
pop %rip
这里又用到了栈,而且有最为关键的返回地址
后面的实现,就是要把返回地址给无意识地换掉,达成切换的效果
协程实现
具体代码见:Caturra000/co: 协程库,实现跟名字一样很短 (github.com)
主要参考对象是微信 libco
创建环境
这里的协程实现不支持跨线程,因此是每个线程分配一个环境
用于维护该线程下运行中的协程之间的层次关系
class Environment {
public:
// per-thread 的单例
static Environment& instance();
// 创建协程 (co::Coroutine) 的简单工厂
template <typename Entry, typename ...Args>
std::shared_ptr<Coroutine> createCoroutine(Entry &&entry, Args &&...arguments);
// 当前线程中正在执行的协程
Coroutine* current();
Environment(const Environment&) = delete;
Environment& operator=(const Environment&) = delete;
private:
// 协程压栈和弹栈操作
void push(std::shared_ptr<Coroutine> coroutine);
void pop();
Environment();
private:
// 每个环境最多允许 1024 层协程嵌套
std::array<std::shared_ptr<Coroutine>, 1024> _cStack;
// 当前的栈顶下标
size_t _cStackTop;
// 垫底用的主协程,其实没啥用
std::shared_ptr<Coroutine> _main;
};
协程实例
协程的实例主要用于支持接口 resume 和 yield
class Coroutine: public std::enable_shared_from_this<Coroutine> {
public:
static Coroutine& current();
// 测试当前控制流是否位于协程上下文
static bool test();
// 获取当前运行时信息
const State runtime() const;
bool exit() const;
bool running() const;
// 核心操作:resume 和 yield
static void yield();
const State resume();
Coroutine(const Coroutine&) = delete;
Coroutine(Coroutine&&) = delete;
Coroutine& operator=(const Coroutine&) = delete;
Coroutine& operator=(Coroutine&&) = delete;
// 由于用到 std::make_shared,必须公开这个构造函数
public:
template <typename Entry, typename ...Args>
Coroutine(Environment *master, Entry entry, Args ...arguments)
: _entry([=] { entry(/*std::move*/(arguments)...); }),
_master(master) {}
private:
static void callWhenFinish(Coroutine *coroutine);
private:
State _runtime {};
Context _context;
std::function<void()> _entry;
Environment *_master;
};
void Coroutine::callWhenFinish(Coroutine *coroutine) {
auto &routine = coroutine->_entry;
auto &runtime = coroutine->_runtime;
if(routine) routine();
runtime ^= (State::EXIT | State::RUNNING);
yield();
}
const State Coroutine::resume() {
if(!(_runtime & State::RUNNING)) {
// 填充下一次切换备份的 ret 为 callWhenFinish,rdi 为 this 指针,这里也相当于延迟构造
// callWhenFinish 不能用非静态的成员函数,这涉及到 ABI 的麻烦问题(属于语言细节)
_context.prepare(Coroutine::callWhenFinish, this);
_runtime |= State::RUNNING;
_runtime &= ~State::EXIT;
}
auto previous = _master->current();
_master->push(shared_from_this());
_context.switchFrom(&previous->_context);
return _runtime;
}
void Coroutine::yield() {
auto &coroutine = current();
auto ¤tContext = coroutine._context;
coroutine._master->pop();
auto &previousContext = current()._context;
previousContext.switchFrom(¤tContext);
}
实际干活的是维护上下文信息的 Context
上下文实例
上下文需要确保内存布局准确无误才能使用
一个 context 的起始地址必须是 regs[0],否则会影响后面的协程切换正确性
// low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret |
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
// hig | regs[13]: rsp |
// 协程的上下文,只实现 x86_64
class Context final {
public:
using Callback = void(*)(Coroutine*);
using Word = void*;
constexpr static size_t STACK_SIZE = 1 << 17;
constexpr static size_t RDI = 7;
// constexpr static size_t RSI = 8;
constexpr static size_t RET = 9;
constexpr static size_t RSP = 13;
public:
void prepare(Callback ret, Word rdi);
void switchFrom(Context *previous);
bool test();
private:
Word getSp();
void fillRegisters(Word sp, Callback ret, Word rdi, ...);
private:
// 必须确保 registers 位于内存布局最顶端
// 且不允许 Context 内有任何虚函数实现
// 长度至少为 14
Word _registers[14];
// 伪造的协程栈,实际是分配在堆区(shared_ptr 封装时整块内存都搬到堆上分配)
char _stack[STACK_SIZE];
};
// prepare 用于填充 ret 和 rdi
void Context::prepare(Context::Callback ret, Context::Word rdi) {
Word sp = getSp();
fillRegisters(sp, ret, rdi);
}
void Context::fillRegisters(Word sp, Callback ret, Word rdi, ...) {
::memset(_registers, 0, sizeof _registers);
auto pRet = (Word*)sp;
*pRet = (Word)ret;
_registers[RSP] = sp;
_registers[RET] = *pRet;
_registers[RDI] = rdi;
}
// 获取伪造的 rsp,这里放到伪造栈 `_stack` 的尾部(因为是高地址)
Context::Word Context::getSp() {
auto sp = std::end(_stack) - sizeof(Word);
sp = decltype(sp)(reinterpret_cast<size_t>(sp) & (~0xF));
return sp;
}
// 这里从上面的汇编教程看出,当前运行时寄存器 `%rdi` 值为 `previous` 指针,`%rsi` 为 `this` 指针
// contextSwitch(previous, next) 表示从 previous 上下文切换到 next(即 this) 上下文
void Context::switchFrom(Context *previous) {
contextSwitch(previous, this);
}
切换核心
这一块必须用汇编去实现
主要核心就是一个 switch 过程
// low | regs[0]: r15 |
// | regs[1]: r14 |
// | regs[2]: r13 |
// | regs[3]: r12 |
// | regs[4]: r9 |
// | regs[5]: r8 |
// | regs[6]: rbp |
// | regs[7]: rdi |
// | regs[8]: rsi |
// | regs[9]: ret |
// | regs[10]: rdx |
// | regs[11]: rcx |
// | regs[12]: rbx |
// hig | regs[13]: rsp |
这里 rax 不作为返回值使用,而是作为 ret 返回地址的临时存储
rsp 记录的是伪造栈尾部的地址,rax 存的是 callWhenFinish 的地址,因此记为 ret
.globl contextSwitch
.type contextSwitch, @function
contextSwitch:
movq %rsp, %rax
movq %rax, 104(%rdi)
movq %rbx, 96(%rdi)
movq %rcx, 88(%rdi)
movq %rdx, 80(%rdi)
movq 0(%rax), %rax
movq %rax, 72(%rdi)
movq %rsi, 64(%rdi)
movq %rdi, 56(%rdi)
movq %rbp, 48(%rdi)
movq %r8, 40(%rdi)
movq %r9, 32(%rdi)
movq %r12, 24(%rdi)
movq %r13, 16(%rdi)
movq %r14, 8(%rdi)
movq %r15, (%rdi)
xorq %rax, %rax
movq 48(%rsi), %rbp
movq 104(%rsi), %rsp
movq (%rsi), %r15
movq 8(%rsi), %r14
movq 16(%rsi), %r13
movq 24(%rsi), %r12
movq 32(%rsi), %r9
movq 40(%rsi), %r8
movq 56(%rsi), %rdi
movq 80(%rsi), %rdx
movq 88(%rsi), %rcx
movq 96(%rsi), %rbx
addq $8, %rsp
pushq 72(%rsi)
movq 64(%rsi), %rsi
ret
这里调用时 rdi(previous)和 rsi(next)分别指向 Context 实例的地址
首先是保存当前的寄存器上下文到 previous 的_registers 中:
- 真实的
rsp存放到 previous 的 104 中(13*8,可能是位于栈区的 rsp,也可能是协程伪造的 rsp),而返回地址放到 previous 的 72 中 - 其余的按部就班赋值到 previous 的_registers 中
恢复过程则是从 next 的_registers 中恢复:
- 首次启动时已经由
preapre把必要的 ret 和函数传参 rdi 被写到_registers 上了,因此恢复时相当于直接调用对应函数(即调用callWhenFinish(next),里面嵌套着实际的用户回调) - 如果非首次启动,那么 ret 就是协程执行中的控制流
- 不管怎样,在恢复时,把当前 rsp 覆盖 return address,然后
ret指令执行后就能切换到对应的控制流
End
总的来说,协程的基本实现就是一个保存与恢复的维护,
其中比较 trick 的部分就是伪造栈和返回地址的操作
按照惯例,附上与内容无关的图

update. 22.7.14
我对 contextSwitch 做出一些小改动,现在支持内联汇编,不再需要 .S 文件
// 关于 attribute:
// 1. 必须要 no inline,保证 rdi 和 rsi 传递,否则很容易代码层面地 inline(导致 rsi 没传递)
// 2. weak 保证 C++ inline 作用,即 weak 符号,用于 header-only 库
// 3. optimize("O3") 相当于即使你用 O0 编译整个程序,这一段代码也会用 O3 去编,
// 因为 O0 会生成多余的 push/pop 指令导致 crash
extern "C" __attribute__((noinline, weak, optimize("O3")))
void contextSwitch(Context* prev /*%rdi*/, Context *next /*%rsi*/) {
asm volatile(R"(
movq %rsp, %rax
movq %rax, 104(%rdi)
movq %rbx, 96(%rdi)
movq %rcx, 88(%rdi)
movq %rdx, 80(%rdi)
movq 0(%rax), %rax
movq %rax, 72(%rdi)
movq %rsi, 64(%rdi)
movq %rdi, 56(%rdi)
movq %rbp, 48(%rdi)
movq %r8, 40(%rdi)
movq %r9, 32(%rdi)
movq %r12, 24(%rdi)
movq %r13, 16(%rdi)
movq %r14, 8(%rdi)
movq %r15, (%rdi)
movq 48(%rsi), %rbp
movq 104(%rsi), %rsp
movq (%rsi), %r15
movq 8(%rsi), %r14
movq 16(%rsi), %r13
movq 24(%rsi), %r12
movq 32(%rsi), %r9
movq 40(%rsi), %r8
movq 56(%rsi), %rdi
movq 72(%rsi), %rax
movq 80(%rsi), %rdx
movq 88(%rsi), %rcx
movq 96(%rsi), %rbx
movq 64(%rsi), %rsi
movq %rax, (%rsp)
xorq %rax, %rax
)");
// 这里由 gcc 直接生成 ret 指令
}
add header-only version · Caturra000/co@242d7e4
还有增加了一些 POSIX 接口的协程适配,比如 co::read
这部分就不介绍了,感兴趣看看代码吧:posix.h