前言
首先 F2FS 也不算新文件系统,迄今已超过 10 年了,但不妨碍它在闪存设备领域的流行。
然后我其实没怎么看论文,而是听作者的演讲,也没人规定论文一定要看文字对吧。
背景:为什么需要 F2FS
主要是随机写对 flash 设备不利。随机写的性能低于顺序写是常识了,但还有一个原因是影响设备寿命,这是由 flash 的物理特性决定的弊端,需要 FTL 完成写前擦除操作,随机写就是放大弊端。
进一步的考虑就是要做一个面向顺序写(具有磨损均衡特性)的文件系统,而这就是 F2FS。
设计思路与主要特性
- Flash-friendly on-disk layout.
- Cost-effective index structure.
- Multi-head logging.
- Adaptive logging.
- fysnc() acceleration with roll-forward recovery.
Layout
怎样才算是闪存友好的硬盘布局?

作者给的答案是按上图一样布局就是友好的:它考虑了闪存感知(flash awareness)和低清理成本(clean cost reduction)。
闪存感知指的是文件系统匹配闪存物理特性:
- superblock metadata 存放在一起(且是头部),以提高局部性和并行性。
- main area 的起始地址对齐与 zone 大小,这是考虑了 FTL 的工作特征。
- 以 section 为单位的文件系统 GC。
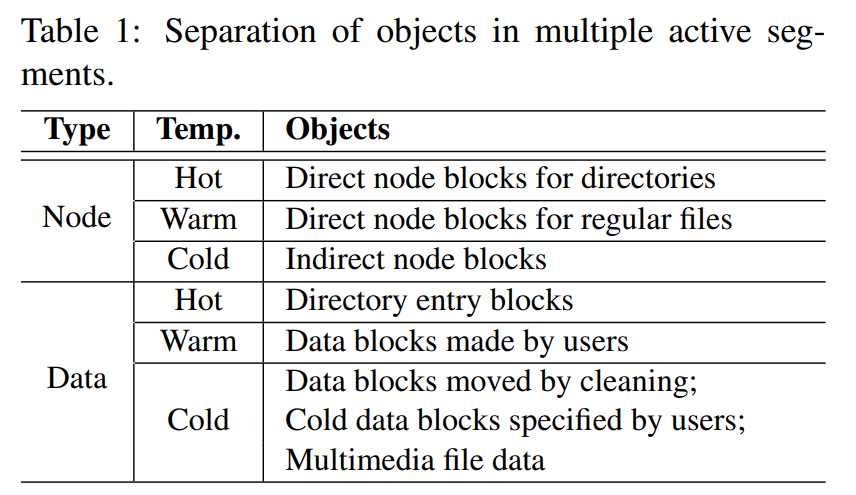
清理成本降低则是使用 Multi-head logging 实现冷热数据分离,见图中 Hot / Warm / Cold。
另外补充一些硬盘布局的说明,以下部分来自 kernel 文档:
- F2FS 将整个分卷都划分为若干 segment,每一个 segment 都是 2MB 大小。
- F2FS 按三级划分:section 包含若干 segment,zone 包含若干 section,但默认是 1:1:1 关系。
- F2FS 按功能划分 6 个 area:从 super block 到 main 如图所示。
- 如上面所说,main area 按 zone 对齐,同时 check point 按 segment 对齐。
- 除了 super block 以外,其它的 area 都具有多个 segment。
这 6 个 area 存储以下信息:
- Superblock:基本的分区信息以及 F2FS 的默认参数。它具有 2 个备份以避免文件系统崩溃。
- CP:文件系统信息,NAT/SIT 的 bitmap,orphan inode,以及 active segment 的 summary entry。
- SIT:segment 信息,比如 valid block 数目,(main area 的)block 对应的 valid bitmap。
- NAT:映射 main area 中所有 node block 的地址。
- SSA:summary entry,这里指的是 main area 中 block 对应的归属关系(parent node / offset 等)。
- Main area:文件和目录信息,以及它们的索引信息。
这里有个问题:为什么需要三级划分(zone-section-segment)?我个人理解是 zone 的引入是考虑 FTL 识别冷热数据的辅助单位(见下方 Multi-head logging 章节);而 section 则是一个文件系统 GC 时选用的单位(performs“cleaning”in the unit of section. …identify a victim selection,见下方 Cleaning 章节);而 segment 是基本管理单元(allocates storage blocks in the unit of segments),这可能是出于 F2FS 仍作为块设备文件系统的适配;这三种的单位的大小选值都需要考虑 FTL 硬件特征。
Index structure
作者通过对比 LFS 来体现 F2FS 的索引效率优势:
 LFS
LFS
 F2FS
F2FS
* SB = super block
* CP = check point
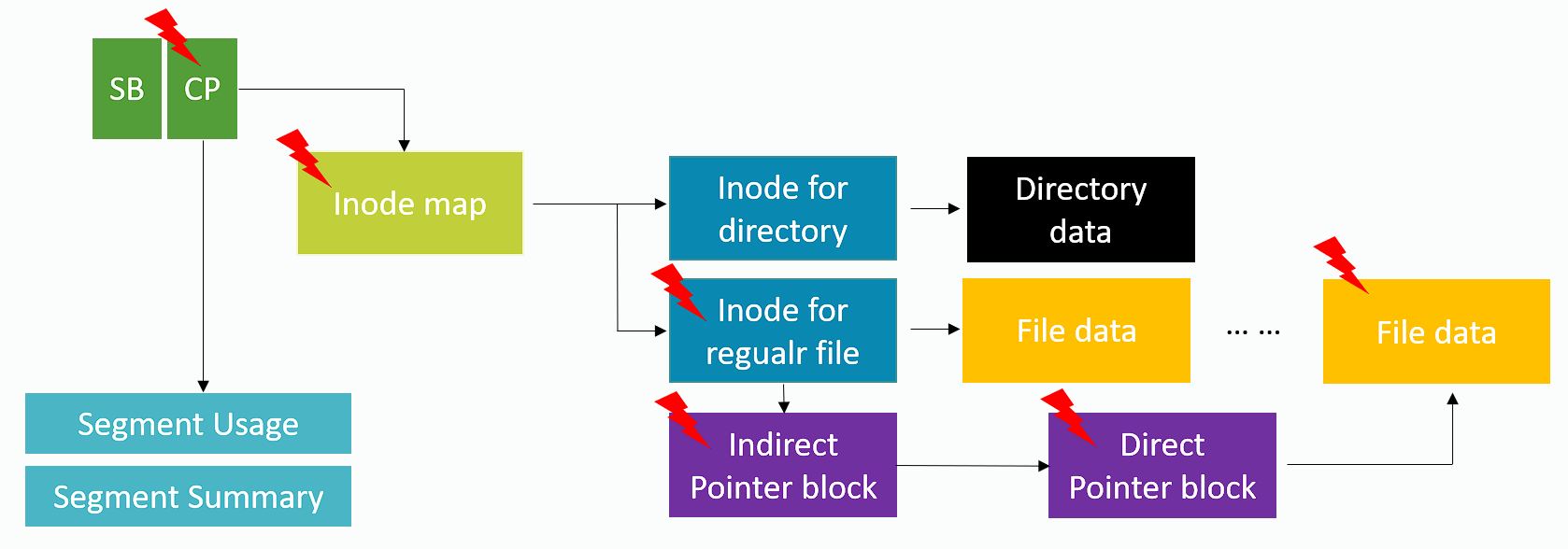
作者指出,LFS 有 2 个问题:
- Update propagation(Wandering tree):即使只想更新一个 block,内部也需要更新更多的 intermediate block(见红色⚡标记)。
- One big log:不管什么东西都走到同一个 log 里面,不区分 block 的特征。
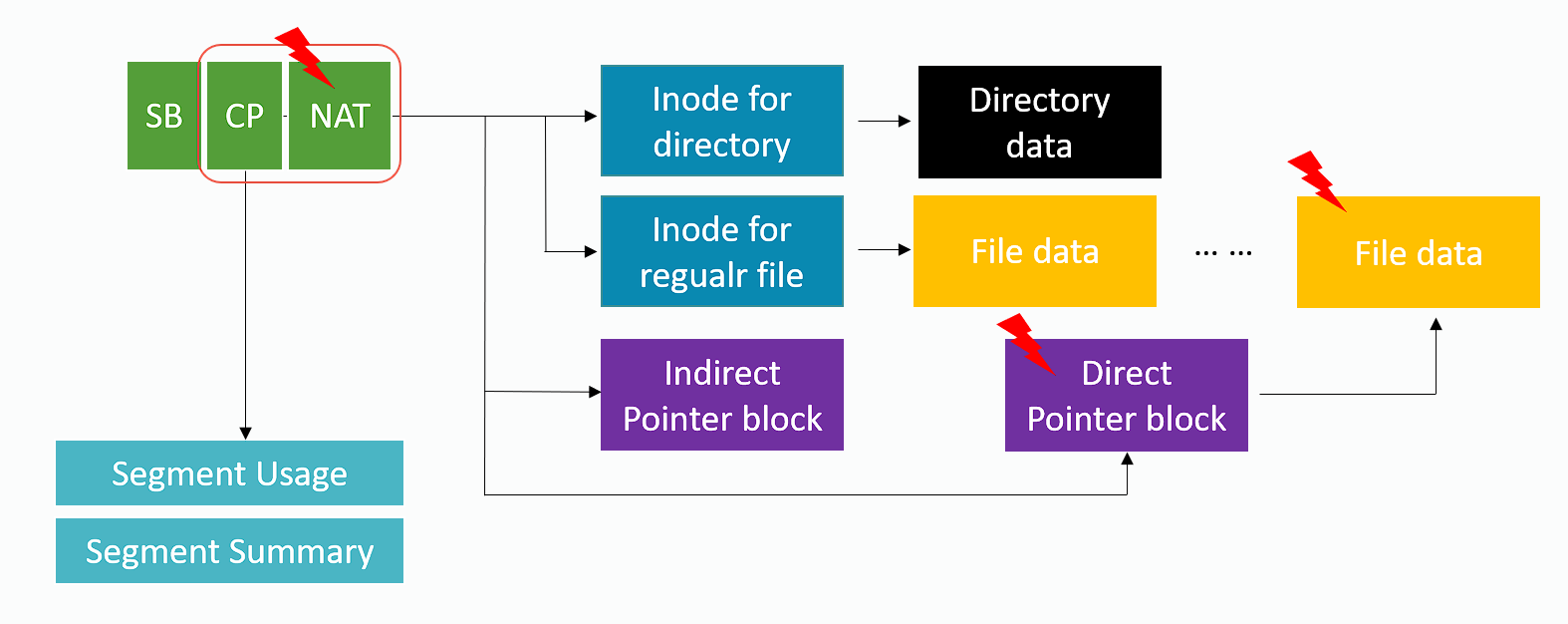
而 F2FS 则分别解决这两个问题:
- 使用 NAT(node address table)来处理 wandering tree:通过一个大表来直接将 node block id 翻译到物理地址,避免访问 indirect pointer block。在上图的场景中,不需更新 inode 和 indirect pointer block(因为 indirect pointer block 记录 node id,而 direct pointer block 记录 block address)。
- 使用 multi-head log 来替代 one big log:见上表,按类型和温度分为 6 种 log。区分 node 和 data 是因为 node 的更新频率更高于 data;两种类型在内部也细分不同的温度,一些准则是 direct 比 indirect 热、dentry 比 user file 热。另外在早期的 LWN 分享中也提到这种分离的思路,总结是它有两种收益:一是文件系统层面,足够冷的 log 可以避免不必要的 section GC;二是硬件层面,一个硬件设备可以由多个子设备构成,分离(且经过合理的 zone 参数调优后)可以提高 IO 的并行程度。
Multi-head logging?
上面已经提了 Multi-head logging 的冷热分离思路,而作者在 8:06 对 multiple log 仍有补充,但我听不清楚作者的具体表态,似乎是在讨论这种冷热分离对于硬件层面 FTL 的关联:即使有 multiple log,但是 FTL mapping 并不能得知这种关系,即使 F2FS 冷热分离,到最后 FTL mapping 仍然是混在同一个 erase block 中存放的,这种 node block 和 data block 混在一块的现象称为 zone-blind allocation。作者假定 F2FS 是 zone-based mapping,FTL 会将不同的 log 放到不同的区域。我认为这里的意思是分离数据的粒度是要按 zone 来划分的,这样才能避免 FTL mapping 后导致混到一块。
Cleaning
GC 加速的诀窍是 section 按照 FTL GC 单位的大小进行对齐。简单来说就是避免文件系统与 FTL 层面的不一致,其实也没啥好说的,文件系统会做 GC 清理数据,但是 FTL 可能会保留,不对齐的话就是两个层面互不搭配造成性能浪费。

具体流程如图,清理是可以前台(高效贪心)执行,也可以后台(成本最优)执行:
- 贪心和最优指的是找出 victim section 的算法策略。
- 贪心算法尝试找出含最少数目 valid block 的 section,通过控制迁移 block 成本以减少前台延迟。
- 最优算法除了像贪心一样考虑利用率以外,还需要参考 section 的「老化」程度(age)。SIT 会记录 last modified 的时间点,而这个时间的平均值就是一个 section 的「年纪」。
Adaptive logging
而清理会在老化(高占用、多碎片)时花费更多的时间,为了降低成本引入了 adaptive logging。具体来说,就是在不同的场合下使用不同的写策略:
- 当文件系统只剩 5% 的 free section 时,使用 threaded logging。
- 否则使用 append logging。
- 对于 node,不管空间大小总是使用 append logging。
threaded logging 是重新使用已经写过的 segment,因此是随机写行为,但并不需要清理操作;而 append 虽然是顺序写行为,但是空间不足时仍需清理,此时会是更严重的随机写行为。这也是为什么使用动态写策略的原因。
Recovery
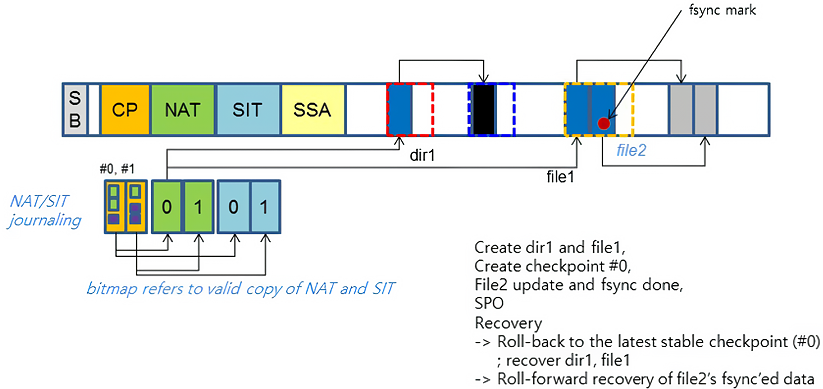
* SPO = Sudden Power Off
F2FS 使用 check point 来实现文件系统的一致性,避免宕机导致文件系统损坏。当调用 sync()、umount() 或者前台 GC 时,F2FS 会触发 check point。
简单来说,check point 就是一种 shadow copy(不被用户感知的备份),其备份会交替放置于 CP area 的 #1 和 #0 部分,check point 内容包含 NAT/SIT journaling,避免直接写入 NAT/SIT block。提供了必要的信息后,要执行 recovery 就是获取最新的 check point,然后回滚(roll-back recovery)到对应的时间点。

虽然使用 check point 来实现 fsync() 是一种可行的思路,但是成本是相当的高。为了减少 fsync() 的执行成本,F2FS 还引入了前滚(roll-forward recovery)操作来替代 check point 的回滚操作。它的思路是只更新对应的 direct node block 和 data block(其中 direct node block 打上 FSYNC 标记)。在执行 recovery 时,则通过标记好的 block 来重做一遍写操作。
Benchmark
benchmark 部分主要对标 ext4,粗略的负载结论如下:
- 按设备来看,SATA SSD 有 2.5 倍提升,PCIe SSD 有 1.8 倍提升。
- 按应用来看,SQLite 有 2 倍提升,iozone 有 3.1 倍提升。
但这些数据距离现在年代差异较大,参考价值不高(你也可以在这里得到较新的民间数据)。这几年按前司的经验来看,移动设备不同场合下与 ext4 互有胜负。
另外作者在演讲中也暗示了,F2FS 这么厉害是因为它很懂 FTL 的特征(甚至能用某种 stream interface 控制 FTL 的行为)。为什么懂呢?因为作者是三星员工,而测试设备的 FTL 就是三星自己造的,能不懂吗。这也意味着你放到其它厂商不同固件的设备,不一定能达到上面跑分这么夸张的差距。
总结就是,即使你用了看似开源且一模一样的代码,自研与非自研之间,实则存在着一堵高墙。
References
FAST ‘15 - F2FS: A New File System for Flash Storage - YouTube