前言
本文覆盖三个话题:
- 通过 RFC5681 了解 TCP 拥塞控制算法做出的硬性要求。
- 通过 Congestion Avoidance and Control 了解 TCP Tahoe 和 TCP Reno 的算法细节。
通过 Linux Kernel(版本 v6.4.8)梳理 TCP NewReno 的具体实现。(写了一点,已鸽)
RFC5681
必要算法
RFC5681 描述的拥塞控制就是经典的四个阶段:
- 慢启动。
- 拥塞避免。
- 快速重传。
- 快速恢复。
但该提案只要求一个拥塞控制算法必须实现慢启动和拥塞避免,其实现允许更加保守,却不能更加激进。
变量维护
在慢启动和拥塞避免阶段中,实现算法需要为每连接(per-connection)维护两个参数:拥塞窗口 cwnd 和接收端通告窗口 rwnd。cwnd 是发送端的限制,而 rwnd 是接收端的限制,因此 min(cwnd, rwnd) 决定数据的传输。除此以外,还需要一个状态变量:慢启动阈值 ssthresh,该变量决定当前使用慢启动算法还是拥塞避免算法。
对于 cwnd,它的初值被设为 2-4 倍的 MSS。严格来说,必须按照以下算法:
- 如果 MSS 大于 2190 字节:设为 2MSS。
- 如果 MSS 小于等于 2190 字节,且大于 1095 字节:设为 3MSS。
- 如果 MSS 小于等于 1095 字节,设为 4MSS。
cwnd初值在后续 RFC6928 中有增加到 10MSS,这也是目前 Linux 内核实现中使用的值。
对于 ssthresh,它必须在发生拥塞时减小自身的大小。而它决定使用算法的规则很简单:当 cwnd < ssthresh 时,使用慢启动,否则使用拥塞避免,但实际上 cwnd == ssthresh 时任选算法也是可以的。
在各阶段中的变量维护也有一定要求,大概列一下:
- 慢启动过程中,每次 ACK 接收后
cwnd增加不得超过 MSS 字节。 - 拥塞避免过程中,每 RTT 间隔
cwnd大概增加 MSS 字节,也要求不得超过 MSS 字节。 - 当超时定时器触发时,
ssthresh必须设为max(in_flight / 2, MSS * 2),cwnd必须不超过 1 个 MSS 大小。其中in_flight指的是徘徊在网络中(而未被任意端接收)的数据,通常使用cwnd去代替它,后面在 Reno 算法中会提到这个细节。
这些只是硬性要求,不能说就是某种实现。在下文将展示具体的拥塞控制实现。
TCP Tahoe
TCP Tahoe 的实现是基于论文 Congestion Avoidance and Control,且应用于早期的 4.3-BSD 版本中。需要特意注明的是快速重传并没有在该论文中体现,但 TCP Tahoe 实在是太古老了,因此我只能找一些很书面的资料(理论上能在 git 仓库找到代码,但我能从中看出什么呢?),甚至考古文献Berkeley TCP Evolution from 4.3-Tahoe to 4.3-Reno已经在互联网绝迹了,这在互联网领域有点地狱笑话。
后记:历经千辛万苦总算找到了!不过没啥参考价值。
Tahoe 除了实现必要的慢启动和拥塞避免外,还实现了快速重传。
背景:基于窗口的拥塞控制
在尚未具有拥塞控制能力的 TCP 实现中,TCP 的(发送)窗口大小是由通告窗口 rwnd 来决定的,但它关注对端能否为此分配内存而不关注网络拥塞。为了满足拥塞控制的需求,TCP 实现引入了拥塞窗口 cwnd,它是一个受拥塞控制算法影响的(通常)相对通告窗口较小的值。
当你在一个好到不得了的网络里使用 TCP 时,有可能发送窗口仍是主要受制于内存上限,即瓶颈是
rwnd而不是cwnd。
最佳的窗口与慢启动算法
一个“最佳”的窗口大小可以利用带宽时延积得出 \(bandwidth \times RTT_{noLoad}\),它表示一个网络连接中允许容纳的最大数据容量。其中 \(bandwidth\) 是理论值,可以从介质的传输速率得出;而 \(RTT_{noLoad}\) 表示一个没有入队延迟的包传输延迟,即 \(RTT\) 减去任何需要排队等待的额外延迟,它是一个估算值,可以通过在每一次 RTT 采样中取最小值得出。理论上通过这种方式得到的窗口值可以将网络“填满”数据包,却又没有需要等待排队发出的延迟现象(With this window size, the sender has exactly filled the transit capacity along the path to its destination, and has used none of the queue capacity),但这只是理论。
有另一种更有实践价值的思路:当你知道一个网络的容量时,你可以使用二分搜索的方式去测试当前最佳窗口值;当你不知道一个网络的容量时,一个策略是先猜测 cwnd=1(或者 cwnd=2,注意单位是 packet 不是 byte),然后每次有正反馈时就倍增(cwnd*2),如果存在负反馈,那就回退到上一次的猜测值(cwnd/2),这样能保底确认猜测值在真实容量的±50% 误差范围内。
这里的网络容量在原文中说的比较形象,界限被划分为 knee 和 cliff:knee 表示开始发生排队行为,吞吐量上涨缓慢而延迟增加;cliff 表示开始发生丢包行为,吞吐量急剧下降,延迟急剧上升。不同的拥塞控制算法的抉择不一样,比如 TCP Vegas 就属于 knee-based 算法,而 TCP Tahoe/Reno则是cliff-based:表示我们能容许排队,但不容许丢包。
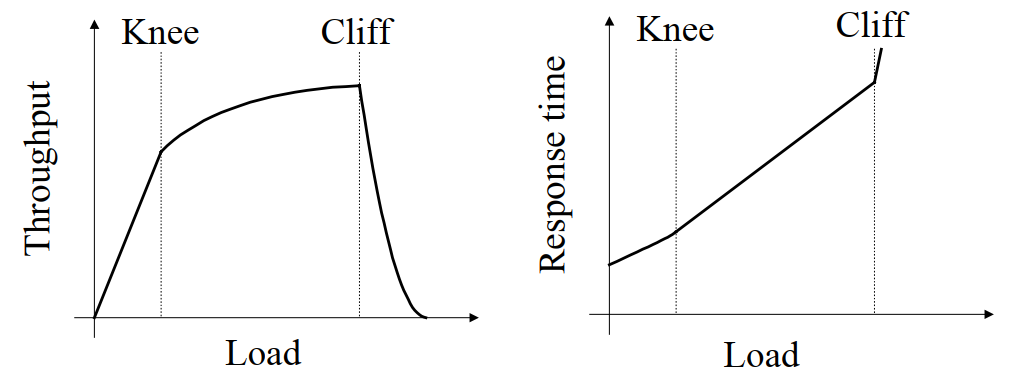
还有一个问题是为什么不一开始就加大剂量?猜测值会如此保守?一个踩过坑的原因如下:
In the original send policy used in BSD, a bulk-data transfer would start out by sending a full window of packets once the connection was established. These packets could be sent at the full speed of the network to the bottleneck router, but that router could transmit them at only a much slower rate. As a result, the initial burst of packets was highly likely to overflow the router’s queue, and some of the packets would be lost.
实际上的慢启动算法选择了后一种做法。因为是首次运行,那自然不知道网络上的容量。它是 per-ACK 就执行 cwnd+=1,因此当发出整个窗口(cwnd 大小)和,就收到 cwnd 个 ACK,即 cwnd+cwnd,实现了倍增策略。注意这里说收到 ACK 报文后就增加 1,但实际上并不包括旧报文的重复 ACK。还有倍增指的是空间上每隔一个窗口,时间上每隔一次 RTT。
假设当 cwnd=2^n 即经过 N 次 RTT 后,队列容量(前面提到的 queue capacity)到达瓶颈,将会产生丢包行为,那么 cwnd 将回退到 cwnd=2^{n-1}。为什么要这样做?一个可能的理由是,可以认为当到达瓶颈时,transit capacity = queue capacity = N,对窗口进行折半处理后,可以做到 transit capacity = N, queue capacity = 0,这样就能避免剧烈的延迟。
NOTE: 这个角度比较抽象,后面有看似更合理的分析说明必须按比例回退的原因。
一些或许没啥用的知识:
- transit capacity 通常是不变的,queue capacity 则可能是瓶颈,这也是前面折半处理一个是 N 另一个是 0 的原因。
- 不管是哪种 capacity,它作为一种资源,那都是会被多个连接所共用,因此拥塞控制需要公平性。
最终慢启动的结果是能让 TCP 达到一种“稳定状态”:… once reach steady state, a full window of data often could be accommodated by the network.
AIMD 实现拥塞避免
虽然拥塞避免是可以作为独立的算法去使用,但是通常是和慢启动一起实现的,这里需要了解背景。虽然慢启动是暂时到达了稳定状态,但它看到的是一个链路只有当前连接的发送端和接收端。实际上前面也提到,网络资源是实际被多个连接所共用,因此网络还存在多连接间流量上的竞争。为了解决这个问题,原论文要求网络能够通知 TCP 达到一种拥塞状态,网络具备这种能力后,TCP 就能在未拥塞时提高利用率,已拥塞时降低利用率。对于“网络能够通知 TCP”这种行为,作者的大概意思是 TCP 是 self-clocking 的(以 ACK 作为时钟驱动),无需做出修改便能做到。而利用率的调整自然是体现在窗口上。
前面提到慢启动是每一次 ACK 接收后 cwnd+=1,而在拥塞避免过程中是每整个窗口过后 cwnd+=1。为了统一计算,可以将后者转换为每一次 ACK 接收后 cwnd+=1/cwnd,这种计算方式要求内核在内部保留浮点,但是外部输出时可以下取整作为一个整数去看待。或者说当 cwnd 是按字节计算的时候,只要它足够大,那么只算整数部分也没啥关系。另外在 RFC3465 中有提到一个关于 delayed ACK 的改进,因为延迟的特性,ACK 包可以是合并后发出的,因此允许把算法修正为 cwnd+=2/wcnd,表示把一个 ACK 确认两个 packet 的行为视为原先每 ACK 确认单个 packet,保持算法的一致性。
如果拥塞避免过程,发现上一个窗口存在丢包行为,那么 cwnd/=2。实际上,TCP Tahoe 在确认超时的情况下,直接设为 cwnd=1,这在后面章节再说明。
4.4-BSD 实现对于超时行为并不区分是慢启动还是拥塞避免,均设为
cwnd=1:It is set to one packet whenever transmission stops because of a timeout.
为什么拥塞避免的算法是 AIMD(加性增窗、乘性减窗)?论文也给出一个论证的过程。
先看乘性减窗。在这里,网络负载是用固定间隔检测(接近 RTT)的平均队列长度去衡量,设 \(L_i\) 为间隔 \(i\) 的网络负载。如果此时处于非拥塞状态,那么在采样时间内,负载基本保持不变,也就是 \(L_i = N\),其中 \(N\) 是常数;如果处于拥塞状态,\(L_i = N + \gamma L_{i-1}\),其中 \(N\) 是新发出的包的平均到达率,而 \(\gamma L_{i-1}\) 是上一次间隔中残留在网络的包所带来的负载。实际上 \(L_i\) 应该遵循泰勒展开的形式 \(L(t)\),因为还可能包含了上几次残留的包,但这里只取前两项是相对实际的情况。在拥塞的情况下,\(\gamma\) 肯定是一个足够大的值,也就是说 \(L_i ≈ \gamma L_{i-1}\),进一步得出 \(L_n = \gamma ^ n L_0\),这表明拥塞状态下队列长度的增长是指数级上升的。为此我们需要让流量源的抑制速度和队列增长速度一样快,而我们可以通过窗口大小来控制流量源,因此在拥塞状态下,窗口应该遵循公式 \(W_i = d W_{i-1}\),其中 \(d\) 小于 1。这也是为什么 cwnd/=2 的原因,就是 \(d = \frac{1}{2}\)。
然后是加性增窗。当网络处于非拥塞状态下,其实就是上文 \(\gamma\) 接近于 0。对比网络处于拥塞状态时会“通知”TCP,非拥塞状态并不会特意“通知”。这有什么问题?问题是前面提到了网络作为一种资源是被多个连接所共享的,假设本来有 2 个连接,其中突然关闭了 1 个,那对于当前连接来说是浪费了 50% 的总带宽。因此,窗口需要不断增加来得知容量的上限。但问题是增加多少?一个灵感来自上面的乘性减窗,不如尝试 \(W_i = b W_{i-1}\),其中 \(1 \lt b \le \frac{1}{d}\)。但作者指出这是错误的,原因是容易导致网络饱和且难以恢复(rush-hour effect)。作者给出一个实践上的做法:\(W_i = W_{i-1} + u\),其中 \(u \ll W_{max}\)。当 \(u = 1\) 时,就可以得到 cwnd+=1。
所以为什么取 \(\frac{1}{2}\) 还有 \(1\) 呢(别问了!)?因为丢包可能是在启动过程或者稳定状态下发包发生的,对于前者,你已经确认了前 \(\frac{1}{2}\) 的窗口大小是没问题的,那么取这个值也没有问题;对于后者,可能是由于新创建的连接占用了网络的带宽资源导致的,而出于公平性,资源是公平共享的,因此也是 \(\frac{1}{2}\)。那为什么增加时取 1?作者是基于观察得出一个结论:当窗口大小为 \(w\) 时,使用加性增窗就有可能每 \(O(w^2)\) 个包之间存在丢失行为。而作者设立一个目标是要求平均丢包率小于 \(1\%\),且已知实践上最糟糕的情况下窗口会收敛到只有 8-12 个数据包。所以选择 \(u=1\) 就最为激进的满足了 \(1\%\) 的平均丢包率(此前存在方案是 \(u=\frac{1}{2}\))。
使用有界阈值来结合算法
事实上前面描述的慢启动和拥塞避免是单独使用时的情况,历史上这两种算法是独立发展的,但正如前面提到,它们通常是一起实现的。在这种情况下引入了 ssthresh 阈值,实现了有界的慢启动和拥塞避免。具体公式不提了,相信各位学过计算机网络,允许我偷懒一下。
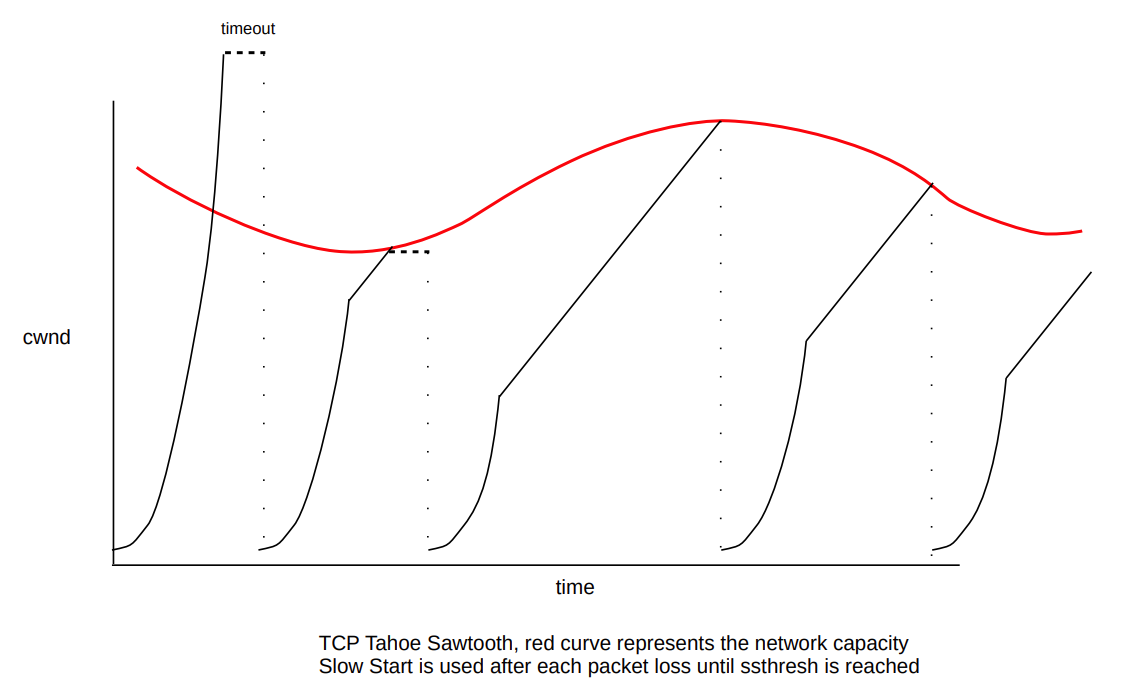
图中折点就是不同时间点下设置的 ssthresh,为重新执行慢启动前的 cwnd/2 大小。
One More Thing: 快速重传

TCP Tahoe 除了实现必要算法以外,还实现了快速重传。意思很简单,当收到连续 3 次的重复 ACK 后,重传对应的数据包并直接重启慢启动(ssthread=cwnd/2 && cwnd=1)。
这种做法的意图是发送端认为重复的 ACK 是由于丢失导致的(即窗口存在“空洞”),因此视为丢包。
那么为什么是 3 次而不是 2 次?原因是快速重传需要避免简单的乱序行为。由于路由架构的特性以及发包操作实际可以是并行的,即不同的包可以通过不同的路径到达对端,因此乱序在非拥塞网络中也是存在的。End-to-End Internet Packet Dynamics 中指出在第二次 ACK 就过早执行重传是有风险的。
一个细节是当原发送端收到重复 ACK 时,虽然可能意味着多个后续包也丢失了,但发送端仍只重传单个(首个认为丢失的)数据包。这里的原因是丢失已经被认为网络拥塞了,不宜往网络注入更多的包。比方说假设发送端需要确认 DATA[5]、DATA[6] 和 DATA[7],但只重复收到对 seq=5 的确认 ACK[5](这里的定义和 TCP 报文头的 ACK 有差异),那么 DATA[6] 及后续的包不会立刻重传。
TCP Reno
其实 TCP Reno 和 TCP Tahoe 本质是相同的,它们之间的版本差只间隔 2 年。如果不考虑直到现在仍在改进中的 TCP (New)Reno,那么 TCP Reno 初版是相比 TCP Tahoe 新增了快速恢复。RFC5681 指出,在不使用 SACK 选项前提下,快速恢复使用的是 partial ACK 机制,本文也不考虑 SACK 的情况。
TCP Reno is TCP Tahoe with the addition of Fast Recovery.
partial acknowledgments: ACKs that cover new data, but not all the data outstanding when loss was detected.
这里回到前面快速重传的例子来说明快速恢复的需求背景。通常快速重传在足够的窗口下 DATA[5] 超时后,DATA[6] 和 DATA[7] 也会紧接着超时,但是快速重传的做法是重发 DATA[5] 后,窗口紧缩。这样发送端后续是忽略了 DATA[6] 和 DATA[7] 的超时(已经不在窗口范围内),这种现象需要直到恢复完成(窗口增大)才能正常执行超时。但这存在的问题是此时处于“管道枯竭”的状态,就是说网络当前很可能没有任何 in-flight packet,这里暗示恢复过程会非常慢。那么接下来的做法是使用快速恢复让恢复过程足够快——简单来说就是避免网络间存在“空挡”。
Once a full timeout has occurred, usually the sliding-windows process itself has ground to a halt, in that there are usually no packets remaining in flight. This is sometimes described as pipeline drain.
快速恢复使用重复的 ACK 来调整“重传速率”。快速重传由于 cwnd 设为 1,并没有多余的 ACK 来提供调整的参考样本,而对比之下快速恢复则把目标设为 cwnd=cwnd/2,具体过程见下文。
一个细节是 TCP Reno 假设丢的是一个包,后续 TCP NewReno 扩展到多个丢包。
RFC5681 的快速恢复
RFC5681 的实现是利用通货膨胀/紧缩的概念(就像解决债务危机一样),在丢包时记录 C=cwnd,紧接着 cwnd 膨胀到 cwnd=1.5C,当丢失的包重传成功后,cwnd 紧缩为 cwnd=C/2,此时窗口范围 [lb, ub] 中的 lb 右移 C 位,ub 保持不变。有人对此的观点是看着挺不错,但不好做。
实践意义的快速恢复
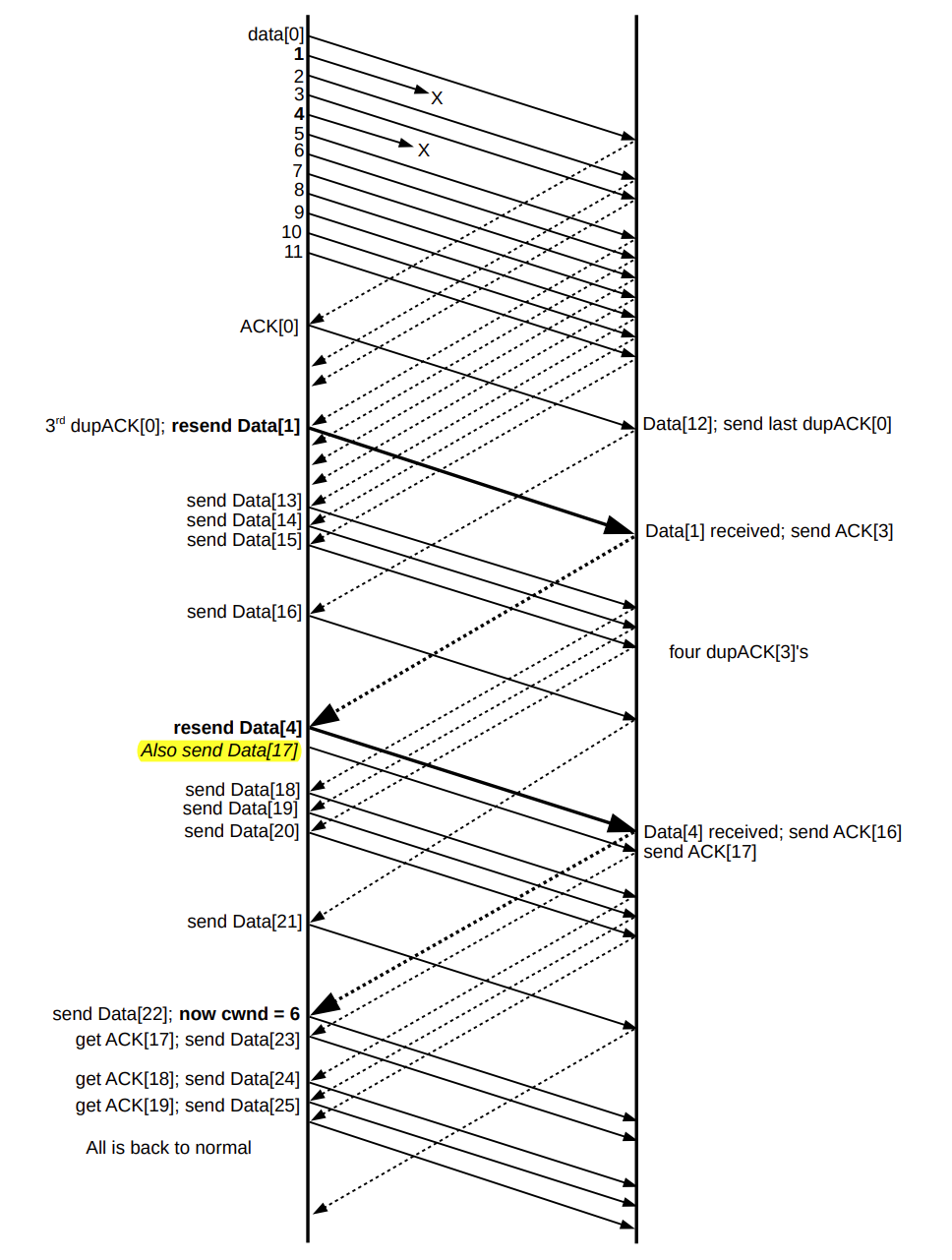
另一种做法是通过 EFS(Estimated FlightSize,表示发送端对网络中徘徊的包的一个猜测值)来完成,一般来说,EFS 就是 cwnd。有了 EFS 的概念,那么每一次 ACK 到来,那意味着传输过程中已经少了一个包,EFS 应该减去 1。当 EFS 一直减到小于 cwnd/2 时,那么就可以进行新的数据包的传输。当丢包的数据成功传达确认后,设为 cwnd=cwnd/2。
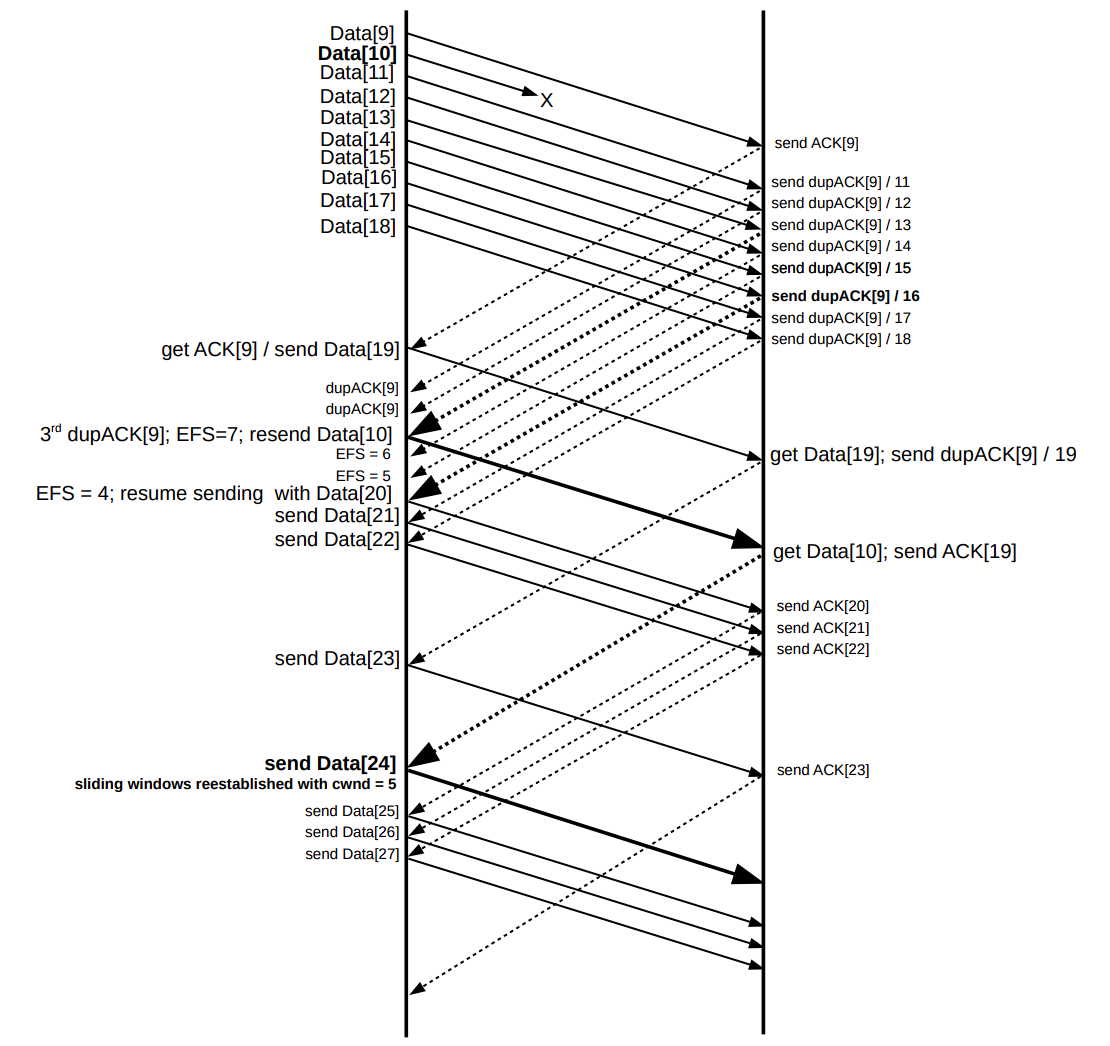 EFS 应用示例,注意加粗部分
EFS 应用示例,注意加粗部分
可以看到 EFS=N-3 时(接收 3 次 dupACK),就触发了快速重传,但是 cwnd 并没有立刻紧缩到 1(而是 N/2+3,加 3 是因为已经收到 3 次 dupACK。原 cwnd 值可以用 ssthresh 暂存);后续在接收 N/2-3 次 dupACK 后就开始恢复新数据的发送(因为每次 dupACK 都会 cwnd+=1),再接下来 N/2-1 次 dupACK 中,每一次 dupACK 都发一个新的数据包。后续窗口会静止直到 non-dup ACK 的到来(ACK[19])。
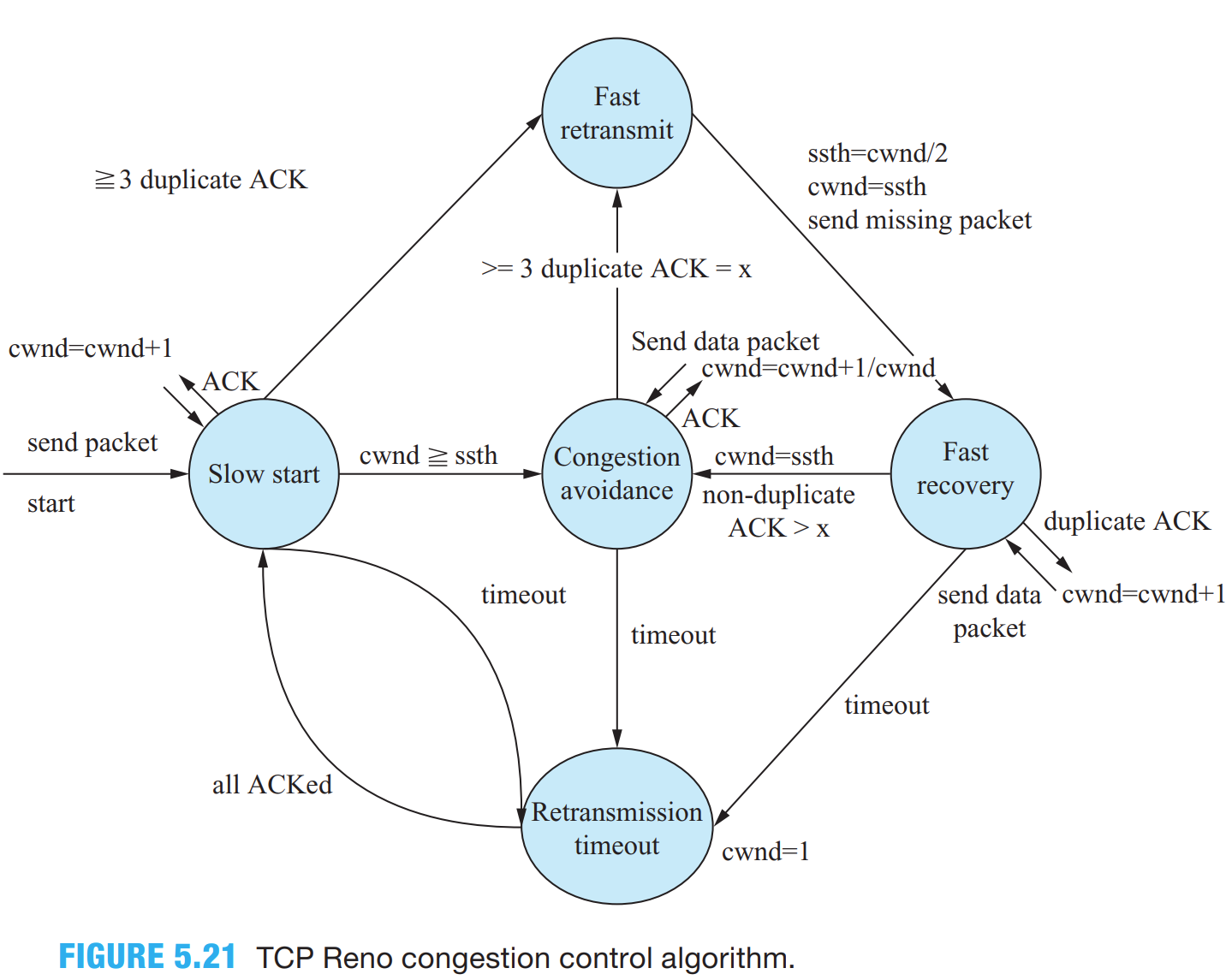
TCP Reno 的状态机可以见上图。
MPL 问题以及 NewReno
TCP Reno 的拥塞控制仍然残有单个窗口内的 MPL(Multiple-Packet-Loss)问题需要解决。TCP Reno 的观点是接收到一个 partial ACK(non-dup ACK)就是一次成功的重传,因此会从快速恢复回到拥塞避免(见上面的状态机图示)。如果存在多个包丢失的情况,那需要再次走拥塞避免 - 快速重传 - 快速恢复的状态转换,这在实际意义上表明没法在一个 RTT 内处理多个丢包的情况。与之相反,TCP NewReno 视 partial ACK 为一种进一步丢包的信号,因此收到后仍会继续重传(行为上等同于收到一个 dupACK),这使得 TCP NewReno 可以在一个 RTT 范围内处理单个窗口的多个丢包。
如上图,这种状态需要维持到不再接收 partial ACK 为止(即补上了丢包的“空洞”data[1] 和 data[4])。
Kernel Implementation
Overview
在 Linux 内核中,不同的拥塞控制算法均由结构体 tcp_congestion_ops 来描述:
struct tcp_congestion_ops {
/* fast path fields are put first to fill one cache line */
/* return slow start threshold (required) */
u32 (*ssthresh)(struct sock *sk);
/* do new cwnd calculation (required) */
void (*cong_avoid)(struct sock *sk, u32 ack, u32 acked);
/* call before changing ca_state (optional) */
void (*set_state)(struct sock *sk, u8 new_state);
/* call when cwnd event occurs (optional) */
void (*cwnd_event)(struct sock *sk, enum tcp_ca_event ev);
/* call when ack arrives (optional) */
void (*in_ack_event)(struct sock *sk, u32 flags);
/* hook for packet ack accounting (optional) */
void (*pkts_acked)(struct sock *sk, const struct ack_sample *sample);
/* override sysctl_tcp_min_tso_segs */
u32 (*min_tso_segs)(struct sock *sk);
/* call when packets are delivered to update cwnd and pacing rate,
* after all the ca_state processing. (optional)
*/
void (*cong_control)(struct sock *sk, const struct rate_sample *rs);
/* new value of cwnd after loss (required) */
u32 (*undo_cwnd)(struct sock *sk);
/* returns the multiplier used in tcp_sndbuf_expand (optional) */
u32 (*sndbuf_expand)(struct sock *sk);
/* control/slow paths put last */
/* get info for inet_diag (optional) */
size_t (*get_info)(struct sock *sk, u32 ext, int *attr,
union tcp_cc_info *info);
char name[TCP_CA_NAME_MAX];
struct module *owner;
struct list_head list;
u32 key;
u32 flags;
/* initialize private data (optional) */
void (*init)(struct sock *sk);
/* cleanup private data (optional) */
void (*release)(struct sock *sk);
} ____cacheline_aligned_in_smp;
其中 ssthresh() 用于计算 ssthresh,cong_avoid() 用于计算 cwnd。
而拥塞控制的框架调用过程在接收到 ACK 报文时触发:
tcp_ack()
tcp_cong_control()
tcp_cong_avoid()
icsk->icsk_ca_ops->cong_avoid() ⭐
最后一步通过不同算法的回调注册完成具体算法和框架的分离:
struct tcp_congestion_ops tcp_reno = {
.flags = TCP_CONG_NON_RESTRICTED,
.name = "reno",
.owner = THIS_MODULE,
.ssthresh = tcp_reno_ssthresh,
.cong_avoid = tcp_reno_cong_avoid,
.undo_cwnd = tcp_reno_undo_cwnd,
};
初始化
cwnd 的初始值是 RFC6928 建议的 cwnd=10。
/* TCP initial congestion window as per rfc6928 */
#define TCP_INIT_CWND 10
ssthresh 的初始值被设为一个足够大的值。
#define TCP_INFINITE_SSTHRESH 0x7fffffff
在 tcp_sock 初始化时调用:
/* Address-family independent initialization for a tcp_sock.
*
* NOTE: A lot of things set to zero explicitly by call to
* sk_alloc() so need not be done here.
*/
void tcp_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
// ...
/* So many TCP implementations out there (incorrectly) count the
* initial SYN frame in their delayed-ACK and congestion control
* algorithms that we must have the following bandaid to talk
* efficiently to them. -DaveM
*/
tcp_snd_cwnd_set(tp, TCP_INIT_CWND);
// ...
/* See draft-stevens-tcpca-spec-01 for discussion of the
* initialization of these values.
*/
tp->snd_ssthresh = TCP_INFINITE_SSTHRESH;
tp->snd_cwnd_clamp = ~0;
tp->mss_cache = TCP_MSS_DEFAULT;
// ...
}
static inline void tcp_snd_cwnd_set(struct tcp_sock *tp, u32 val)
{
WARN_ON_ONCE((int)val <= 0);
tp->snd_cwnd = val;
}
慢启动实现
在 tcp_reno_cong_avoid() 中会执行慢启动过程:
/*
* TCP Reno congestion control
* This is special case used for fallback as well.
*/
/* This is Jacobson's slow start and congestion avoidance.
* SIGCOMM '88, p. 328.
*/
__bpf_kfunc void tcp_reno_cong_avoid(struct sock *sk, u32 ack, u32 acked)
{
struct tcp_sock *tp = tcp_sk(sk);
if (!tcp_is_cwnd_limited(sk))
return;
/* In "safe" area, increase. */
if (tcp_in_slow_start(tp)) {
acked = tcp_slow_start(tp, acked);
if (!acked)
return;
}
/* In dangerous area, increase slowly. */
tcp_cong_avoid_ai(tp, tcp_snd_cwnd(tp), acked);
}
通过 tcp_in_slow_start() 判断是否位于慢启动范围内:
static inline bool tcp_in_slow_start(const struct tcp_sock *tp)
{
return tcp_snd_cwnd(tp) < tp->snd_ssthresh;
}
如果没问题,那就进入 tcp_slow_start() 计算慢启动下的 cwnd:
/* Slow start is used when congestion window is no greater than the slow start
* threshold. We base on RFC2581 and also handle stretch ACKs properly.
* We do not implement RFC3465 Appropriate Byte Counting (ABC) per se but
* something better;) a packet is only considered (s)acked in its entirety to
* defend the ACK attacks described in the RFC. Slow start processes a stretch
* ACK of degree N as if N acks of degree 1 are received back to back except
* ABC caps N to 2. Slow start exits when cwnd grows over ssthresh and
* returns the leftover acks to adjust cwnd in congestion avoidance mode.
*/
__bpf_kfunc u32 tcp_slow_start(struct tcp_sock *tp, u32 acked)
{
u32 cwnd = min(tcp_snd_cwnd(tp) + acked, tp->snd_ssthresh);
acked -= cwnd - tcp_snd_cwnd(tp);
tcp_snd_cwnd_set(tp, min(cwnd, tp->snd_cwnd_clamp));
return acked;
}
这里提到计算方式是基于 RFC2581,其实这份文件等同于 RFC5681(就是文中提到的 RFC)。由于慢启动是 per-ACK 就增加 1,那么就加上对应的 ACK 个数 acked,并且更新 cwnd(内核中是 snd_cwnd),需要多处理一步 clamp,表示窗口固有的上限。如果更新前 cwnd + acked 不超过 ssthresh,那就是说并不会越过慢启动边界,该函数返回 0;否则返回除去慢启动过程外还需处理的 ack 个数,在后续的情况会顺延到拥塞避免过程 tcp_cong_avoid_ai() 继续处理(并没有 return)。
拥塞避免实现
进入拥塞避免的情况有 2 种,一是 cwnd 早已超过了 ssthresh,二是 cwnd 没有超过 ssthresh,但是 cwnd+acked 超过 ssthresh。
/* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w),
* for every packet that was ACKed.
*/
__bpf_kfunc void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w, u32 acked)
{
/* If credits accumulated at a higher w, apply them gently now. */
if (tp->snd_cwnd_cnt >= w) {
tp->snd_cwnd_cnt = 0;
tcp_snd_cwnd_set(tp, tcp_snd_cwnd(tp) + 1);
}
tp->snd_cwnd_cnt += acked;
if (tp->snd_cwnd_cnt >= w) {
u32 delta = tp->snd_cwnd_cnt / w;
tp->snd_cwnd_cnt -= delta * w;
tcp_snd_cwnd_set(tp, tcp_snd_cwnd(tp) + delta);
}
tcp_snd_cwnd_set(tp, min(tcp_snd_cwnd(tp), tp->snd_cwnd_clamp));
}
可以看出内核维护一个 snd_cwnd_cnt 计数器避免了浮点计算,来实现 cwnd+=1/cwnd 的效果。
更改 ssthresh
在内核实现中,拥塞控制是通过维护一个状态机 CA 来实现的。状态机进入到 TCP_CA_CWR/Recovery/Loss 状态时,将执行 tcp_reno_ssthresh() 更改 ssthresh。
在一段注释中提到状态机的工作原理:Linux NewReno/SACK/ECN state machine。
/* Enter Loss state. */
void tcp_enter_loss(struct sock *sk)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
bool new_recovery = icsk->icsk_ca_state < TCP_CA_Recovery;
u8 reordering;
tcp_timeout_mark_lost(sk);
/* Reduce ssthresh if it has not yet been made inside this window. */
if (icsk->icsk_ca_state <= TCP_CA_Disorder ||
!after(tp->high_seq, tp->snd_una) ||
(icsk->icsk_ca_state == TCP_CA_Loss && !icsk->icsk_retransmits)) {
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tp->prior_cwnd = tcp_snd_cwnd(tp);
tp->snd_ssthresh = icsk->icsk_ca_ops->ssthresh(sk);
tcp_ca_event(sk, CA_EVENT_LOSS);
tcp_init_undo(tp);
}
tcp_snd_cwnd_set(tp, tcp_packets_in_flight(tp) + 1);
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd_stamp = tcp_jiffies32;
/* Timeout in disordered state after receiving substantial DUPACKs
* suggests that the degree of reordering is over-estimated.
*/
reordering = READ_ONCE(net->ipv4.sysctl_tcp_reordering);
if (icsk->icsk_ca_state <= TCP_CA_Disorder &&
tp->sacked_out >= reordering)
tp->reordering = min_t(unsigned int, tp->reordering,
reordering);
tcp_set_ca_state(sk, TCP_CA_Loss);
tp->high_seq = tp->snd_nxt;
tcp_ecn_queue_cwr(tp);
/* F-RTO RFC5682 sec 3.1 step 1: retransmit SND.UNA if no previous
* loss recovery is underway except recurring timeout(s) on
* the same SND.UNA (sec 3.2). Disable F-RTO on path MTU probing
*/
tp->frto = READ_ONCE(net->ipv4.sysctl_tcp_frto) &&
(new_recovery || icsk->icsk_retransmits) &&
!inet_csk(sk)->icsk_mtup.probe_size;
}
一个 ca_ops->ssthresh() 的调用时机在 tcp_enter_loss(),通过它来改动 tp->snd_ssthresh 取值。
/* Slow start threshold is half the congestion window (min 2) */
__bpf_kfunc u32 tcp_reno_ssthresh(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
return max(tcp_snd_cwnd(tp) >> 1U, 2U);
}
具体的实现接近如上面描述的算法 ssthresh=cwnd/2,唯一的差异是确保最小 ssthresh=2。
丢失恢复实现
这一块已经不在 tcp_cong.c 的范围内(这是 NewReno 实现的文件),而是在 tcp_input.c 或者 tcp_recovery.c,并且加入了非常多的高级特性。
/*
* The sender is in fast recovery and retransmitting lost packets,
* typically triggered by ACK events.
*/
TCP_CA_Recovery = 3,
// ...
/*
* The sender is in loss recovery triggered by retransmission timeout.
*/
TCP_CA_Loss = 4
对于 CA 状态机,我关注这两个:TCP_CA_Recovery 和 TCP_CA_Loss。如果是 ACK 确认,那可能进入 TCP_CA_Recovery,表明 cwnd 已经缩减,并且是进入快速重传的状态;如果是 RTO 超时,那么相对的进入 TCP_CA_Loss,该状态也可能是 SACK 导致的。
/* RFC6582 NewReno recovery for non-SACK connection. It simply retransmits
* the next unacked packet upon receiving
* a) three or more DUPACKs to start the fast recovery
* b) an ACK acknowledging new data during the fast recovery.
*/
void tcp_newreno_mark_lost(struct sock *sk, bool snd_una_advanced)
{
const u8 state = inet_csk(sk)->icsk_ca_state;
struct tcp_sock *tp = tcp_sk(sk);
if ((state < TCP_CA_Recovery && tp->sacked_out >= tp->reordering) ||
(state == TCP_CA_Recovery && snd_una_advanced)) {
struct sk_buff *skb = tcp_rtx_queue_head(sk);
u32 mss;
if (TCP_SKB_CB(skb)->sacked & TCPCB_LOST)
return;
mss = tcp_skb_mss(skb);
if (tcp_skb_pcount(skb) > 1 && skb->len > mss)
tcp_fragment(sk, TCP_FRAG_IN_RTX_QUEUE, skb,
mss, mss, GFP_ATOMIC);
tcp_mark_skb_lost(sk, skb);
}
}
对于 non-SACK 的 NewReno 实现,接收超过 3 个 dupACK 就触发快速重传/恢复过程。调用关系为:
tcp_ack()
tcp_fastretrans_alert(num_dupack)
tcp_identify_packet_loss()
tcp_newreno_mark_lost()
tcp_mark_skb_lost()
tcp_mark_skb_lost() 会更新 lost_out 统计(用于估算 in-flght packet 的数目),并且记录首个应当(快速)重传的报文。
tcp_fastretrans_alert() 通过 tcp_enter_recovery() 使得状态机进入 TCP_CA_Recovery。这个在前面的状态机注释中也提到:tcp_fastretrans_alert() is entered: … when arrived ACK is unusual, namely: … Duplicate ACK.
/* Congestion control has updated the cwnd already. So if we're in
* loss recovery then now we do any new sends (for FRTO) or
* retransmits (for CA_Loss or CA_recovery) that make sense.
*/
static void tcp_xmit_recovery(struct sock *sk, int rexmit)
{
struct tcp_sock *tp = tcp_sk(sk);
if (rexmit == REXMIT_NONE || sk->sk_state == TCP_SYN_SENT)
return;
if (unlikely(rexmit == REXMIT_NEW)) {
__tcp_push_pending_frames(sk, tcp_current_mss(sk),
TCP_NAGLE_OFF);
if (after(tp->snd_nxt, tp->high_seq))
return;
tp->frto = 0;
}
tcp_xmit_retransmit_queue(sk);
}
tcp_xmit_recovery() 过程在 tck_ack() 的尾部,当 tck_ack() 函数中已经更新好 cwnd 后,则开始重传处理 retransmit queue
目前来看,这些代码要梳理完整还是得花一段时间。比如 tcp_fastretrans_alert->tcp_try_undo_partial->tcp_undo_cwnd_reduction 进行快速恢复的 undo cwnd 操作,后续有机会再更新吧。
References
RFC5681: TCP Congestion Control
TCP Tahoe: Implementation of the first Congestion Control Algorithm in TCP
The Design and Implementation of the 4.4 BSD Operating System
An Introduction to Computer Networks
Computer Networks: An Open Source Approach
V. Jacobson, “Modified TCP Congestion Avoidance Algorithm,” Technical Report, April 1990