前言
上文已经做了论文阅读以及 mkfs.f2fs初始化调研,现在我们从内核的角度来看 F2FS 的运行时是怎样的:包括文件的创建和读写、GC 以及崩溃恢复。如上文所述,使用的源码是早期 commit,代码的稳定性相对于现在肯定是不足的,但这样更易于理解论文提到的若干特性
文章话题涉及比较宽泛,本人才疏学浅,如有错误还请指正
Initialization
上文分析过 mkfs.f2fs 的格式化行为,到了内核部分则通过 mount() 实现从 VFS 到具体文件系统的初始化,简单来说就是解析外存的数据结构。下面附上 f2fs.txt 对关键数据结构的简要说明:
File System Metadata Structure
------------------------------
F2FS adopts the checkpointing scheme to maintain file system consistency. At
mount time, F2FS first tries to find the last valid checkpoint data by scanning
CP area. In order to reduce the scanning time, F2FS uses only two copies of CP.
One of them always indicates the last valid data, which is called as shadow copy
mechanism. In addition to CP, NAT and SIT also adopt the shadow copy mechanism.
For file system consistency, each CP points to which NAT and SIT copies are
valid, as shown as below.
+--------+----------+---------+
| CP | SIT | NAT |
+--------+----------+---------+
. . . .
. . . .
. . . .
+-------+-------+--------+--------+--------+--------+
| CP #0 | CP #1 | SIT #0 | SIT #1 | NAT #0 | NAT #1 |
+-------+-------+--------+--------+--------+--------+
| ^ ^
| | |
`----------------------------------------'
回调注册
// mount 操作的注册回调为 f2fs_mount()
static struct file_system_type f2fs_fs_type = {
.owner = THIS_MODULE,
.name = "f2fs",
.mount = f2fs_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
static struct dentry *f2fs_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
// 具体文件系统操作为 f2fs_fill_super()
return mount_bdev(fs_type, flags, dev_name, data, f2fs_fill_super);
}
这些注册操作将 F2FS 和 VFS 关联起来,可以说是每一个文件系统的基本操作
关于 VFS 层面的
mount()基本流程可以看这里
主流程
static int f2fs_fill_super(struct super_block *sb, void *data, int silent)
{
struct f2fs_sb_info *sbi;
struct f2fs_super_block *raw_super;
struct buffer_head *raw_super_buf;
struct inode *root;
long err = -EINVAL;
int i;
/* allocate memory for f2fs-specific super block info */
sbi = kzalloc(sizeof(struct f2fs_sb_info), GFP_KERNEL);
if (!sbi)
return -ENOMEM;
/* set a block size */
if (!sb_set_blocksize(sb, F2FS_BLKSIZE)) {
f2fs_msg(sb, KERN_ERR, "unable to set blocksize");
goto free_sbi;
}
/* read f2fs raw super block */
// 通过 sb_bread() 直接读取 block #0 来获取外存 super block 信息
// 其数据保存在 raw_super_buf->b_data
// F2FS_SUPER_OFFSET = 1024
raw_super_buf = sb_bread(sb, 0);
if (!raw_super_buf) {
err = -EIO;
f2fs_msg(sb, KERN_ERR, "unable to read superblock");
goto free_sbi;
}
raw_super = (struct f2fs_super_block *)
((char *)raw_super_buf->b_data + F2FS_SUPER_OFFSET);
/* init some FS parameters */
// main area 的 log 数目(6)
sbi->active_logs = NR_CURSEG_TYPE;
// 用于确认是否允许 gc_thread_func()
set_opt(sbi, BG_GC);
#ifdef CONFIG_F2FS_FS_XATTR
set_opt(sbi, XATTR_USER);
#endif
#ifdef CONFIG_F2FS_FS_POSIX_ACL
set_opt(sbi, POSIX_ACL);
#endif
/* parse mount options */
if (parse_options(sb, sbi, (char *)data))
goto free_sb_buf;
/* sanity checking of raw super */
if (sanity_check_raw_super(sb, raw_super)) {
f2fs_msg(sb, KERN_ERR, "Can't find a valid F2FS filesystem");
goto free_sb_buf;
}
// 填充 VFS 层 struct super_block
sb->s_maxbytes = max_file_size(le32_to_cpu(raw_super->log_blocksize));
sb->s_max_links = F2FS_LINK_MAX;
get_random_bytes(&sbi->s_next_generation, sizeof(u32));
// sops 初始化
sb->s_op = &f2fs_sops;
sb->s_xattr = f2fs_xattr_handlers;
sb->s_export_op = &f2fs_export_ops;
sb->s_magic = F2FS_SUPER_MAGIC;
sb->s_fs_info = sbi;
sb->s_time_gran = 1;
sb->s_flags = (sb->s_flags & ~MS_POSIXACL) |
(test_opt(sbi, POSIX_ACL) ? MS_POSIXACL : 0);
memcpy(sb->s_uuid, raw_super->uuid, sizeof(raw_super->uuid));
/* init f2fs-specific super block info */
// 填充具体文件系统的 super block info
sbi->sb = sb;
sbi->raw_super = raw_super;
sbi->raw_super_buf = raw_super_buf;
mutex_init(&sbi->gc_mutex);
mutex_init(&sbi->write_inode);
mutex_init(&sbi->writepages);
mutex_init(&sbi->cp_mutex);
for (i = 0; i < NR_LOCK_TYPE; i++)
mutex_init(&sbi->fs_lock[i]);
sbi->por_doing = 0;
spin_lock_init(&sbi->stat_lock);
init_rwsem(&sbi->bio_sem);
// 见下方调用
init_sb_info(sbi);
/* get an inode for meta space */
// meta inode 的初始化,实际执行 3 步:
// 0. inode = iget_locked(ino);
// 1. inode->i_mapping->a_ops = &f2fs_meta_aops;
// 2. mapping_set_gfp_mask(inode->i_mapping, GFP_F2FS_ZERO);
sbi->meta_inode = f2fs_iget(sb, F2FS_META_INO(sbi));
if (IS_ERR(sbi->meta_inode)) {
f2fs_msg(sb, KERN_ERR, "Failed to read F2FS meta data inode");
err = PTR_ERR(sbi->meta_inode);
goto free_sb_buf;
}
// 见后续 recovery 章节
err = get_valid_checkpoint(sbi);
if (err) {
f2fs_msg(sb, KERN_ERR, "Failed to get valid F2FS checkpoint");
goto free_meta_inode;
}
/* sanity checking of checkpoint */
err = -EINVAL;
if (sanity_check_ckpt(raw_super, sbi->ckpt)) {
f2fs_msg(sb, KERN_ERR, "Invalid F2FS checkpoint");
goto free_cp;
}
// 从 check point 获取信息填充到 super block
// 可以参考上文 mkfs.f2fs 填入的信息
sbi->total_valid_node_count =
le32_to_cpu(sbi->ckpt->valid_node_count);
sbi->total_valid_inode_count =
le32_to_cpu(sbi->ckpt->valid_inode_count);
sbi->user_block_count = le64_to_cpu(sbi->ckpt->user_block_count);
sbi->total_valid_block_count =
le64_to_cpu(sbi->ckpt->valid_block_count);
sbi->last_valid_block_count = sbi->total_valid_block_count;
sbi->alloc_valid_block_count = 0;
INIT_LIST_HEAD(&sbi->dir_inode_list);
spin_lock_init(&sbi->dir_inode_lock);
// 初始化空的 sbi->orphan_inode_list
init_orphan_info(sbi);
/* setup f2fs internal modules */
// 关联 sbi->sm_info 并初始化 SIT
err = build_segment_manager(sbi);
if (err) {
f2fs_msg(sb, KERN_ERR,
"Failed to initialize F2FS segment manager");
goto free_sm;
}
// 分配并初始化 sbi->nm_info
err = build_node_manager(sbi);
if (err) {
f2fs_msg(sb, KERN_ERR,
"Failed to initialize F2FS node manager");
goto free_nm;
}
// 初始化 struct victim_selection
build_gc_manager(sbi);
/* get an inode for node space */
sbi->node_inode = f2fs_iget(sb, F2FS_NODE_INO(sbi));
if (IS_ERR(sbi->node_inode)) {
f2fs_msg(sb, KERN_ERR, "Failed to read node inode");
err = PTR_ERR(sbi->node_inode);
goto free_nm;
}
/* if there are nt orphan nodes free them */
err = -EINVAL;
if (recover_orphan_inodes(sbi))
goto free_node_inode;
/* read root inode and dentry */
// 分配 root inode
root = f2fs_iget(sb, F2FS_ROOT_INO(sbi));
if (IS_ERR(root)) {
f2fs_msg(sb, KERN_ERR, "Failed to read root inode");
err = PTR_ERR(root);
goto free_node_inode;
}
if (!S_ISDIR(root->i_mode) || !root->i_blocks || !root->i_size)
goto free_root_inode;
// 为 VFS 分配 root dentry
sb->s_root = d_make_root(root); /* allocate root dentry */
if (!sb->s_root) {
err = -ENOMEM;
goto free_root_inode;
}
/* recover fsynced data */
if (!test_opt(sbi, DISABLE_ROLL_FORWARD))
// 见后续 recovery 章节
recover_fsync_data(sbi);
/* After POR, we can run background GC thread */
err = start_gc_thread(sbi);
if (err)
goto fail;
// 非 debug 为空实现
err = f2fs_build_stats(sbi);
if (err)
goto fail;
return 0;
fail:
stop_gc_thread(sbi);
free_root_inode:
dput(sb->s_root);
sb->s_root = NULL;
free_node_inode:
iput(sbi->node_inode);
free_nm:
destroy_node_manager(sbi);
free_sm:
destroy_segment_manager(sbi);
free_cp:
kfree(sbi->ckpt);
free_meta_inode:
make_bad_inode(sbi->meta_inode);
iput(sbi->meta_inode);
free_sb_buf:
brelse(raw_super_buf);
free_sbi:
kfree(sbi);
return err;
}
static void init_sb_info(struct f2fs_sb_info *sbi)
{
struct f2fs_super_block *raw_super = sbi->raw_super;
int i;
sbi->log_sectors_per_block =
le32_to_cpu(raw_super->log_sectors_per_block);
sbi->log_blocksize = le32_to_cpu(raw_super->log_blocksize);
sbi->blocksize = 1 << sbi->log_blocksize;
sbi->log_blocks_per_seg = le32_to_cpu(raw_super->log_blocks_per_seg);
sbi->blocks_per_seg = 1 << sbi->log_blocks_per_seg;
sbi->segs_per_sec = le32_to_cpu(raw_super->segs_per_sec);
sbi->secs_per_zone = le32_to_cpu(raw_super->secs_per_zone);
sbi->total_sections = le32_to_cpu(raw_super->section_count);
sbi->total_node_count =
(le32_to_cpu(raw_super->segment_count_nat) / 2)
* sbi->blocks_per_seg * NAT_ENTRY_PER_BLOCK;
sbi->root_ino_num = le32_to_cpu(raw_super->root_ino);
sbi->node_ino_num = le32_to_cpu(raw_super->node_ino);
sbi->meta_ino_num = le32_to_cpu(raw_super->meta_ino);
for (i = 0; i < NR_COUNT_TYPE; i++)
atomic_set(&sbi->nr_pages[i], 0);
}
super block 的初始化除了内核预先提供的宏作为参数以外,主要入手点是一个预先定义好的 SB area 地址,通过 sb_bread() 即可定位到外存指定 block 的位置,从而开始执行解析/初始化工作
Segment manager
在主流程中存在 smi(即 segment manager info)的初始化 build_segment_manager(),展开如下
int build_segment_manager(struct f2fs_sb_info *sbi)
{
struct f2fs_super_block *raw_super = F2FS_RAW_SUPER(sbi);
struct f2fs_checkpoint *ckpt = F2FS_CKPT(sbi);
struct f2fs_sm_info *sm_info;
int err;
sm_info = kzalloc(sizeof(struct f2fs_sm_info), GFP_KERNEL);
if (!sm_info)
return -ENOMEM;
/* init sm info */
sbi->sm_info = sm_info;
// 初始化 writeback list
INIT_LIST_HEAD(&sm_info->wblist_head);
spin_lock_init(&sm_info->wblist_lock);‘
// 从 check point 获取 segment 相关的信息
sm_info->seg0_blkaddr = le32_to_cpu(raw_super->segment0_blkaddr);
sm_info->main_blkaddr = le32_to_cpu(raw_super->main_blkaddr);
sm_info->segment_count = le32_to_cpu(raw_super->segment_count);
sm_info->reserved_segments = le32_to_cpu(ckpt->rsvd_segment_count);
sm_info->ovp_segments = le32_to_cpu(ckpt->overprov_segment_count);
sm_info->main_segments = le32_to_cpu(raw_super->segment_count_main);
sm_info->ssa_blkaddr = le32_to_cpu(raw_super->ssa_blkaddr);
// 构建 sit,LFS-style 更新需要维护这些信息
err = build_sit_info(sbi);
if (err)
return err;
// 构建 free_i,可用于分配新的 segment
err = build_free_segmap(sbi);
if (err)
return err;
// log 信息
err = build_curseg(sbi);
if (err)
return err;
/* reinit free segmap based on SIT */
build_sit_entries(sbi);
init_free_segmap(sbi);
err = build_dirty_segmap(sbi);
if (err)
return err;
init_min_max_mtime(sbi);
return 0;
}
static int build_sit_info(struct f2fs_sb_info *sbi)
{
struct f2fs_super_block *raw_super = F2FS_RAW_SUPER(sbi);
struct f2fs_checkpoint *ckpt = F2FS_CKPT(sbi);
struct sit_info *sit_i;
unsigned int sit_segs, start;
char *src_bitmap, *dst_bitmap;
unsigned int bitmap_size;
/* allocate memory for SIT information */
sit_i = kzalloc(sizeof(struct sit_info), GFP_KERNEL);
if (!sit_i)
return -ENOMEM;
SM_I(sbi)->sit_info = sit_i;
// TOTAL_SEGS 指的是 sbi->main_segments,也就是 main area 的 segment 个数
// SIT 在内存中分配对应长度到 sentries
sit_i->sentries = vzalloc(TOTAL_SEGS(sbi) * sizeof(struct seg_entry));
if (!sit_i->sentries)
return -ENOMEM;
bitmap_size = f2fs_bitmap_size(TOTAL_SEGS(sbi));
sit_i->dirty_sentries_bitmap = kzalloc(bitmap_size, GFP_KERNEL);
if (!sit_i->dirty_sentries_bitmap)
return -ENOMEM;
// 遍历 segment,为每一个 segment entry 初始化 bitmap
for (start = 0; start < TOTAL_SEGS(sbi); start++) {
sit_i->sentries[start].cur_valid_map
= kzalloc(SIT_VBLOCK_MAP_SIZE, GFP_KERNEL);
sit_i->sentries[start].ckpt_valid_map
= kzalloc(SIT_VBLOCK_MAP_SIZE, GFP_KERNEL);
if (!sit_i->sentries[start].cur_valid_map
|| !sit_i->sentries[start].ckpt_valid_map)
return -ENOMEM;
}
// 非默认情况,略
if (sbi->segs_per_sec > 1) {
sit_i->sec_entries = vzalloc(sbi->total_sections *
sizeof(struct sec_entry));
if (!sit_i->sec_entries)
return -ENOMEM;
}
/* get information related with SIT */
// 得到 SIT 本身需要的 segment,因为有副本(pair segment),所以取一半
sit_segs = le32_to_cpu(raw_super->segment_count_sit) >> 1;
/* setup SIT bitmap from ckeckpoint pack */
bitmap_size = __bitmap_size(sbi, SIT_BITMAP);
// 从 check point 获取一定偏移得到 sit bitmap
src_bitmap = __bitmap_ptr(sbi, SIT_BITMAP);
dst_bitmap = kzalloc(bitmap_size, GFP_KERNEL);
if (!dst_bitmap)
return -ENOMEM;
memcpy(dst_bitmap, src_bitmap, bitmap_size);
/* init SIT information */
// s_ops 只有一个 allocate_segment 策略(allocate_segment_by_default)
sit_i->s_ops = &default_salloc_ops;
sit_i->sit_base_addr = le32_to_cpu(raw_super->sit_blkaddr);
sit_i->sit_blocks = sit_segs << sbi->log_blocks_per_seg;
sit_i->written_valid_blocks = le64_to_cpu(ckpt->valid_block_count);
sit_i->sit_bitmap = dst_bitmap;
sit_i->bitmap_size = bitmap_size;
sit_i->dirty_sentries = 0;
sit_i->sents_per_block = SIT_ENTRY_PER_BLOCK;
sit_i->elapsed_time = le64_to_cpu(sbi->ckpt->elapsed_time);
sit_i->mounted_time = CURRENT_TIME_SEC.tv_sec;
mutex_init(&sit_i->sentry_lock);
return 0;
}
static int build_free_segmap(struct f2fs_sb_info *sbi)
{
struct f2fs_sm_info *sm_info = SM_I(sbi);
// 字面意思,管理 free segmap
// 它会决定何时使用 in-place write
struct free_segmap_info *free_i;
unsigned int bitmap_size, sec_bitmap_size;
/* allocate memory for free segmap information */
free_i = kzalloc(sizeof(struct free_segmap_info), GFP_KERNEL);
if (!free_i)
return -ENOMEM;
SM_I(sbi)->free_info = free_i;
bitmap_size = f2fs_bitmap_size(TOTAL_SEGS(sbi));
free_i->free_segmap = kmalloc(bitmap_size, GFP_KERNEL);
if (!free_i->free_segmap)
return -ENOMEM;
sec_bitmap_size = f2fs_bitmap_size(sbi->total_sections);
free_i->free_secmap = kmalloc(sec_bitmap_size, GFP_KERNEL);
if (!free_i->free_secmap)
return -ENOMEM;
/* set all segments as dirty temporarily */
// 全 1,全都是 dirty
memset(free_i->free_segmap, 0xff, bitmap_size);
memset(free_i->free_secmap, 0xff, sec_bitmap_size);
/* init free segmap information */
free_i->start_segno =
(unsigned int) GET_SEGNO_FROM_SEG0(sbi, sm_info->main_blkaddr);
free_i->free_segments = 0;
free_i->free_sections = 0;
rwlock_init(&free_i->segmap_lock);
return 0;
}
static int build_curseg(struct f2fs_sb_info *sbi)
{
// 管理 6 个 log
struct curseg_info *array;
int i;
array = kzalloc(sizeof(*array) * NR_CURSEG_TYPE, GFP_KERNEL);
if (!array)
return -ENOMEM;
SM_I(sbi)->curseg_array = array;
for (i = 0; i < NR_CURSEG_TYPE; i++) {
mutex_init(&array[i].curseg_mutex);
// 数据结构 struct f2fs_summary_block*,cached summary block
// 每一个 log 有一个形式的 summary block
// NOTE:
// 最终这个 block 写到哪里需要参考 write_sum_page(..., blk_addr)
// 一般来说,blk_addr 就是 SSA 起始地址+segno
//
// NOTE2:
// 一个 summary block 前半是 summary entry,后半是 SIT/NAT journal
array[i].sum_blk = kzalloc(PAGE_CACHE_SIZE, GFP_KERNEL);
if (!array[i].sum_blk)
return -ENOMEM;
array[i].segno = NULL_SEGNO;
array[i].next_blkoff = 0;
}
// 从 check point 得到 summary
// 填充 SM_I(sbi)->curseg_array
// 有点长,先略了
return restore_curseg_summaries(sbi);
}
static void build_sit_entries(struct f2fs_sb_info *sbi)
{
struct sit_info *sit_i = SIT_I(sbi);
struct curseg_info *curseg = CURSEG_I(sbi, CURSEG_COLD_DATA);
struct f2fs_summary_block *sum = curseg->sum_blk;
unsigned int start;
for (start = 0; start < TOTAL_SEGS(sbi); start++) {
struct seg_entry *se = &sit_i->sentries[start];
struct f2fs_sit_block *sit_blk;
struct f2fs_sit_entry sit;
struct page *page;
int i;
mutex_lock(&curseg->curseg_mutex);
for (i = 0; i < sits_in_cursum(sum); i++) {
if (le32_to_cpu(segno_in_journal(sum, i)) == start) {
// 通过 summary block 找到 sit entry
sit = sit_in_journal(sum, i);
mutex_unlock(&curseg->curseg_mutex);
goto got_it;
}
}
mutex_unlock(&curseg->curseg_mutex);
page = get_current_sit_page(sbi, start);
sit_blk = (struct f2fs_sit_block *)page_address(page);
sit = sit_blk->entries[SIT_ENTRY_OFFSET(sit_i, start)];
f2fs_put_page(page, 1);
got_it:
check_block_count(sbi, start, &sit);
seg_info_from_raw_sit(se, &sit);
if (sbi->segs_per_sec > 1) {
struct sec_entry *e = get_sec_entry(sbi, start);
e->valid_blocks += se->valid_blocks;
}
}
}
static void init_free_segmap(struct f2fs_sb_info *sbi)
{
unsigned int start;
int type;
for (start = 0; start < TOTAL_SEGS(sbi); start++) {
struct seg_entry *sentry = get_seg_entry(sbi, start);
if (!sentry->valid_blocks)
__set_free(sbi, start);
}
/* set use the current segments */
for (type = CURSEG_HOT_DATA; type <= CURSEG_COLD_NODE; type++) {
struct curseg_info *curseg_t = CURSEG_I(sbi, type);
__set_test_and_inuse(sbi, curseg_t->segno);
}
}
static inline void __set_test_and_inuse(struct f2fs_sb_info *sbi,
unsigned int segno)
{
struct free_segmap_info *free_i = FREE_I(sbi);
unsigned int secno = segno / sbi->segs_per_sec;
write_lock(&free_i->segmap_lock);
if (!test_and_set_bit(segno, free_i->free_segmap)) {
free_i->free_segments--;
if (!test_and_set_bit(secno, free_i->free_secmap))
free_i->free_sections--;
}
write_unlock(&free_i->segmap_lock);
}
static int build_dirty_segmap(struct f2fs_sb_info *sbi)
{
struct dirty_seglist_info *dirty_i;
unsigned int bitmap_size, i;
/* allocate memory for dirty segments list information */
dirty_i = kzalloc(sizeof(struct dirty_seglist_info), GFP_KERNEL);
if (!dirty_i)
return -ENOMEM;
SM_I(sbi)->dirty_info = dirty_i;
mutex_init(&dirty_i->seglist_lock);
bitmap_size = f2fs_bitmap_size(TOTAL_SEGS(sbi));
for (i = 0; i < NR_DIRTY_TYPE; i++) {
// NOTE:
// 可以通过 dirty_segmap[PRE] 得到 prefree segment
// 详见 check_prefree_segments()
dirty_i->dirty_segmap[i] = kzalloc(bitmap_size, GFP_KERNEL);
if (!dirty_i->dirty_segmap[i])
return -ENOMEM;
}
init_dirty_segmap(sbi);
return init_victim_segmap(sbi);
}
static void init_dirty_segmap(struct f2fs_sb_info *sbi)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
struct free_segmap_info *free_i = FREE_I(sbi);
unsigned int segno = 0, offset = 0;
unsigned short valid_blocks;
while (segno < TOTAL_SEGS(sbi)) {
/* find dirty segment based on free segmap */
segno = find_next_inuse(free_i, TOTAL_SEGS(sbi), offset);
if (segno >= TOTAL_SEGS(sbi))
break;
offset = segno + 1;
valid_blocks = get_valid_blocks(sbi, segno, 0);
if (valid_blocks >= sbi->blocks_per_seg || !valid_blocks)
continue;
mutex_lock(&dirty_i->seglist_lock);
__locate_dirty_segment(sbi, segno, DIRTY);
mutex_unlock(&dirty_i->seglist_lock);
}
}
static int init_victim_segmap(struct f2fs_sb_info *sbi)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
unsigned int bitmap_size = f2fs_bitmap_size(TOTAL_SEGS(sbi));
// 用于 GC 的 victim 标记,见 get_victim_by_default()
dirty_i->victim_segmap[FG_GC] = kzalloc(bitmap_size, GFP_KERNEL);
dirty_i->victim_segmap[BG_GC] = kzalloc(bitmap_size, GFP_KERNEL);
if (!dirty_i->victim_segmap[FG_GC] || !dirty_i->victim_segmap[BG_GC])
return -ENOMEM;
return 0;
}
这里大多数流程要到读写操作才能发挥作用,现阶段就是「混个脸熟」,后面需要再往回看吧
Node manager
node manager 相对简单,简单解析 NAT 信息
int build_node_manager(struct f2fs_sb_info *sbi)
{
int err;
sbi->nm_info = kzalloc(sizeof(struct f2fs_nm_info), GFP_KERNEL);
if (!sbi->nm_info)
return -ENOMEM;
err = init_node_manager(sbi);
if (err)
return err;
// 这里决定 node id 的分配
// 调用方见 Create operation 章节
// 分析见下面
build_free_nids(sbi);
return 0;
}
// 整个函数基本就是直接解析
static int init_node_manager(struct f2fs_sb_info *sbi)
{
struct f2fs_super_block *sb_raw = F2FS_RAW_SUPER(sbi);
struct f2fs_nm_info *nm_i = NM_I(sbi);
unsigned char *version_bitmap;
unsigned int nat_segs, nat_blocks;
nm_i->nat_blkaddr = le32_to_cpu(sb_raw->nat_blkaddr);
/* segment_count_nat includes pair segment so divide to 2. */
nat_segs = le32_to_cpu(sb_raw->segment_count_nat) >> 1;
nat_blocks = nat_segs << le32_to_cpu(sb_raw->log_blocks_per_seg);
nm_i->max_nid = NAT_ENTRY_PER_BLOCK * nat_blocks;
nm_i->fcnt = 0;
nm_i->nat_cnt = 0;
INIT_LIST_HEAD(&nm_i->free_nid_list);
INIT_RADIX_TREE(&nm_i->nat_root, GFP_ATOMIC);
INIT_LIST_HEAD(&nm_i->nat_entries);
INIT_LIST_HEAD(&nm_i->dirty_nat_entries);
mutex_init(&nm_i->build_lock);
spin_lock_init(&nm_i->free_nid_list_lock);
rwlock_init(&nm_i->nat_tree_lock);
nm_i->bitmap_size = __bitmap_size(sbi, NAT_BITMAP);
// 从 root inode 号(3)之后开始,因此 ckpt->next_free_nid = 4
// 这里用于 node id 的分配算法优化
nm_i->init_scan_nid = le32_to_cpu(sbi->ckpt->next_free_nid);
nm_i->next_scan_nid = le32_to_cpu(sbi->ckpt->next_free_nid);
nm_i->nat_bitmap = kzalloc(nm_i->bitmap_size, GFP_KERNEL);
if (!nm_i->nat_bitmap)
return -ENOMEM;
version_bitmap = __bitmap_ptr(sbi, NAT_BITMAP);
if (!version_bitmap)
return -EFAULT;
/* copy version bitmap */
memcpy(nm_i->nat_bitmap, version_bitmap, nm_i->bitmap_size);
return 0;
}
// 组织 free node 的过程
static void build_free_nids(struct f2fs_sb_info *sbi)
{
struct free_nid *fnid, *next_fnid;
struct f2fs_nm_info *nm_i = NM_I(sbi);
struct curseg_info *curseg = CURSEG_I(sbi, CURSEG_HOT_DATA);
struct f2fs_summary_block *sum = curseg->sum_blk;
nid_t nid = 0;
bool is_cycled = false;
// 含义:the number of free node id
int fcnt = 0;
int i;
// 决定 nid 的扫描范围
// next_scan_nid 会在完成后再次赋值,下一次扫描就从这里开始
nid = nm_i->next_scan_nid;
// init_scan_nid 记录这一次开始扫描开始用到的 nid
// 主要是拿来判断取数到最大再循环到 0 的情况
nm_i->init_scan_nid = nid;
// 对 NAT 页进行 readahead 预读操作,避免后续多次 IO
// 大概 4 个 page(见 FREE_NID_PAGES)
ra_nat_pages(sbi, nid);
while (1) {
struct page *page = get_current_nat_page(sbi, nid);
// 进行 per-block 的 entry 遍历
// 如果 nat_blk->entries[i].block_addr 为空地址
// 那么 fcnt += 1
// NOTE:
// 也有些原因导致+=0,比如超过了扫描阈值(由 MAX_FREE_NIDS 宏决定)
//
// /* maximum # of free node ids to produce during build_free_nids */
// #define MAX_FREE_NIDS (NAT_ENTRY_PER_BLOCK * FREE_NID_PAGES) = 455 * 4 = 1820
//
// #define NAT_ENTRY_PER_BLOCK (PAGE_CACHE_SIZE / sizeof(struct f2fs_nat_entry))
//
// /* # of pages to perform readahead before building free nids */
// #define FREE_NID_PAGES 4
fcnt += scan_nat_page(nm_i, page, nid);
f2fs_put_page(page, 1);
// 跨到下一个 block
nid += (NAT_ENTRY_PER_BLOCK - (nid % NAT_ENTRY_PER_BLOCK));
// 模拟循环复用
if (nid >= nm_i->max_nid) {
nid = 0;
is_cycled = true;
}
// 这里扫描到一定数值就立刻停手,下一次再通过 next_scan_nid 扫描
if (fcnt > MAX_FREE_NIDS)
break;
// 这里表示完整跑了一圈都没有凑够 fcnt 最大数,但是已经是目前能收集最多的情况了
if (is_cycled && nm_i->init_scan_nid <= nid)
break;
}
nm_i->next_scan_nid = nid;
/* find free nids from current sum_pages */
mutex_lock(&curseg->curseg_mutex);
for (i = 0; i < nats_in_cursum(sum); i++) {
block_t addr = le32_to_cpu(nat_in_journal(sum, i).block_addr);
nid = le32_to_cpu(nid_in_journal(sum, i));
if (addr == NULL_ADDR)
add_free_nid(nm_i, nid);
else
remove_free_nid(nm_i, nid);
}
mutex_unlock(&curseg->curseg_mutex);
/* remove the free nids from current allocated nids */
list_for_each_entry_safe(fnid, next_fnid, &nm_i->free_nid_list, list) {
struct nat_entry *ne;
read_lock(&nm_i->nat_tree_lock);
// 查找对应 nid 的 nat entry
ne = __lookup_nat_cache(nm_i, fnid->nid);
if (ne && nat_get_blkaddr(ne) != NULL_ADDR)
remove_free_nid(nm_i, fnid->nid);
read_unlock(&nm_i->nat_tree_lock);
}
}
node manager 的关键在于它的 nid freelist 构建(build_free_nids)。它的数据结构是不完整的,只会搜集一定批数(fcnt 统计当前搜集到的 free inode 数目),不足了再次重新构造,是有一定技巧
Create operation
主流程
文件的创建 open(..., O_CREAT) 从 VFS 层 do_sys_open() 开始,其中会调用具体文件系统的 f2fs_create() 来完成实际上的创建
VFS 的调用栈:
do_sys_open do_filp_open path_openat do_last lookup_open vfs_create dir->i_op->create f2fs_create
static int f2fs_create(struct inode *dir, struct dentry *dentry, umode_t mode,
bool excl)
{
struct super_block *sb = dir->i_sb;
struct f2fs_sb_info *sbi = F2FS_SB(sb);
struct inode *inode;
nid_t ino = 0;
int err;
// 见后续 gc 章节
f2fs_balance_fs(sbi);
// 获得 inode 实例:kmemcache 分配 inode,且从 freelist 申请 nid
inode = f2fs_new_inode(dir, mode);
if (IS_ERR(inode))
return PTR_ERR(inode);
if (!test_opt(sbi, DISABLE_EXT_IDENTIFY))
// 设备为 cold
set_cold_file(sbi, inode, dentry->d_name.name);
// 赋值 iop fop aop
inode->i_op = &f2fs_file_inode_operations;
inode->i_fop = &f2fs_file_operations;
inode->i_mapping->a_ops = &f2fs_dblock_aops;
ino = inode->i_ino;
// 关联到 dentry
// 这里会更新 parent metadata
err = f2fs_add_link(dentry, inode);
if (err)
goto out;
// 从 sbi 获取 nm_i,并从中关联的 free list 删除对应空间,让给 ino 使用
alloc_nid_done(sbi, ino);
if (!sbi->por_doing)
// VFS 层函数,使用 inode 信息,构造完整的 dentry
d_instantiate(dentry, inode);
unlock_new_inode(inode);
return 0;
out:
clear_nlink(inode);
unlock_new_inode(inode);
iput(inode);
alloc_nid_failed(sbi, ino);
return err;
}
整体逻辑是很清晰的,即创建 inode,关联 dentry。下面逐步分析内部函数的细节
inode 创建
在主流程中,inode 实例的创建位于 f2fs_new_inode()
static struct inode *f2fs_new_inode(struct inode *dir, umode_t mode)
{
struct super_block *sb = dir->i_sb;
struct f2fs_sb_info *sbi = F2FS_SB(sb);
nid_t ino;
struct inode *inode;
bool nid_free = false;
int err;
// VFS 函数,通过 kmalloc 返回 inode 实例
// 内部会调用 s_op->alloc_inode() 进行初始化
// 对应到 F2FS 就是 f2fs_alloc_inode()
inode = new_inode(sb);
if (!inode)
return ERR_PTR(-ENOMEM);
mutex_lock_op(sbi, NODE_NEW);
// 分配 inode 号,后续存放于 inode->i_ino
if (!alloc_nid(sbi, &ino)) {
mutex_unlock_op(sbi, NODE_NEW);
err = -ENOSPC;
goto fail;
}
mutex_unlock_op(sbi, NODE_NEW);
inode->i_uid = current_fsuid();
if (dir->i_mode & S_ISGID) {
inode->i_gid = dir->i_gid;
if (S_ISDIR(mode))
mode |= S_ISGID;
} else {
inode->i_gid = current_fsgid();
}
inode->i_ino = ino;
inode->i_mode = mode;
inode->i_blocks = 0;
inode->i_mtime = inode->i_atime = inode->i_ctime = CURRENT_TIME;
inode->i_generation = sbi->s_next_generation++;
// 这是 VFS 层的函数
// inode 插入到 VFS 层私有的 inode_hashtable,自身关联 inode->i_hash
// 这样以后可以在内存中通过 inode 号快速查找到 inode
// NOTE:
// 我觉得需要区分一下 inode number(ino)和 node number(nid)
// inode number 是 VFS 可以访问的,我个人理解是一个 file 对应一个 inode number
// 但是 F2FS 是维护 node number 来完成寻址(用一个 ID 来替代绝对地址,解决 wandering tree)
// 因此只要需要寻址的 node block 都会有一个 nid(相比之下 data block 不需要 nid)
// 这里的交集在于 ino 的分配也是通过 nid 得到的(见上方,alloc_nid(..., &ino))
err = insert_inode_locked(inode);
if (err) {
err = -EINVAL;
nid_free = true;
goto out;
}
// 标记脏页,以后回写
mark_inode_dirty(inode);
return inode;
out:
clear_nlink(inode);
unlock_new_inode(inode);
fail:
iput(inode);
if (nid_free)
alloc_nid_failed(sbi, ino);
return ERR_PTR(err);
}
简单来说,f2fs_new_inode() 有以下流程:
- 通过 VFS 层 new_inode() 通过 kmalloc 获得 inode 实例
- 填充必要的具体文件系统参数到 inode
- alloc_nid() 分配 inode->ino
- inode 插入到 VFS 层私有的 inode_hashtable,自身关联 inode->i_hash
- 标记 inode 为 dirty
- 返回 inode 实例
下面来看分配 node id(在 f2fs_new_inode() 这里是 inode 号)的子流程 alloc_nid()
/*
* If this function returns success, caller can obtain a new nid
* from second parameter of this function.
* The returned nid could be used ino as well as nid when inode is created.
*/
bool alloc_nid(struct f2fs_sb_info *sbi, nid_t *nid)
{
// NOTE: 在前面 fill super block 流程中,通过 build_node_manager() 来初始化 nmi
struct f2fs_nm_info *nm_i = NM_I(sbi);
struct free_nid *i = NULL;
struct list_head *this;
retry:
mutex_lock(&nm_i->build_lock);
// fcnt 含义:the number of free node id
if (!nm_i->fcnt) {
/* scan NAT in order to build free nid list */
// 没有 free node 就需要需要通过 NAT 构建
// 这里已经在上面分析过
build_free_nids(sbi);
if (!nm_i->fcnt) {
mutex_unlock(&nm_i->build_lock);
return false;
}
}
mutex_unlock(&nm_i->build_lock);
/*
* We check fcnt again since previous check is racy as
* we didn't hold free_nid_list_lock. So other thread
* could consume all of free nids.
*/
spin_lock(&nm_i->free_nid_list_lock);
if (!nm_i->fcnt) {
spin_unlock(&nm_i->free_nid_list_lock);
goto retry;
}
BUG_ON(list_empty(&nm_i->free_nid_list));
// 遍历 freelist 查找 free_nid
list_for_each(this, &nm_i->free_nid_list) {
i = list_entry(this, struct free_nid, list);
// 用了这个 i,后续 i->state 改为 NID_ALLOC
if (i->state == NID_NEW)
break;
}
BUG_ON(i->state != NID_NEW);
*nid = i->nid;
i->state = NID_ALLOC;
nm_i->fcnt--;
spin_unlock(&nm_i->free_nid_list_lock);
return true;
}
简单来说,inode 号是从 nid freelist 中复用的。它的分配策略其实集中在 build_free_nids() 函数里面,上面已经分析过,是一个带有缓存和截断的构建算法,能减少查找 free nid 的延迟
关联 dentry
分析 f2fs_add_link() 需要了解一下 F2FS 的 dentry 设计(也可以先看上文对 dentry 的简要分析)
Directory Structure
-------------------
A directory entry occupies 11 bytes, which consists of the following attributes.
- hash hash value of the file name
- ino inode number
- len the length of file name
- type file type such as directory, symlink, etc
A dentry block consists of 214 dentry slots and file names. Therein a bitmap is
used to represent whether each dentry is valid or not. A dentry block occupies
4KB with the following composition.
Dentry Block(4 K) = bitmap (27 bytes) + reserved (3 bytes) +
dentries(11 * 214 bytes) + file name (8 * 214 bytes)
[Bucket]
+--------------------------------+
|dentry block 1 | dentry block 2 |
+--------------------------------+
. .
. .
. [Dentry Block Structure: 4KB] .
+--------+----------+----------+------------+
| bitmap | reserved | dentries | file names |
+--------+----------+----------+------------+
[Dentry Block: 4KB] . .
. .
. .
+------+------+-----+------+
| hash | ino | len | type |
+------+------+-----+------+
[Dentry Structure: 11 bytes]
F2FS implements multi-level hash tables for directory structure. Each level has
a hash table with dedicated number of hash buckets as shown below. Note that
"A(2B)" means a bucket includes 2 data blocks.
----------------------
A : bucket
B : block
N : MAX_DIR_HASH_DEPTH
----------------------
level #0 | A(2B)
|
level #1 | A(2B) - A(2B)
|
level #2 | A(2B) - A(2B) - A(2B) - A(2B)
. | . . . .
level #N/2 | A(2B) - A(2B) - A(2B) - A(2B) - A(2B) - ... - A(2B)
. | . . . .
level #N | A(4B) - A(4B) - A(4B) - A(4B) - A(4B) - ... - A(4B)
The number of blocks and buckets are determined by,
,- 2, if n < MAX_DIR_HASH_DEPTH / 2,
# of blocks in level #n = |
`- 4, Otherwise
,- 2^n, if n < MAX_DIR_HASH_DEPTH / 2,
# of buckets in level #n = |
` - 2^((MAX_DIR_HASH_DEPTH / 2) - 1), Otherwise
When F2FS finds a file name in a directory, at first a hash value of the file
name is calculated. Then, F2FS scans the hash table in level #0 to find the
dentry consisting of the file name and its inode number. If not found, F2FS
scans the next hash table in level #1. In this way, F2FS scans hash tables in
each levels incrementally from 1 to N. In each levels F2FS needs to scan only
one bucket determined by the following equation, which shows O(log(# of files))
complexity.
bucket number to scan in level #n = (hash value) % (# of buckets in level #n)
In the case of file creation, F2FS finds empty consecutive slots that cover the
file name. F2FS searches the empty slots in the hash tables of whole levels from
1 to N in the same way as the lookup operation.
The following figure shows an example of two cases holding children.
--------------> Dir <--------------
| |
child child
child - child [hole] - child
child - child - child [hole] - [hole] - child
Case 1: Case 2:
Number of children = 6, Number of children = 3,
File size = 7 File size = 7
文档除了指出上文分析过的 dentry 数据结构以外,还介绍了文件查找用到的多级哈希表:
- 使用 filename 作为哈希计算的 key 从而得到 value
- 使用该 value 遍历至多 \(O(log(\# \ of \ files))\) 层哈希表,实际不超过\(64\)层
- 低层哈希表的 bucket 数目为 \(2^n\),高层为 \(2^{\frac{MAX\_DEPTH}{2}-1}\),其中 \(n\)为层数,最大值为 \(MAX\_DEPTH\)
- 低层哈希表中 bucket 的 block 数目为 \(2\),高层为 \(4\)
- 在查找过程中:
- 每一次遍历通过 \(value \ \% \ nbucket\) 定位到 bucket index,从中找出 filename 和 ino 匹配的 dentry
- 如果不匹配则继续走高层哈希表
- 在创建过程中:
- 定位方式同查找过程
- 但是要定位到空的 slot(每个 dentry block 含有 214 个 dentry slot 即
struct f2fs_dir_entry)
int f2fs_add_link(struct dentry *dentry, struct inode *inode)
{
unsigned int bit_pos;
unsigned int level;
unsigned int current_depth;
unsigned long bidx, block;
f2fs_hash_t dentry_hash;
struct f2fs_dir_entry *de;
unsigned int nbucket, nblock;
// parent directory 对应的 inode
struct inode *dir = dentry->d_parent->d_inode;
struct f2fs_sb_info *sbi = F2FS_SB(dir->i_sb);
const char *name = dentry->d_name.name;
size_t namelen = dentry->d_name.len;
struct page *dentry_page = NULL;
struct f2fs_dentry_block *dentry_blk = NULL;
// #define GET_DENTRY_SLOTS(x) ((x + F2FS_NAME_LEN - 1) >> F2FS_NAME_LEN_BITS)
int slots = GET_DENTRY_SLOTS(namelen);
int err = 0;
int i;
// 使用 filename 作为 hash key
dentry_hash = f2fs_dentry_hash(name, dentry->d_name.len);
level = 0;
// 记录能到达的最高 depth
current_depth = F2FS_I(dir)->i_current_depth;
if (F2FS_I(dir)->chash == dentry_hash) {
level = F2FS_I(dir)->clevel;
F2FS_I(dir)->chash = 0;
}
// 进入到多级哈希表的查找过程
start:
if (current_depth == MAX_DIR_HASH_DEPTH)
return -ENOSPC;
/* Increase the depth, if required */
if (level == current_depth)
++current_depth;
// 按上述公式计算 bucket 数目
nbucket = dir_buckets(level);
// 计算 block 数目
nblock = bucket_blocks(level);
// 定位 block index
bidx = dir_block_index(level, (le32_to_cpu(dentry_hash) % nbucket));
// 在当前 bucket 中遍历 block
for (block = bidx; block <= (bidx + nblock - 1); block++) {
mutex_lock_op(sbi, DENTRY_OPS);
// 为 index = block 分配对应的 data page
dentry_page = get_new_data_page(dir, block, true);
if (IS_ERR(dentry_page)) {
mutex_unlock_op(sbi, DENTRY_OPS);
return PTR_ERR(dentry_page);
}
// TODO 临时映射
// 往 dentry_blk 写入数据,然后对 dentry_page 标记 dirty 就能刷入外存
dentry_blk = kmap(dentry_page);
bit_pos = room_for_filename(dentry_blk, slots);
// NR_DENTRY_IN_BLOCK = 214,一个 dentry block 含有 214 个 dentry slot
if (bit_pos < NR_DENTRY_IN_BLOCK)
// 定位成功,挑出循环
goto add_dentry;
kunmap(dentry_page);
f2fs_put_page(dentry_page, 1);
mutex_unlock_op(sbi, DENTRY_OPS);
}
/* Move to next level to find the empty slot for new dentry */
// 失败定位,继续循环走更高层
++level;
goto start;
// 定位成功
add_dentry:
// 提供 inode 对应的 page(通用函数 grab_cache_page())和对应的 aops
err = init_inode_metadata(inode, dentry);
if (err)
goto fail;
wait_on_page_writeback(dentry_page);
// 初始化 dentry
de = &dentry_blk->dentry[bit_pos];
de->hash_code = dentry_hash;
de->name_len = cpu_to_le16(namelen);
memcpy(dentry_blk->filename[bit_pos], name, namelen);
de->ino = cpu_to_le32(inode->i_ino);
set_de_type(de, inode);
for (i = 0; i < slots; i++)
test_and_set_bit_le(bit_pos + i, &dentry_blk->dentry_bitmap);
set_page_dirty(dentry_page);
// dir 是 parent inode
// 更新 dir 与之关联的信息
update_parent_metadata(dir, inode, current_depth);
/* update parent inode number before releasing dentry page */
F2FS_I(inode)->i_pino = dir->i_ino;
fail:
kunmap(dentry_page);
f2fs_put_page(dentry_page, 1);
mutex_unlock_op(sbi, DENTRY_OPS);
return err;
}
这个子流程主要是通过特定的哈希算法定位并初始化 dentry,还有更新 parent inode 的信息
Write operation
回调注册
在 VFS 层面上,F2FS 用的 f_op 是框架提供的
const struct file_operations f2fs_file_operations = {
.write = do_sync_write,
.aio_write = generic_file_aio_write,
.splice_write = generic_file_splice_write,
};
也就是说从 do_sync_write() 到 generic_file_buffered_write() 都是非常通用的流程
但是真正写入 page 时,即 generic_file_buffered_write() 调用 a_ops->write_begin() 则有所不同
const struct address_space_operations f2fs_dblock_aops = {
.writepage = f2fs_write_data_page,
.writepages = f2fs_write_data_pages,
.write_begin = f2fs_write_begin,
.write_end = nobh_write_end, // 这个也是通用的流程
};
写入主流程
f2fs_write_begin() 为写入操作准备了 page,并通过 pagep 指向它
static int f2fs_write_begin(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata)
{
struct inode *inode = mapping->host;
struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb);
struct page *page;
pgoff_t index = ((unsigned long long) pos) >> PAGE_CACHE_SHIFT;
struct dnode_of_data dn;
int err = 0;
/* for nobh_write_end */
*fsdata = NULL;
// GC 相关,后续章节再讨论
f2fs_balance_fs(sbi);
// 初始化要写的 page(Find or create a page at the given pagecache position)
// 这里保证存在于 page cache 中
page = grab_cache_page_write_begin(mapping, index, flags);
if (!page)
return -ENOMEM;
*pagep = page;
mutex_lock_op(sbi, DATA_NEW);
// 初始化 dnode,用于找到物理地址(data_blkaddr)
set_new_dnode(&dn, inode, NULL, NULL, 0);
err = get_dnode_of_data(&dn, index, 0);
if (err) {
mutex_unlock_op(sbi, DATA_NEW);
f2fs_put_page(page, 1);
return err;
}
if (dn.data_blkaddr == NULL_ADDR) {
err = reserve_new_block(&dn);
if (err) {
f2fs_put_dnode(&dn);
mutex_unlock_op(sbi, DATA_NEW);
f2fs_put_page(page, 1);
return err;
}
}
f2fs_put_dnode(&dn);
mutex_unlock_op(sbi, DATA_NEW);
if ((len == PAGE_CACHE_SIZE) || PageUptodate(page))
return 0;
if ((pos & PAGE_CACHE_MASK) >= i_size_read(inode)) {
unsigned start = pos & (PAGE_CACHE_SIZE - 1);
unsigned end = start + len;
/* Reading beyond i_size is simple: memset to zero */
zero_user_segments(page, 0, start, end, PAGE_CACHE_SIZE);
return 0;
}
// append 操作
if (dn.data_blkaddr == NEW_ADDR) {
// 填 0
zero_user_segment(page, 0, PAGE_CACHE_SIZE);
// overwrite 操作
} else {
// 读出旧的内容
err = f2fs_readpage(sbi, page, dn.data_blkaddr, READ_SYNC);
if (err) {
f2fs_put_page(page, 1);
return err;
}
}
SetPageUptodate(page);
clear_cold_data(page);
return 0;
}
f2fs_write_begin() 这个过程会被 VFS 调用,然后得到 page 的 VFS 将 write(fd, buf, size) 需要写入的 buf 内容拷贝到该 page。VFS 拷贝完成后,还会调用 write_end() 作为写入操作的结束调用,主要是为此前已上锁的 page 进行解锁
写回主流程
普通文件的默认写策略是 writeback,VFS 通过提供 writepage() 等定制点来实现具体文件系统的写回操作。前面已提到 F2FS 使用 f2fs_write_data_page() 和 f2fs_write_data_pages() 来完成这个操作
写回线程的调用路径:
bdi_writeback_thread wb_do_writeback wb_writeback __writeback_single_inode do_writepages a_ops->writepages一般
writepages()是多个页的writepage()类似实现,下面挑个单页流程分析
static int f2fs_write_data_page(struct page *page,
struct writeback_control *wbc)
{
struct inode *inode = page->mapping->host;
struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb);
loff_t i_size = i_size_read(inode);
const pgoff_t end_index = ((unsigned long long) i_size)
>> PAGE_CACHE_SHIFT;
unsigned offset;
int err = 0;
if (page->index < end_index)
goto out;
/*
* If the offset is out-of-range of file size,
* this page does not have to be written to disk.
*/
// 找到要写的地方
offset = i_size & (PAGE_CACHE_SIZE - 1);
if ((page->index >= end_index + 1) || !offset) {
if (S_ISDIR(inode->i_mode)) {
dec_page_count(sbi, F2FS_DIRTY_DENTS);
inode_dec_dirty_dents(inode);
}
goto unlock_out;
}
// [offset, SIZE) 先清零
zero_user_segment(page, offset, PAGE_CACHE_SIZE);
out:
// 如果正在做 recovery,跳过
if (sbi->por_doing)
goto redirty_out;
// writeback controller 的特性
// for_reclaim 在 shrink_page_list() 中被置为 1
// 也就是说内存吃紧且高频数据可能被跳过
if (wbc->for_reclaim && !S_ISDIR(inode->i_mode) && !is_cold_data(page))
goto redirty_out;
mutex_lock_op(sbi, DATA_WRITE);
if (S_ISDIR(inode->i_mode)) {
dec_page_count(sbi, F2FS_DIRTY_DENTS);
inode_dec_dirty_dents(inode);
}
// 实际的写操作
err = do_write_data_page(page);
// 有问题就下次再来
if (err && err != -ENOENT) {
wbc->pages_skipped++;
set_page_dirty(page);
}
mutex_unlock_op(sbi, DATA_WRITE);
if (wbc->for_reclaim)
f2fs_submit_bio(sbi, DATA, true);
if (err == -ENOENT)
goto unlock_out;
clear_cold_data(page);
unlock_page(page);
if (!wbc->for_reclaim && !S_ISDIR(inode->i_mode))
f2fs_balance_fs(sbi);
return 0;
unlock_out:
unlock_page(page);
return (err == -ENOENT) ? 0 : err;
redirty_out:
wbc->pages_skipped++;
set_page_dirty(page);
return AOP_WRITEPAGE_ACTIVATE;
}
block 寻址
上面的写入操作依赖于寻址操作。而寻址取决于 index 是怎么组织的,先看一眼 f2fs.txt
Index Structure
---------------
The key data structure to manage the data locations is a "node". Similar to
traditional file structures, F2FS has three types of node: inode, direct node,
indirect node. F2FS assigns 4KB to an inode block which contains 929 data block
indices, two direct node pointers, two indirect node pointers, and one double
indirect node pointer as described below. One direct node block contains 1018
data blocks, and one indirect node block contains also 1018 node blocks. Thus,
one inode block (i.e., a file) covers:
4KB * (923 + 2 * 1018 + 2 * 1018 * 1018 + 1018 * 1018 * 1018) := 3.94TB.
Inode block (4KB)
|- data (923)
|- direct node (2)
| `- data (1018)
|- indirect node (2)
| ` - direct node (1018)
| `- data (1018)
` - double indirect node (1)
`- indirect node (1018)
` - direct node (1018)
`- data (1018)
Note that, all the node blocks are mapped by NAT which means the location of
each node is translated by the NAT table. In the consideration of the wandering
tree problem, F2FS is able to cut off the propagation of node updates caused by
leaf data writes.
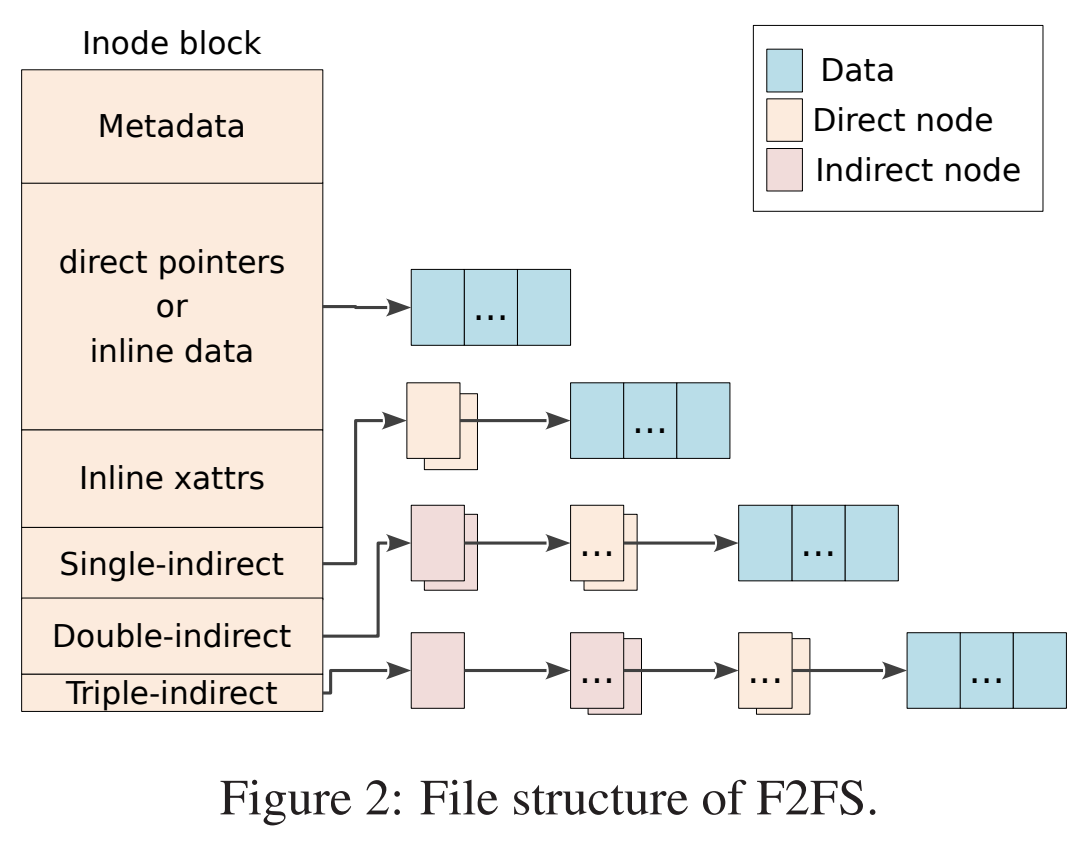 这里(论文图 2)和 f2fs.txt 描述的名词并不一致,但是机制一样
这里(论文图 2)和 f2fs.txt 描述的名词并不一致,但是机制一样
设计哲学在论文阅读篇已经品鉴过就不复读了。这里指出 F2FS 的 index struct 和传统的文件系统相似。在具体的指标上支持单文件约 4TB 的大小,寻址实现上以 inode 为起点,路径分为 direct / indirect / double indirect,因此最深的路径是 4 层,同时这些 node block 都被 NAT 管理。需要注意的是 inode 当中存放的 923 个 data pointer 是直接存放 block 地址,而另外 5 个 node 字段则只记录 node id,这是解决 wandering tree 的关键
现在回归到代码。在上面的流程中出现了 struct dnode_of_data,这是一个寻址用到的数据结构:
/*
* this structure is used as one of function parameters.
* all the information are dedicated to a given direct node block determined
* by the data offset in a file.
*/
struct dnode_of_data {
struct inode *inode; /* vfs inode pointer */
struct page *inode_page; /* its inode page, NULL is possible */
struct page *node_page; /* cached direct node page */
nid_t nid; /* node id of the direct node block */
unsigned int ofs_in_node; /* data offset in the node page */
bool inode_page_locked; /* inode page is locked or not */
block_t data_blkaddr; /* block address of the node block */
};
内部字段比较简单。根据流程,我们需要用它得出 data_blkaddr
构造函数如下,在上面的流程中,传入 set_new_dnode(dn, inode, NULL, NULL, 0)
static inline void set_new_dnode(struct dnode_of_data *dn, struct inode *inode,
struct page *ipage, struct page *npage, nid_t nid)
{
memset(dn, 0, sizeof(*dn));
dn->inode = inode;
dn->inode_page = ipage;
dn->node_page = npage;
dn->nid = nid;
}
后续调用了 get_dnode_of_data(dn, index, 0)
/*
* Caller should call f2fs_put_dnode(dn).
*/
int get_dnode_of_data(struct dnode_of_data *dn, pgoff_t index, int ro)
{
struct f2fs_sb_info *sbi = F2FS_SB(dn->inode->i_sb);
struct page *npage[4];
struct page *parent;
int offset[4];
unsigned int noffset[4];
nid_t nids[4];
int level, i;
int err = 0;
// 核心 block 寻址,callee 传回 offset[]。具体见下方
level = get_node_path(index, offset, noffset);
nids[0] = dn->inode->i_ino;
// 途径 get_node_page -> read_node_page -> f2fs_readpage
// 读流程后面再说吧
// 总之读到了 inode page
npage[0] = get_node_page(sbi, nids[0]);
if (IS_ERR(npage[0]))
return PTR_ERR(npage[0]);
// 就是 inode page
parent = npage[0];
// 使用 page 和 offset 计算出 nid
// 返回 (struct f2fs_node*) page_address(parent)->i.i_nid[offset[0] - NODE_DIR1_BLOCK]
// NOTE:
// f2fs_node 可以表现 3 种形式:inode, direct, and indirect types。这里是 inode(->i)
// i_nid[5] 存放 direct(2) + indirect(2) + d_indirect(2) 的 node id
//
// 但这里为什么如此确定 offset[0] >= NODE_DIR1_BLOCK?
// 看了后期的代码是需要判断的(if level>0),这里早期实现确实是个 bug
nids[1] = get_nid(parent, offset[0], true);
dn->inode_page = npage[0];
dn->inode_page_locked = true;
/* get indirect or direct nodes */
// 总之这里就按层级不断读页
// 一些实现细节:
// - 如果遇到没有 nid 的 block,那就分配
// - page 会尝试预读(ro == true)
//
// NOTE:
// 这里如果是 direct pointer 是不会遍历的,因为此时 level=0
for (i = 1; i <= level; i++) {
bool done = false;
if (!nids[i] && !ro) {
mutex_lock_op(sbi, NODE_NEW);
/* alloc new node */
if (!alloc_nid(sbi, &(nids[i]))) {
mutex_unlock_op(sbi, NODE_NEW);
err = -ENOSPC;
goto release_pages;
}
dn->nid = nids[i];
// 从 page cache 获取 page,如果没有对应 page,允许读页
npage[i] = new_node_page(dn, noffset[i]);
if (IS_ERR(npage[i])) {
alloc_nid_failed(sbi, nids[i]);
mutex_unlock_op(sbi, NODE_NEW);
err = PTR_ERR(npage[i]);
goto release_pages;
}
// 更新 parent->i.i_nid[] (if i==1) 或者 parent->in.nid[] (if i != 1)
set_nid(parent, offset[i - 1], nids[i], i == 1);
alloc_nid_done(sbi, nids[i]);
mutex_unlock_op(sbi, NODE_NEW);
done = true;
} else if (ro && i == level && level > 1) {
npage[i] = get_node_page_ra(parent, offset[i - 1]);
if (IS_ERR(npage[i])) {
err = PTR_ERR(npage[i]);
goto release_pages;
}
done = true;
}
if (i == 1) {
dn->inode_page_locked = false;
unlock_page(parent);
} else {
f2fs_put_page(parent, 1);
}
if (!done) {
npage[i] = get_node_page(sbi, nids[i]);
if (IS_ERR(npage[i])) {
err = PTR_ERR(npage[i]);
f2fs_put_page(npage[0], 0);
goto release_out;
}
}
if (i < level) {
parent = npage[i];
nids[i + 1] = get_nid(parent, offset[i], false);
}
}
// NOTE:
// 这是会写入到 summary entry 的 nid,也就是 parent node
// 比如 direct pointer(level==0)的情况,这里就填入 ino
dn->nid = nids[level];
// 块内偏移
dn->ofs_in_node = offset[level];
dn->node_page = npage[level];
// 最终目标,知道第几层,哪个 page 以及 offset 后,对着数据结构布局解析就能得到
dn->data_blkaddr = datablock_addr(dn->node_page, dn->ofs_in_node);
return 0;
release_pages:
f2fs_put_page(parent, 1);
if (i > 1)
f2fs_put_page(npage[0], 0);
release_out:
dn->inode_page = NULL;
dn->node_page = NULL;
return err;
}
/*
* The maximum depth is four.
* Offset[0] will have raw inode offset.
*/
// 老实说我看不下去这些过程,按照 f2fs.txt 理解即可
static int get_node_path(long block, int offset[4], unsigned int noffset[4])
{
// 923,Address Pointers in an Inode,见前面 Index Structure 说明
const long direct_index = ADDRS_PER_INODE;
// 1018,Address Pointers in a Direct Block
const long direct_blks = ADDRS_PER_BLOCK;
// 1018,Address Pointers in a Direct Block
const long dptrs_per_blk = NIDS_PER_BLOCK;
const long indirect_blks = ADDRS_PER_BLOCK * NIDS_PER_BLOCK;
const long dindirect_blks = indirect_blks * NIDS_PER_BLOCK;
int n = 0;
int level = 0;
noffset[0] = 0;
// NOTE: block 为文件内的 page index
// 小于 923,即论文中的 direct pointers or inline data,第 0 层就足够了
// NOTE2: 初版的 F2FS 似乎没有 inline data
if (block < direct_index) {
offset[n++] = block;
level = 0;
goto got;
}
block -= direct_index;
// 第 0 级扣去 923 后不超第 1 级寻址范围
if (block < direct_blks) {
// [0] 指向 Single-indirect
// NODE_DIR1_BLOCK = (ADDRS_PER_INODE + 1)
offset[n++] = NODE_DIR1_BLOCK;
// offset block 的个数?
noffset[n] = 1;
// 块内偏移量
offset[n++] = block;
level = 1;
goto got;
}
block -= direct_blks;
if (block < direct_blks) {
offset[n++] = NODE_DIR2_BLOCK;
noffset[n] = 2;
offset[n++] = block;
level = 1;
goto got;
}
block -= direct_blks;
if (block < indirect_blks) {
offset[n++] = NODE_IND1_BLOCK;
noffset[n] = 3;
offset[n++] = block / direct_blks;
noffset[n] = 4 + offset[n - 1];
offset[n++] = block % direct_blks;
level = 2;
goto got;
}
block -= indirect_blks;
if (block < indirect_blks) {
offset[n++] = NODE_IND2_BLOCK;
noffset[n] = 4 + dptrs_per_blk;
offset[n++] = block / direct_blks;
noffset[n] = 5 + dptrs_per_blk + offset[n - 1];
offset[n++] = block % direct_blks;
level = 2;
goto got;
}
block -= indirect_blks;
if (block < dindirect_blks) {
offset[n++] = NODE_DIND_BLOCK;
noffset[n] = 5 + (dptrs_per_blk * 2);
offset[n++] = block / indirect_blks;
noffset[n] = 6 + (dptrs_per_blk * 2) +
offset[n - 1] * (dptrs_per_blk + 1);
offset[n++] = (block / direct_blks) % dptrs_per_blk;
noffset[n] = 7 + (dptrs_per_blk * 2) +
offset[n - 2] * (dptrs_per_blk + 1) +
offset[n - 1];
offset[n++] = block % direct_blks;
level = 3;
goto got;
} else {
BUG();
}
got:
return level;
}
简单来说,寻址就是一个按照多级间接块计算 offset 的过程
实际写执行
前面已分析到,F2FS 的 writeback 实际靠 do_write_data_page 完成
int do_write_data_page(struct page *page)
{
struct inode *inode = page->mapping->host;
struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb);
block_t old_blk_addr, new_blk_addr;
struct dnode_of_data dn;
int err = 0;
// 寻址过程,得到 old_blk_addr
set_new_dnode(&dn, inode, NULL, NULL, 0);
err = get_dnode_of_data(&dn, page->index, RDONLY_NODE);
if (err)
return err;
old_blk_addr = dn.data_blkaddr;
/* This page is already truncated */
if (old_blk_addr == NULL_ADDR)
goto out_writepage;
set_page_writeback(page);
/*
* If current allocation needs SSR,
* it had better in-place writes for updated data.
*/
// SSR-style 写操作
// SSR 指的是 Slack Space Recycling
// 含义见 f2fs/segment.h,reuses obsolete space without cleaning operations
//
// 也就是说这里是 in-place update
//
// 需要的条件 need_inplace_update() 如论文描述,
// free section 数目(由 free_i 维护)少于一定阈值时满足
if (old_blk_addr != NEW_ADDR && !is_cold_data(page) &&
need_inplace_update(inode)) {
rewrite_data_page(F2FS_SB(inode->i_sb), page,
old_blk_addr);
// 而这里是 LFS-style 的写操作
} else {
write_data_page(inode, page, &dn,
old_blk_addr, &new_blk_addr);
update_extent_cache(new_blk_addr, &dn);
F2FS_I(inode)->data_version =
le64_to_cpu(F2FS_CKPT(sbi)->checkpoint_ver);
}
out_writepage:
f2fs_put_dnode(&dn);
return err;
}
可以看出实际的写操作是区分为原地写和追加写,在这份实现中其实追加写是临时关掉了(可能是早期实现不太完善),但这不影响分析,后面会继续深入这两种行为
In-place write
void rewrite_data_page(struct f2fs_sb_info *sbi, struct page *page,
block_t old_blk_addr)
{
submit_write_page(sbi, page, old_blk_addr, DATA);
}
static void submit_write_page(struct f2fs_sb_info *sbi, struct page *page,
block_t blk_addr, enum page_type type)
{
struct block_device *bdev = sbi->sb->s_bdev;
verify_block_addr(sbi, blk_addr);
down_write(&sbi->bio_sem);
inc_page_count(sbi, F2FS_WRITEBACK);
// super block 维护 DATA/NODE/META 类型的 bio[] 数组
// last_block_in_bio[] 表示最后的 block 号
if (sbi->bio[type] && sbi->last_block_in_bio[type] != blk_addr - 1)
// 不连续的 page 先提交上去
// false 指的是异步提交,如果是 true 则是 SYNC
// 在这个上下文中,内部大概是一个 submit_bio() 的封装
do_submit_bio(sbi, type, false);
alloc_new:
// 既然没在 sbi 初始化过程找到它的身影,那就是默认为 NULL,先分配
// NOTE: 提交(submit_bio())后,bio 也是回归到 NULL。因此上面不连续的提交后也走这个分支
if (sbi->bio[type] == NULL) {
// 1. kmemcache 分配 f2fs 私有数据结构 struct bio_private,用于 check point 等待唤醒
// 2. 使用内核通用的 bio_alloc() 分配 bio
sbi->bio[type] = f2fs_bio_alloc(bdev, bio_get_nr_vecs(bdev));
sbi->bio[type]->bi_sector = SECTOR_FROM_BLOCK(sbi, blk_addr);
/*
* The end_io will be assigned at the sumbission phase.
* Until then, let bio_add_page() merge consecutive IOs as much
* as possible.
*/
}
// bio 合并 page
if (bio_add_page(sbi->bio[type], page, PAGE_CACHE_SIZE, 0) <
PAGE_CACHE_SIZE) {
do_submit_bio(sbi, type, false);
goto alloc_new;
}
// 记录 last block,尽可能合并提交
sbi->last_block_in_bio[type] = blk_addr;
up_write(&sbi->bio_sem);
}
static void do_submit_bio(struct f2fs_sb_info *sbi,
enum page_type type, bool sync)
{
int rw = sync ? WRITE_SYNC : WRITE;
enum page_type btype = type > META ? META : type;
if (type >= META_FLUSH)
rw = WRITE_FLUSH_FUA;
if (sbi->bio[btype]) {
struct bio_private *p = sbi->bio[btype]->bi_private;
p->sbi = sbi;
// 完成后的回调
// 大概是标记 writeback page 结束,以及处理 check point 细节(唤醒)
sbi->bio[btype]->bi_end_io = f2fs_end_io_write;
// check point 操作才会有这个类型
if (type == META_FLUSH) {
DECLARE_COMPLETION_ONSTACK(wait);
p->is_sync = true;
p->wait = &wait;
submit_bio(rw, sbi->bio[btype]);
wait_for_completion(&wait);
// 其它类型就是一个 submit_bio() 过程
} else {
p->is_sync = false;
submit_bio(rw, sbi->bio[btype]);
}
// 提交完后对应 bio 就置空
sbi->bio[btype] = NULL;
}
}
Append write
在追加写中,new_blkaddr 是由 callee 而非 caller 指定的,因此执行过程后调用方才能得知新的追加地址
void write_data_page(struct inode *inode, struct page *page,
struct dnode_of_data *dn, block_t old_blkaddr,
block_t *new_blkaddr)
{
struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb);
struct f2fs_summary sum;
struct node_info ni;
BUG_ON(old_blkaddr == NULL_ADDR);
get_node_info(sbi, dn->nid, &ni);
// 初始化 summary entry
set_summary(&sum, dn->nid, dn->ofs_in_node, ni.version);
do_write_page(sbi, page, old_blkaddr,
new_blkaddr, &sum, DATA);
}
static inline void set_summary(struct f2fs_summary *sum, nid_t nid,
unsigned int ofs_in_node, unsigned char version)
{
sum->nid = cpu_to_le32(nid);
sum->ofs_in_node = cpu_to_le16(ofs_in_node);
sum->version = version;
}
static void do_write_page(struct f2fs_sb_info *sbi, struct page *page,
block_t old_blkaddr, block_t *new_blkaddr,
struct f2fs_summary *sum, enum page_type p_type)
{
struct sit_info *sit_i = SIT_I(sbi);
struct curseg_info *curseg;
unsigned int old_cursegno;
int type;
// 返回诸如 CURSEG_HOT_DATA 等类型
type = __get_segment_type(page, p_type);
// 通过 SM_I(sbi)->curseg_array + type 得到
curseg = CURSEG_I(sbi, type);
mutex_lock(&curseg->curseg_mutex);
// #define NEXT_FREE_BLKADDR(sbi, curseg) \
// (START_BLOCK(sbi, curseg->segno) + curseg->next_blkoff)
// next_blkoff 决定新的地址
*new_blkaddr = NEXT_FREE_BLKADDR(sbi, curseg);
old_cursegno = curseg->segno;
/*
* __add_sum_entry should be resided under the curseg_mutex
* because, this function updates a summary entry in the
* current summary block.
*/
// curseg->sum_blk + next_blkoff*sizeof(f2fs_summary) 后面 memcpy 拼接 sum
__add_sum_entry(sbi, type, sum, curseg->next_blkoff);
mutex_lock(&sit_i->sentry_lock);
// 简单来说,如果是 LFS-style 的话,更新 next 就是简单 +1
// SSR-style 感兴趣自己看吧
__refresh_next_blkoff(sbi, curseg);
// alloc_type: 枚举值,LFS 或者 SSR
sbi->block_count[curseg->alloc_type]++;
/*
* SIT information should be updated before segment allocation,
* since SSR needs latest valid block information.
*/
// 见 SIT update 子流程,主要维护对应 segment entry 的 bitmap
refresh_sit_entry(sbi, old_blkaddr, *new_blkaddr);
// 子函数判断 curseg->next_blkoff < sbi->blocks_per_seg
// 在 1 个 segment 内分配是有极限的。要想超越极限,那就用 2 个 semgnet
if (!__has_curseg_space(sbi, type))
sit_i->s_ops->allocate_segment(sbi, type, false);
locate_dirty_segment(sbi, old_cursegno);
locate_dirty_segment(sbi, GET_SEGNO(sbi, old_blkaddr));
mutex_unlock(&sit_i->sentry_lock);
if (p_type == NODE)
fill_node_footer_blkaddr(page, NEXT_FREE_BLKADDR(sbi, curseg));
/* writeout dirty page into bdev */
// 殊途同归,这个过程在 In-place write 已经分析过
submit_write_page(sbi, page, *new_blkaddr, p_type);
mutex_unlock(&curseg->curseg_mutex);
}
SIT update
static void refresh_sit_entry(struct f2fs_sb_info *sbi,
block_t old_blkaddr, block_t new_blkaddr)
{
update_sit_entry(sbi, new_blkaddr, 1);
// GET_SEGNO 一般展开为 GET_L2R_SEGNO(FREE_I(sbi), GET_SEGNO_FROM_SEG0(sbi, blk_addr))
//
// #define GET_SEGNO_FROM_SEG0(sbi, blk_addr) \
// (GET_SEGOFF_FROM_SEG0(sbi, blk_addr) >> sbi->log_blocks_per_seg)
// #define GET_SEGOFF_FROM_SEG0(sbi, blk_addr) \
// ((blk_addr) - SM_I(sbi)->seg0_blkaddr)
//
// /* V: Logical segment # in volume, R: Relative segment # in main area */
// #define GET_L2R_SEGNO(free_i, segno) (segno - free_i->start_segno)
//
// 最终结果
// ((((blk_addr) - SM_I(sbi)->seg0_blkaddr) >> sbi->log_blocks_per_seg)
// - FREE_I(sbi)->start_segno)
if (GET_SEGNO(sbi, old_blkaddr) != NULL_SEGNO)
update_sit_entry(sbi, old_blkaddr, -1);
}
update_sit_entry() 下面再分析,先看 GET_SEGNO(sbi, blk_addr) 的行为。它最后得到的结果是:
((((blk_addr) - SM_I(sbi)->seg0_blkaddr) >> sbi->log_blocks_per_seg) - FREE_I(sbi)->start_segno)
这里就需要看 seg0_blkaddr 和 start_segno 是什么
上文在初始化过程中得知 seg0_blkaddr 是 start block address of segment 0(sm_info 读取 segment0_blkaddr 的信息),segment0_blkaddr 在 mkfs.f2fs 初始化过程为:
super_block.segment0_blkaddr =
cpu_to_le32(zone_align_start_offset / blk_size_bytes); // 换算成 block 单位
zone_align_start_offset =
(f2fs_params.start_sector * DEFAULT_SECTOR_SIZE + // 这里默认是 0
F2FS_SUPER_OFFSET * F2FS_BLKSIZE + // 这里也是 0
sizeof(struct f2fs_super_block) * 2 + // 算上 2 个 super block
zone_size_bytes - 1) / zone_size_bytes * zone_size_bytes - // 对 zone_size_bytes 上取整
f2fs_params.start_sector * DEFAULT_SECTOR_SIZE; // 这里是 0
而 start_segno 是 free_i 读取 GET_SEGNO_FROM_SEG0(sbi, sm_info->main_blkaddr) 得到的,同样补充一下 main_blkaddr 在 mkfs.f2fs 的初始化过程:
// 按照 layout 图去看就是 main area 接着在 ssa 后面
super_block.main_blkaddr = cpu_to_le32(
le32_to_cpu(super_block.ssa_blkaddr) +
(le32_to_cpu(super_block.segment_count_ssa) *
f2fs_params.blks_per_seg));
// ssa 在 nat 后面,如此类推
super_block.ssa_blkaddr = cpu_to_le32(
le32_to_cpu(super_block.nat_blkaddr) +
le32_to_cpu(super_block.segment_count_nat) *
f2fs_params.blks_per_seg);
super_block.nat_blkaddr = cpu_to_le32(
le32_to_cpu(super_block.sit_blkaddr) +
(le32_to_cpu(super_block.segment_count_sit) *
f2fs_params.blks_per_seg));
很显然 segment0_blkaddr 是 512,因为是按 zone 单位(2MB)对齐且换算成 block 单位(4KB);main_blkaddr 我就不算了,在 gdb 调试中得出 5120,就看每个 area 占几个 segment(segment_count_*)
总之,seg0_blkaddr 表示 super block 后面且与 zone 对齐过的起始地址,一般来说应该对应着 check point 起始地址;start_segno 是 main area 起始换算成 segment 单位后的结果
水了一大段,后面开始正式看如何更新 SIT
static void update_sit_entry(struct f2fs_sb_info *sbi, block_t blkaddr, int del)
{
struct seg_entry *se;
unsigned int segno, offset;
long int new_vblocks;
// 换算单位 block->segment
segno = GET_SEGNO(sbi, blkaddr);
// 返回&sit_i->sentries[segno]
// sentries 初始化见前面 build_sit_info()
// 总之要 semgnet entry 是可以随机访问的
se = get_seg_entry(sbi, segno);
// TODO valid_blocks
new_vblocks = se->valid_blocks + del;
// segment 内 block offset
offset = GET_SEGOFF_FROM_SEG0(sbi, blkaddr) & (sbi->blocks_per_seg - 1);
BUG_ON((new_vblocks >> (sizeof(unsigned short) << 3) ||
(new_vblocks > sbi->blocks_per_seg)));
// 初始化 se valid_blocks
se->valid_blocks = new_vblocks;
se->mtime = get_mtime(sbi);
// 因为是刚刚改动的,所以整个 segment 中是 max
SIT_I(sbi)->max_mtime = se->mtime;
/* Update valid block bitmap */
// del 用于更新 valid map
if (del > 0) {
// 要删除的才 set bit 为 1,返回 set bit 前的值
if (f2fs_set_bit(offset, se->cur_valid_map))
BUG();
} else {
if (!f2fs_clear_bit(offset, se->cur_valid_map))
BUG();
}
// 如果和 check point 对比发现有差异
if (!f2fs_test_bit(offset, se->ckpt_valid_map))
// 那就维护新的总数,+1 或者 -1
// NOTE: 在 GC 过程中,SSR-style 直接使用该值作为 cost 判断依据
se->ckpt_valid_blocks += del;
// 维护 sit_i 的 dirty_sentries_bitmap 和 dirty_sentries
__mark_sit_entry_dirty(sbi, segno);
/* update total number of valid blocks to be written in ckpt area */
// 这个值会应用到后续 check point
SIT_I(sbi)->written_valid_blocks += del;
// 略
if (sbi->segs_per_sec > 1)
get_sec_entry(sbi, segno)->valid_blocks += del;
}
static void __mark_sit_entry_dirty(struct f2fs_sb_info *sbi, unsigned int segno)
{
struct sit_info *sit_i = SIT_I(sbi);
if (!__test_and_set_bit(segno, sit_i->dirty_sentries_bitmap))
sit_i->dirty_sentries++;
}
SIT 的维护思路很简单,一是换算单位到 segment 并在线性表中找到 segment entry,二是更新 entry 当中的 bitmap 信息(存在新旧地址的差异,那就一个 setbit 另一个 clearbit),然后给 check point 铺路。
Segment allocation
在 append write 当中由于是追加行为,因此会涉及到单个 segment 已满需要新增的情况
static const struct segment_allocation default_salloc_ops = {
.allocate_segment = allocate_segment_by_default,
};
/*
* flush out current segment and replace it with new segment
* This function should be returned with success, otherwise BUG
*/
static void allocate_segment_by_default(struct f2fs_sb_info *sbi,
int type, bool force)
{
struct curseg_info *curseg = CURSEG_I(sbi, type);
unsigned int ofs_unit;
if (force) {
new_curseg(sbi, type, true);
goto out;
}
ofs_unit = need_SSR(sbi) ? 1 : sbi->segs_per_sec;
// TODO next_segno
// 涉及 dirty seglist,需要了解 Delete operation 或者 GC
curseg->next_segno = check_prefree_segments(sbi, ofs_unit, type);
// 如果有 next segment,那就直接复用
if (curseg->next_segno != NULL_SEGNO)
change_curseg(sbi, type, false);
// 没有的话那就看 type 决定策略。一般来说,LFS-style 就是新增一个 segment
else if (type == CURSEG_WARM_NODE)
new_curseg(sbi, type, false);
else if (need_SSR(sbi) && get_ssr_segment(sbi, type))
change_curseg(sbi, type, true);
else
new_curseg(sbi, type, false);
out:
sbi->segment_count[curseg->alloc_type]++;
}
/*
* This function always allocates a used segment (from dirty seglist) by SSR
* manner, so it should recover the existing segment information of valid blocks
*/
static void change_curseg(struct f2fs_sb_info *sbi, int type, bool reuse)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
struct curseg_info *curseg = CURSEG_I(sbi, type);
unsigned int new_segno = curseg->next_segno;
struct f2fs_summary_block *sum_node;
struct page *sum_page;
write_sum_page(sbi, curseg->sum_blk,
GET_SUM_BLOCK(sbi, curseg->segno));
__set_test_and_inuse(sbi, new_segno);
mutex_lock(&dirty_i->seglist_lock);
__remove_dirty_segment(sbi, new_segno, PRE);
__remove_dirty_segment(sbi, new_segno, DIRTY);
mutex_unlock(&dirty_i->seglist_lock);
reset_curseg(sbi, type, 1);
curseg->alloc_type = SSR;
__next_free_blkoff(sbi, curseg, 0);
if (reuse) {
sum_page = get_sum_page(sbi, new_segno);
sum_node = (struct f2fs_summary_block *)page_address(sum_page);
memcpy(curseg->sum_blk, sum_node, SUM_ENTRY_SIZE);
f2fs_put_page(sum_page, 1);
}
}
/*
* Allocate a current working segment.
* This function always allocates a free segment in LFS manner.
*/
static void new_curseg(struct f2fs_sb_info *sbi, int type, bool new_sec)
{
struct curseg_info *curseg = CURSEG_I(sbi, type);
unsigned int segno = curseg->segno;
int dir = ALLOC_LEFT;
// #define GET_SUM_BLOCK(sbi, segno) ((sbi->sm_info->ssa_blkaddr) + segno)
// 没太理解,这里按理应该是:
// 将 curseg_info 中的 f2fs_summary_block 同步到 page cache 中
// 但是实现上反而是:
// memcpy(kaddr, sum_blk, PAGE_CACHE_SIZE)
// <del>这不是反了吗?</del>哦确实没错
write_sum_page(sbi, curseg->sum_blk,
GET_SUM_BLOCK(sbi, curseg->segno));
// DATA 分配方向,HOT 往左,WARM/COLD 往右
if (type == CURSEG_WARM_DATA || type == CURSEG_COLD_DATA)
dir = ALLOC_RIGHT;
if (test_opt(sbi, NOHEAP))
dir = ALLOC_RIGHT;
get_new_segment(sbi, &segno, new_sec, dir);
// 得到新的 segno
curseg->next_segno = segno;
reset_curseg(sbi, type, 1);
curseg->alloc_type = LFS;
}
/*
* Find a new segment from the free segments bitmap to right order
* This function should be returned with success, otherwise BUG
*/
static void get_new_segment(struct f2fs_sb_info *sbi,
unsigned int *newseg, bool new_sec, int dir)
{
struct free_segmap_info *free_i = FREE_I(sbi);
// (一些无关紧要的)NOTE:
// 虽然 segment 和 section 是同一单位
// 但是 section count 一般只统计 main area
// 详见前面 mkfs 文章的 dump 信息
//
// 得到 section 总数目
unsigned int total_secs = sbi->total_sections;
unsigned int segno, secno, zoneno;
// 换算到 zone
unsigned int total_zones = sbi->total_sections / sbi->secs_per_zone;
// 当前上下文的 newseg 是旧的 curseg->segno
unsigned int hint = *newseg / sbi->segs_per_sec;
unsigned int old_zoneno = GET_ZONENO_FROM_SEGNO(sbi, *newseg);
unsigned int left_start = hint;
bool init = true;
int go_left = 0;
int i;
write_lock(&free_i->segmap_lock);
if (!new_sec && ((*newseg + 1) % sbi->segs_per_sec)) {
// NOTE:
// 关于 find_next_zero_bit() 的签名
// 第二个参数是 bitmap size,第三个参数是开始查找的起始位置
segno = find_next_zero_bit(free_i->free_segmap,
TOTAL_SEGS(sbi), *newseg + 1);
if (segno < TOTAL_SEGS(sbi))
goto got_it;
}
find_other_zone:
// 查找下一个可用 section
secno = find_next_zero_bit(free_i->free_secmap, total_secs, hint);
// 没找到?
if (secno >= total_secs) {
// 循环左移查找
if (dir == ALLOC_RIGHT) {
secno = find_next_zero_bit(free_i->free_secmap,
total_secs, 0);
BUG_ON(secno >= total_secs);
} else {
go_left = 1;
left_start = hint - 1;
}
}
if (go_left == 0)
goto skip_left;
// 右边不行再往左找
while (test_bit(left_start, free_i->free_secmap)) {
if (left_start > 0) {
left_start--;
continue;
}
left_start = find_next_zero_bit(free_i->free_secmap,
total_secs, 0);
BUG_ON(left_start >= total_secs);
break;
}
// 定位到 0-bit
secno = left_start;
skip_left:
hint = secno;
segno = secno * sbi->segs_per_sec;
zoneno = secno / sbi->secs_per_zone;
/* give up on finding another zone */
if (!init)
goto got_it;
// 默认走这里
if (sbi->secs_per_zone == 1)
goto got_it;
if (zoneno == old_zoneno)
goto got_it;
if (dir == ALLOC_LEFT) {
if (!go_left && zoneno + 1 >= total_zones)
goto got_it;
if (go_left && zoneno == 0)
goto got_it;
}
for (i = 0; i < NR_CURSEG_TYPE; i++)
if (CURSEG_I(sbi, i)->zone == zoneno)
break;
if (i < NR_CURSEG_TYPE) {
/* zone is in user, try another */
if (go_left)
hint = zoneno * sbi->secs_per_zone - 1;
else if (zoneno + 1 >= total_zones)
hint = 0;
else
hint = (zoneno + 1) * sbi->secs_per_zone;
init = false;
goto find_other_zone;
}
got_it:
/* set it as dirty segment in free segmap */
BUG_ON(test_bit(segno, free_i->free_segmap));
// 更新 free segmap:setbit 且 free_i->free_segments--(&& free_sections--)
__set_inuse(sbi, segno);
*newseg = segno;
write_unlock(&free_i->segmap_lock);
}
// 一些基本的初始化
static void reset_curseg(struct f2fs_sb_info *sbi, int type, int modified)
{
struct curseg_info *curseg = CURSEG_I(sbi, type);
struct summary_footer *sum_footer;
curseg->segno = curseg->next_segno;
curseg->zone = GET_ZONENO_FROM_SEGNO(sbi, curseg->segno);
// 因为是全新的 segment,所以是 0
curseg->next_blkoff = 0;
// 通过链表形式找到同一 log 的所有 segment,old seg 的 next_segno 就是指向现在的 curseg
curseg->next_segno = NULL_SEGNO;
// footer 在前面 mkfs 聊过,区分类型和校验相关
sum_footer = &(curseg->sum_blk->footer);
memset(sum_footer, 0, sizeof(struct summary_footer));
if (IS_DATASEG(type))
SET_SUM_TYPE(sum_footer, SUM_TYPE_DATA);
if (IS_NODESEG(type))
SET_SUM_TYPE(sum_footer, SUM_TYPE_NODE);
__set_sit_entry_type(sbi, type, curseg->segno, modified);
}
segment 的分配思路简单,但是实现看着复杂,基本上就是尝试复用 segment,以及 free segmap 当中区分方向的查找空闲位置
Read operation
回调注册
和写流程类似,F2FS 在 f_op 使用通用的读机制(就不列出了),而 a_op 是 F2FS 内部实现的
const struct address_space_operations f2fs_dblock_aops = {
.readpage = f2fs_read_data_page,
.readpages = f2fs_read_data_pages,
// ...
};
static int f2fs_read_data_page(struct file *file, struct page *page)
{
// 好吧,起码 get_block_t 回调确实是 F2FS 写的
return mpage_readpage(page, get_data_block_ro);
}
其关键在 get_block_t 回调 get_data_block_ro()
主流程
/*
* This function should be used by the data read flow only where it
* does not check the "create" flag that indicates block allocation.
* The reason for this special functionality is to exploit VFS readahead
* mechanism.
*/
static int get_data_block_ro(struct inode *inode, sector_t iblock,
struct buffer_head *bh_result, int create)
{
unsigned int blkbits = inode->i_sb->s_blocksize_bits;
unsigned maxblocks = bh_result->b_size >> blkbits;
struct dnode_of_data dn;
pgoff_t pgofs;
int err;
/* Get the page offset from the block offset(iblock) */
pgofs = (pgoff_t)(iblock >> (PAGE_CACHE_SHIFT - blkbits));
if (check_extent_cache(inode, pgofs, bh_result))
return 0;
/* When reading holes, we need its node page */
set_new_dnode(&dn, inode, NULL, NULL, 0);
err = get_dnode_of_data(&dn, pgofs, RDONLY_NODE);
if (err)
return (err == -ENOENT) ? 0 : err;
/* It does not support data allocation */
BUG_ON(create);
if (dn.data_blkaddr != NEW_ADDR && dn.data_blkaddr != NULL_ADDR) {
int i;
unsigned int end_offset;
end_offset = IS_INODE(dn.node_page) ?
ADDRS_PER_INODE :
ADDRS_PER_BLOCK;
clear_buffer_new(bh_result);
/* Give more consecutive addresses for the read ahead */
for (i = 0; i < end_offset - dn.ofs_in_node; i++)
if (((datablock_addr(dn.node_page,
dn.ofs_in_node + i))
!= (dn.data_blkaddr + i)) || maxblocks == i)
break;
map_bh(bh_result, inode->i_sb, dn.data_blkaddr);
bh_result->b_size = (i << blkbits);
}
f2fs_put_dnode(&dn);
return 0;
}
相比波澜壮阔的写流程,F2FS 读流程似乎没啥可说的,无非就是寻址再填上 buffer_head ……
为了避免尴尬,感兴趣可以看一下我之前写的VFS 读流程还有预读机制
Delete operation
Garbage collection
F2FS 的 GC 入口在 f2fs_gc()。这个函数的 caller 有 2 个:
- 一个是前面接触到的
f2fs_balance_fs() - 另一个是后台
kthread执行的gc_thread_func()
Background GC
后台 GC 是个和 GC 主流程关联性不大的话题,先简单梳理一下
前面的 f2fs_fill_super() 初始化流程可以看到,它执行了 start_gc_thread()
int start_gc_thread(struct f2fs_sb_info *sbi)
{
// 一个 kthread 封装类
struct f2fs_gc_kthread *gc_th;
gc_th = kmalloc(sizeof(struct f2fs_gc_kthread), GFP_KERNEL);
if (!gc_th)
return -ENOMEM;
sbi->gc_thread = gc_th;
init_waitqueue_head(&sbi->gc_thread->gc_wait_queue_head);
// kthread 的任务是 gc_thread_func
sbi->gc_thread->f2fs_gc_task = kthread_run(gc_thread_func, sbi,
GC_THREAD_NAME);
if (IS_ERR(gc_th->f2fs_gc_task)) {
kfree(gc_th);
return -ENOMEM;
}
return 0;
}
static int gc_thread_func(void *data)
{
struct f2fs_sb_info *sbi = data;
wait_queue_head_t *wq = &sbi->gc_thread->gc_wait_queue_head;
long wait_ms;
// GC_THREAD_MIN_SLEEP_TIME: 10s
wait_ms = GC_THREAD_MIN_SLEEP_TIME;
do {
// freezer 特性,如果系统处于休眠则等待
if (try_to_freeze())
continue;
else
// 等待 wait_ms 时间,这个数值会在后续动态调节
wait_event_interruptible_timeout(*wq,
kthread_should_stop(),
msecs_to_jiffies(wait_ms));
if (kthread_should_stop())
break;
// 如果没有足够 free section,会强制进入主流程 f2fs_gc()
// 否则什么都不干
f2fs_balance_fs(sbi);
if (!test_opt(sbi, BG_GC))
continue;
/*
* [GC triggering condition]
* 0. GC is not conducted currently.
* 1. There are enough dirty segments.
* 2. IO subsystem is idle by checking the # of writeback pages.
* 3. IO subsystem is idle by checking the # of requests in
* bdev's request list.
*
* Note) We have to avoid triggering GCs too much frequently.
* Because it is possible that some segments can be
* invalidated soon after by user update or deletion.
* So, I'd like to wait some time to collect dirty segments.
*/
if (!mutex_trylock(&sbi->gc_mutex))
continue;
if (!is_idle(sbi)) {
wait_ms = increase_sleep_time(wait_ms);
mutex_unlock(&sbi->gc_mutex);
continue;
}
// invalid(没写过的 block)超 40%,就会缩减等待时间,提高后台频率
if (has_enough_invalid_blocks(sbi))
// 减 10s,但不超过 10s 阈值
wait_ms = decrease_sleep_time(wait_ms);
else
// 加 10s,但不超过 30s 阈值
wait_ms = increase_sleep_time(wait_ms);
sbi->bg_gc++;
// 进入 GC 主流程
if (f2fs_gc(sbi) == GC_NONE)
// 作者的意思应该是没有发生 GC,可能的情况是:
// - super block 尚未完成初始化
// - victim 挑选失败(比如每一个 segno 都成本过高)
//
// GC_THREAD_NOGC_SLEEP_TIME: 10s
wait_ms = GC_THREAD_NOGC_SLEEP_TIME;
else if (wait_ms == GC_THREAD_NOGC_SLEEP_TIME)
// 如果上一次走了 NOGC 的情况,这次强制降低频率
// GC_THREAD_MAX_SLEEP_TIME: 30s
wait_ms = GC_THREAD_MAX_SLEEP_TIME;
} while (!kthread_should_stop());
return 0;
}
static inline bool has_enough_invalid_blocks(struct f2fs_sb_info *sbi)
{
// 没有写过的 block 数目
// NOTE:
// LFS 写操作下,旧 block 不算入 written
// 详见 update_sit_entry() 的 written_valid_blocks 更新
block_t invalid_user_blocks = sbi->user_block_count -
written_block_count(sbi);
/*
* Background GC is triggered with the following condition.
* 1. There are a number of invalid blocks.
* 2. There is not enough free space.
*/
// invalid user 超过了 40% 总数,free user 小于 40% 总数
if (invalid_user_blocks > limit_invalid_user_blocks(sbi) &&
free_user_blocks(sbi) < limit_free_user_blocks(sbi))
return true;
return false;
}
static inline long decrease_sleep_time(long wait)
{
// 减去 10s,但不得低于 10s
wait -= GC_THREAD_MIN_SLEEP_TIME;
if (wait <= GC_THREAD_MIN_SLEEP_TIME)
wait = GC_THREAD_MIN_SLEEP_TIME;
return wait;
}
static inline long increase_sleep_time(long wait)
{
// 加上 10s,但不得高于 30s
wait += GC_THREAD_MIN_SLEEP_TIME;
if (wait > GC_THREAD_MAX_SLEEP_TIME)
wait = GC_THREAD_MAX_SLEEP_TIME;
return wait;
}
可以看出后台 GC 是一个动态调整 GC 频率的任务,它会参考当前 block 使用情况和上一次 GC 反馈结果,每 \([10, 30]\) 秒执行一次 GC 任务
主流程
不管前台 GC 还是后台 GC,都会进入到统一的 GC 接口 f2fs_gc()。后台 GC 的情况在前面已经说明了;而前台 GC 可能会通过 f2fs_balance_fs() 在多个流程插入,只要 free section 低于预期,就会进入主流程
int f2fs_gc(struct f2fs_sb_info *sbi)
{
struct list_head ilist;
unsigned int segno, i;
int gc_type = BG_GC;
int gc_status = GC_NONE;
INIT_LIST_HEAD(&ilist);
gc_more:
// 不清楚 MS_ACTIVE 具体含义
// 但是在 mount 过程中 VFS 会加上这个标记
if (!(sbi->sb->s_flags & MS_ACTIVE))
goto stop;
// 如果没有足够的 free section
// 那就改为 FG GC,默认是 BG GC
if (has_not_enough_free_secs(sbi))
gc_type = FG_GC;
// victim selection 过程,完成结果传入 segno
if (!__get_victim(sbi, &segno, gc_type, NO_CHECK_TYPE))
goto stop;
// 论文提到,GC 执行是以 section 为单位的
// 以拿到的 segment 为起始遍历 section 长度
for (i = 0; i < sbi->segs_per_sec; i++) {
/*
* do_garbage_collect will give us three gc_status:
* GC_ERROR, GC_DONE, and GC_BLOCKED.
* If GC is finished uncleanly, we have to return
* the victim to dirty segment list.
*/
// 核心函数
gc_status = do_garbage_collect(sbi, segno + i, &ilist, gc_type);
if (gc_status != GC_DONE)
break;
}
if (has_not_enough_free_secs(sbi)) {
write_checkpoint(sbi, (gc_status == GC_BLOCKED), false);
if (has_not_enough_free_secs(sbi))
goto gc_more;
}
stop:
mutex_unlock(&sbi->gc_mutex);
put_gc_inode(&ilist);
return gc_status;
}
在 GC 真正执行前,需要挑选 victim
Victim selection
static int __get_victim(struct f2fs_sb_info *sbi, unsigned int *victim,
int gc_type, int type)
{
struct sit_info *sit_i = SIT_I(sbi);
int ret;
mutex_lock(&sit_i->sentry_lock);
ret = DIRTY_I(sbi)->v_ops->get_victim(sbi, victim, gc_type, type, LFS);
mutex_unlock(&sit_i->sentry_lock);
return ret;
}
/* victim selection function for cleaning and SSR */
struct victim_selection {
int (*get_victim)(struct f2fs_sb_info *, unsigned int *,
int, int, char);
};
static const struct victim_selection default_v_ops = {
.get_victim = get_victim_by_default,
};
/*
* This function is called from two pathes.
* One is garbage collection and the other is SSR segment selection.
* When it is called during GC, it just gets a victim segment
* and it does not remove it from dirty seglist.
* When it is called from SSR segment selection, it finds a segment
* which has minimum valid blocks and removes it from dirty seglist.
*/
static int get_victim_by_default(struct f2fs_sb_info *sbi,
unsigned int *result, int gc_type, int type, char alloc_mode)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
struct victim_sel_policy p;
unsigned int segno;
int nsearched = 0;
// 如果空间不足,这里固定为 LFS
p.alloc_mode = alloc_mode;
// 如果空间不足,这里确定:
// - gc_mode 为 greedy
// - ofs_unit 为 1
select_policy(sbi, gc_type, type, &p);
p.min_segno = NULL_SEGNO;
p.min_cost = get_max_cost(sbi, &p);
mutex_lock(&dirty_i->seglist_lock);
if (p.alloc_mode == LFS && gc_type == FG_GC) {
// 先尝试获取 BG_GC 获得的 victim
// min_segno 应该是 min_cost 对应的 segment
// 毕竟 BG 的算法是 min_cost 的
p.min_segno = check_bg_victims(sbi);
if (p.min_segno != NULL_SEGNO)
// 如果有就立刻结束
goto got_it;
}
// 否则再按照算法查找
while (1) {
unsigned long cost;
// p.offset 指的是 last scanned bitmap offset,因此从这里开始
// 从 dirty segmap 选择一个 dirty segment
segno = find_next_bit(p.dirty_segmap,
TOTAL_SEGS(sbi), p.offset);
// 没找到 dirty segment
// 循环会跳出
if (segno >= TOTAL_SEGS(sbi)) {
// last_victim:一个大小为 2 的数组,按照 gc_mode 区分
// 此时先清空?不太明白,感觉是指完整扫描过一遍了
if (sbi->last_victim[p.gc_mode]) {
sbi->last_victim[p.gc_mode] = 0;
p.offset = 0;
continue;
}
break;
}
// 下一个 find_next_bit 的开始地址
p.offset = ((segno / p.ofs_unit) * p.ofs_unit) + p.ofs_unit;
// NOTE: victim_segmap 默认为空,见 init_victim_segmap()
// 但是挑选的 dirty segment 这里已经被 victim segmap 标记
// 更新时机见 got_it 部分
if (test_bit(segno, dirty_i->victim_segmap[FG_GC]))
continue;
if (gc_type == BG_GC &&
test_bit(segno, dirty_i->victim_segmap[BG_GC]))
continue;
// 不处理 curseg 指向的起始 section
if (IS_CURSEC(sbi, GET_SECNO(sbi, segno)))
continue;
// 见下方具体流程
// 在当前的上下文中,就是获取 valid block 数目作为成本
cost = get_gc_cost(sbi, segno, &p);
// 如果找到真·min_cost,那就更新对应的 min_segno
if (p.min_cost > cost) {
p.min_segno = segno;
p.min_cost = cost;
}
// 如果成本太大,不能选
// 需要下一次循环用新的 p.offset 再来一遍
if (cost == get_max_cost(sbi, &p))
continue;
// 迭代是有限次数的,MAX_VICTIM_SEARCH = 20
if (nsearched++ >= MAX_VICTIM_SEARCH) {
// 最后一次找到的 segno,不管是否 min 都记下了
// 这有什么用呢?我认为是加速 GC,因为在 select_policy 中,
// 可以看到 GC 扫描开始的 p.offset 就是使用 last_victim
sbi->last_victim[p.gc_mode] = segno;
break;
}
}
got_it:
if (p.min_segno != NULL_SEGNO) {
// 从这里可以看出最终目标就是求出 p.min_segno
// 这里一直有除后再乘上的操作是因为作者假定 section 和 segment 不是统一单位
*result = (p.min_segno / p.ofs_unit) * p.ofs_unit;
if (p.alloc_mode == LFS) {
int i;
// 标记对应的 victim segmap
for (i = 0; i < p.ofs_unit; i++)
set_bit(*result + i,
dirty_i->victim_segmap[gc_type]);
}
}
mutex_unlock(&dirty_i->seglist_lock);
return (p.min_segno == NULL_SEGNO) ? 0 : 1;
}
static void select_policy(struct f2fs_sb_info *sbi, int gc_type,
int type, struct victim_sel_policy *p)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
// LFS 走这里
if (p->alloc_mode) {
// 在当前的流程中,p 已经确定是 LFS,因此是 GREEDY
p->gc_mode = GC_GREEDY;
p->dirty_segmap = dirty_i->dirty_segmap[type];
p->ofs_unit = 1;
} else {
p->gc_mode = select_gc_type(gc_type);
// 这里有点特殊,用的是 dirty_segmap[DIRTY]
p->dirty_segmap = dirty_i->dirty_segmap[DIRTY];
p->ofs_unit = sbi->segs_per_sec;
}
p->offset = sbi->last_victim[p->gc_mode];
}
static unsigned int get_max_cost(struct f2fs_sb_info *sbi,
struct victim_sel_policy *p)
{
if (p->gc_mode == GC_GREEDY)
return (1 << sbi->log_blocks_per_seg) * p->ofs_unit;
// CB 是 Cost-Benefit 的意思
else if (p->gc_mode == GC_CB)
return UINT_MAX;
else /* No other gc_mode */
return 0;
}
static unsigned int check_bg_victims(struct f2fs_sb_info *sbi)
{
struct dirty_seglist_info *dirty_i = DIRTY_I(sbi);
unsigned int segno;
/*
* If the gc_type is FG_GC, we can select victim segments
* selected by background GC before.
* Those segments guarantee they have small valid blocks.
*/
segno = find_next_bit(dirty_i->victim_segmap[BG_GC],
TOTAL_SEGS(sbi), 0);
if (segno < TOTAL_SEGS(sbi)) {
clear_bit(segno, dirty_i->victim_segmap[BG_GC]);
return segno;
}
return NULL_SEGNO;
}
static unsigned int get_gc_cost(struct f2fs_sb_info *sbi, unsigned int segno,
struct victim_sel_policy *p)
{
if (p->alloc_mode == SSR)
return get_seg_entry(sbi, segno)->ckpt_valid_blocks;
/* alloc_mode == LFS */
if (p->gc_mode == GC_GREEDY)
// 从 select_policy() 分析得出目前流程会走到这里
// 查找 valid block 数目最少的 segno,避免迁移成本
// NOTE: 这里不用取最小,这个工作在 get_victim_by_default() 完成
// 实现上就是得到 sentry 的 valid_blocks 字段(非常直接)
return get_valid_blocks(sbi, segno, sbi->segs_per_sec);
else
// 最优成本算法,考虑老化
return get_cb_cost(sbi, segno);
}
static unsigned int get_cb_cost(struct f2fs_sb_info *sbi, unsigned int segno)
{
struct sit_info *sit_i = SIT_I(sbi);
unsigned int secno = GET_SECNO(sbi, segno);
unsigned int start = secno * sbi->segs_per_sec;
unsigned long long mtime = 0;
unsigned int vblocks;
unsigned char age = 0;
unsigned char u;
unsigned int i;
// 累计 mtime
// 这里 mtime 是每个 segment 加起来的
for (i = 0; i < sbi->segs_per_sec; i++)
mtime += get_seg_entry(sbi, start + i)->mtime;
vblocks = get_valid_blocks(sbi, segno, sbi->segs_per_sec);
// 换算 mtime 为 segment 平均水平
mtime = div_u64(mtime, sbi->segs_per_sec);
vblocks = div_u64(vblocks, sbi->segs_per_sec);
// 参数 1:u,块利用率(util%)的意思
// u = vblock * 100 / 512
// = vblock / 512 * 100 (vblock <= 512)
// <= 100
u = (vblocks * 100) >> sbi->log_blocks_per_seg;
/* Handle if the system time is changed by user */
// min 和 max 指的是这个 segment 中的最大最小修改时间
// 话说为啥平均水平会超出最值呢?好神奇哦
if (mtime < sit_i->min_mtime)
sit_i->min_mtime = mtime;
if (mtime > sit_i->max_mtime)
sit_i->max_mtime = mtime;
// 避免除以 0
if (sit_i->max_mtime != sit_i->min_mtime)
// 参数 2:age,一个 segment 的年纪
// age = 100 - 100*(avg - min)/(max - min)
// 这个估值方式有点疑问,为什么是单调时钟而不考虑 sbi 设墙上时钟?
// 总之是这个算法吧,很久没任何改动就大概是年纪大(avg≈min,age≈100)
age = 100 - div64_u64(100 * (mtime - sit_i->min_mtime),
sit_i->max_mtime - sit_i->min_mtime);
// 利用率部分为 (100-u)/(100+u),u 范围 [0,100] 的结果是单调递减的
// 考虑负数的优先级反转后(且要尽可能小的数值),总结:
// - 年纪越大,越容易毕业
// - 利用率越低,越容易毕业
return UINT_MAX - ((100 * (100 - u) * age) / (100 + u));
}
虽然过程有点繁琐,但是这里可看出两种挑选算法的细节:
- 如果是贪心算法,那就 \(O(1)\) 找出块利用率最少的 segment
- 如果是成本最优算法,需要 \(O(segments\_per\_section)\) 计算,同时考虑段的年龄和块利用率
这里有个疑问,如果使用 1:1:1 的单位,那成本最优算法也就降为\(O(1)\)的复杂度,在这个上下文中是否所有挑选策略都按这个算法来执行会更好?我看未必,一是成本最优算法的内部复杂度常数仍比贪心算法高不少;二是两种算法都是估值算法,成本最优只是看似更精准的估值方式
GC procedure
上面 victim selection 拿到 segno 后就可以执行核心的 gc 流程 do_garbage_collect(),处理 \([segno, segno + segments\_per\_section)\) 编号范围的 segment(每次调用处理单个 segment)
static int do_garbage_collect(struct f2fs_sb_info *sbi, unsigned int segno,
struct list_head *ilist, int gc_type)
{
struct page *sum_page;
struct f2fs_summary_block *sum;
int ret = GC_DONE;
/* read segment summary of victim */
// 获取关联的 summary
sum_page = get_sum_page(sbi, segno);
if (IS_ERR(sum_page))
return GC_ERROR;
/*
* CP needs to lock sum_page. In this time, we don't need
* to lock this page, because this summary page is not gone anywhere.
* Also, this page is not gonna be updated before GC is done.
*/
unlock_page(sum_page);
sum = page_address(sum_page);
// 区分类型的 GC 操作
switch (GET_SUM_TYPE((&sum->footer))) {
case SUM_TYPE_NODE:
ret = gc_node_segment(sbi, sum->entries, segno, gc_type);
break;
case SUM_TYPE_DATA:
ret = gc_data_segment(sbi, sum->entries, ilist, segno, gc_type);
break;
}
stat_inc_seg_count(sbi, GET_SUM_TYPE((&sum->footer)));
stat_inc_call_count(sbi->stat_info);
f2fs_put_page(sum_page, 0);
return ret;
}
/*
* This function tries to get parent node of victim data block, and identifies
* data block validity. If the block is valid, copy that with cold status and
* modify parent node.
* If the parent node is not valid or the data block address is different,
* the victim data block is ignored.
*/
static int gc_data_segment(struct f2fs_sb_info *sbi, struct f2fs_summary *sum,
struct list_head *ilist, unsigned int segno, int gc_type)
{
struct super_block *sb = sbi->sb;
struct f2fs_summary *entry;
block_t start_addr;
int err, off;
int phase = 0;
// segno 起始 block 转为 block_t 单位
start_addr = START_BLOCK(sbi, segno);
next_step:
entry = sum;
// 遍历 segment,off 是 block 个数偏移量
// 完整 for 一遍后才会 phase 递增,再执行 for
for (off = 0; off < sbi->blocks_per_seg; off++, entry++) {
struct page *data_page;
struct inode *inode;
struct node_info dni; /* dnode info for the data */
unsigned int ofs_in_node, nofs;
block_t start_bidx;
/*
* It makes sure that free segments are able to write
* all the dirty node pages before CP after this CP.
* So let's check the space of dirty node pages.
*/
if (should_do_checkpoint(sbi)) {
mutex_lock(&sbi->cp_mutex);
block_operations(sbi);
err = GC_BLOCKED;
goto stop;
}
// 根据 segno 获取 sentry
// 再根据 off 进行 sentry->cur_valid_map 的 testbit
// 正常返回 GC_OK (bit:1)
// NOTE:
// bitmap 更新时机在前面 SIT update 章节中的 update_sit_entry()
// 就是说 write page 时一般都置旧页/块为 1
err = check_valid_map(sbi, segno, off);
if (err == GC_NEXT)
continue;
if (phase == 0) {
// 阶段 0,预读 node page
//(nid 通过 block 寻址获得,赋值 callee 见 set_summary())
// NOTE: 这些预读是为下一个 phase 确保 page 已在内存中
ra_node_page(sbi, le32_to_cpu(entry->nid));
continue;
}
/* Get an inode by ino with checking validity */
// 获取 dni,可进一步获取 inode
err = check_dnode(sbi, entry, &dni, start_addr + off, &nofs);
if (err == GC_NEXT)
continue;
if (phase == 1) {
// 阶段 1,预读 inode page
ra_node_page(sbi, dni.ino);
continue;
}
// start_bidx 含义:start block index indicating the given node offset
start_bidx = start_bidx_of_node(nofs);
// TODO: fill_node_footer()
ofs_in_node = le16_to_cpu(entry->ofs_in_node);
if (phase == 2) {
// 获得 inode 实例
inode = f2fs_iget_nowait(sb, dni.ino);
if (IS_ERR(inode))
continue;
// 以 start_bidx + ofs_in_node 为 page index 定位到 data page
data_page = find_data_page(inode,
start_bidx + ofs_in_node);
if (IS_ERR(data_page))
goto next_iput;
f2fs_put_page(data_page, 0);
// inode 加入到 gc list(ilist,是一个栈上的链表)
add_gc_inode(inode, ilist);
// 这里 phase == 3
} else {
// 遍历找到 ino
inode = find_gc_inode(dni.ino, ilist);
if (inode) {
data_page = get_lock_data_page(inode,
start_bidx + ofs_in_node);
if (IS_ERR(data_page))
continue;
move_data_page(inode, data_page, gc_type);
stat_inc_data_blk_count(sbi, 1);
}
}
continue;
next_iput:
iput(inode);
}
if (++phase < 4)
goto next_step;
err = GC_DONE;
stop:
if (gc_type == FG_GC)
f2fs_submit_bio(sbi, DATA, true);
return err;
}
static void add_gc_inode(struct inode *inode, struct list_head *ilist)
{
struct list_head *this;
// inode_entry 是个<list_head*, inode*>二元组
struct inode_entry *new_ie, *ie;
// 避免重复加入
list_for_each(this, ilist) {
ie = list_entry(this, struct inode_entry, list);
if (ie->inode == inode) {
iput(inode);
return;
}
}
repeat:
new_ie = kmem_cache_alloc(winode_slab, GFP_NOFS);
if (!new_ie) {
cond_resched();
goto repeat;
}
new_ie->inode = inode;
list_add_tail(&new_ie->list, ilist);
}
static struct inode *find_gc_inode(nid_t ino, struct list_head *ilist)
{
struct list_head *this;
struct inode_entry *ie;
list_for_each(this, ilist) {
ie = list_entry(this, struct inode_entry, list);
if (ie->inode->i_ino == ino)
return ie->inode;
}
return NULL;
}
static void move_data_page(struct inode *inode, struct page *page, int gc_type)
{
if (page->mapping != inode->i_mapping)
goto out;
if (inode != page->mapping->host)
goto out;
if (PageWriteback(page))
goto out;
// BG 的时候没有实际移动,而是设为 COLD
if (gc_type == BG_GC) {
set_page_dirty(page);
set_cold_data(page);
} else {
struct f2fs_sb_info *sbi = F2FS_SB(inode->i_sb);
mutex_lock_op(sbi, DATA_WRITE);
if (clear_page_dirty_for_io(page) &&
S_ISDIR(inode->i_mode)) {
dec_page_count(sbi, F2FS_DIRTY_DENTS);
inode_dec_dirty_dents(inode);
}
set_cold_data(page);
// 写到新的位置,见 Write operation 章节
do_write_data_page(page);
mutex_unlock_op(sbi, DATA_WRITE);
clear_cold_data(page);
}
out:
f2fs_put_page(page, 1);
}
当决定 victim section 后,核心流程会按照地址关系找出具体的 block,并执行写操作,因为写操作通常是 LFS-style(设置了 COLD,因此必然是 LFS),也就会迁移到新的地址。被利用的(少数)block 依次迁出,后续整个 section 就回归到可利用的状态
Recovery
如论文所述,F2FS 使用 check point 来实现 roll-back recovery。check point 可以发生在 umount() 和 sync() 阶段,先看 umount() 的过程
static void f2fs_put_super(struct super_block *sb)
{
struct f2fs_sb_info *sbi = F2FS_SB(sb);
f2fs_destroy_stats(sbi);
stop_gc_thread(sbi);
// 触发 check point
write_checkpoint(sbi, false, true);
iput(sbi->node_inode);
iput(sbi->meta_inode);
/* destroy f2fs internal modules */
destroy_node_manager(sbi);
destroy_segment_manager(sbi);
kfree(sbi->ckpt);
sb->s_fs_info = NULL;
brelse(sbi->raw_super_buf);
kfree(sbi);
}
以 umount() 为例,上层调用 f2fs_put_super(),内部会执行 write_checkpoint() 触发 check point
主流程
write_checkpoint() 的大纲其实在论文中已经给出
F2FS triggers a checkpoint procedure as follows:
(1) All dirty node and dentry blocks in the page cache are flushed;
(2) It suspends ordinary writing activities including system calls such as create, unlink and mkdir;
(3) The file system metadata, NAT, SIT and SSA, are written to their dedicated areas on the disk; and
(4) Finally, F2FS writes a checkpoint pack.
/*
* We guarantee that this checkpoint procedure should not fail.
*/
void write_checkpoint(struct f2fs_sb_info *sbi, bool blocked, bool is_umount)
{
struct f2fs_checkpoint *ckpt = F2FS_CKPT(sbi);
unsigned long long ckpt_ver;
if (!blocked) {
mutex_lock(&sbi->cp_mutex);
// 内部会 mutex lock 若干的锁
block_operations(sbi);
}
// DATA 和 NODE 均是 main area block
// META 则是 main area 之外的区域
// NOTE: 然而 META 多是内存数据结构,刷下去也未必是最新的
f2fs_submit_bio(sbi, DATA, true);
f2fs_submit_bio(sbi, NODE, true);
f2fs_submit_bio(sbi, META, true);
/*
* update checkpoint pack index
* Increase the version number so that
* SIT entries and seg summaries are written at correct place
*/
// 获取 check point 版本号并且递增
ckpt_ver = le64_to_cpu(ckpt->checkpoint_ver);
ckpt->checkpoint_ver = cpu_to_le64(++ckpt_ver);
/* write cached NAT/SIT entries to NAT/SIT area */
flush_nat_entries(sbi);
flush_sit_entries(sbi);
reset_victim_segmap(sbi);
/* unlock all the fs_lock[] in do_checkpoint() */
do_checkpoint(sbi, is_umount);
unblock_operations(sbi);
mutex_unlock(&sbi->cp_mutex);
}
稍微有的细节差异是flush操作在block操作之后(block操作是通过mutex lock完成的)
NAT flush
这里看下第三步里面的NAT刷新是怎么做的
/*
* This function is called during the checkpointing process.
*/
void flush_nat_entries(struct f2fs_sb_info *sbi)
{
struct f2fs_nm_info *nm_i = NM_I(sbi);
struct curseg_info *curseg = CURSEG_I(sbi, CURSEG_HOT_DATA);
struct f2fs_summary_block *sum = curseg->sum_blk;
struct list_head *cur, *n;
struct page *page = NULL;
struct f2fs_nat_block *nat_blk = NULL;
nid_t start_nid = 0, end_nid = 0;
bool flushed;
// true 表示 journal 数目(curseg->sum_blk->n_nats)已满
// 即数目超过 (SUM_JOURNAL_SIZE - 2)/sizeof(struct nat_journal_entry)
// SUM_JOURNAL_SIZE 表示一个 4k block 减去 summary_footer(5 字节)和 entry(7 字节*512)
//
// 如果没满,直接返回 false,否则刷入到 dirty_nat_entries 再返回 true
flushed = flush_nats_in_journal(sbi);
if (!flushed)
mutex_lock(&curseg->curseg_mutex);
/* 1) flush dirty nat caches */
// dirty_nat_entries一般是在set_node_addr()时更新
// set_node_addr()的caller有f2fs_write_node_page(),new_node_page()
// 除此以外上面的flush_nats_in_journal也会记录到dirty_nat_entries
// 这个具体流程有空再补吧
//
// 遍历dirty_nat_entries并刷出到raw_ne
list_for_each_safe(cur, n, &nm_i->dirty_nat_entries) {
struct nat_entry *ne;
nid_t nid;
struct f2fs_nat_entry raw_ne;
int offset = -1;
block_t new_blkaddr;
ne = list_entry(cur, struct nat_entry, list);
nid = nat_get_nid(ne);
if (nat_get_blkaddr(ne) == NEW_ADDR)
continue;
if (flushed)
goto to_nat_page;
/* if there is room for nat enries in curseg->sumpage */
// 在这个上下文中,该函数主要遍历测试i∈[0, nats_in_cursum(sum))
// if nid_in_journal(sum, i)) == val,找到就返回i
// #define nid_in_journal(sum, i) (sum->nat_j.entries[i].nid)
offset = lookup_journal_in_cursum(sum, NAT_JOURNAL, nid, 1);
if (offset >= 0) {
// 得到sum->nat_j.entries[offset].ne
// 这里是!flushed,raw_ne从journal得到
// 另外的来源(flused情况)见to_nat_page
raw_ne = nat_in_journal(sum, offset);
goto flush_now;
}
to_nat_page:
if (!page || (start_nid > nid || nid > end_nid)) {
// 因为这是在一个循环内部,多个 nid 可能对着一个 page
// 直到超出范围才 put 掉
if (page) {
f2fs_put_page(page, 1);
page = NULL;
}
start_nid = START_NID(nid);
end_nid = start_nid + NAT_ENTRY_PER_BLOCK - 1;
/*
* get nat block with dirty flag, increased reference
* count, mapped and lock
*/
page = get_next_nat_page(sbi, start_nid);
// 实际的NAT block
nat_blk = page_address(page);
}
BUG_ON(!nat_blk);
// 如果是flushed,那么raw_ne是从nat_blk通过readpage得到的
raw_ne = nat_blk->entries[nid - start_nid];
flush_now:
new_blkaddr = nat_get_blkaddr(ne);
// 刷入ne三元组
raw_ne.ino = cpu_to_le32(nat_get_ino(ne));
raw_ne.block_addr = cpu_to_le32(new_blkaddr);
raw_ne.version = nat_get_version(ne);
// 脏的要么写到NAT block,要么写到journal
if (offset < 0) {
nat_blk->entries[nid - start_nid] = raw_ne;
} else {
nat_in_journal(sum, offset) = raw_ne;
nid_in_journal(sum, offset) = cpu_to_le32(nid);
}
if (nat_get_blkaddr(ne) == NULL_ADDR) {
write_lock(&nm_i->nat_tree_lock);
__del_from_nat_cache(nm_i, ne);
write_unlock(&nm_i->nat_tree_lock);
/* We can reuse this freed nid at this point */
add_free_nid(NM_I(sbi), nid);
} else {
write_lock(&nm_i->nat_tree_lock);
__clear_nat_cache_dirty(nm_i, ne);
ne->checkpointed = true;
write_unlock(&nm_i->nat_tree_lock);
}
}
if (!flushed)
mutex_unlock(&curseg->curseg_mutex);
f2fs_put_page(page, 1);
/* 2) shrink nat caches if necessary */
try_to_free_nats(sbi, nm_i->nat_cnt - NM_WOUT_THRESHOLD);
}
NAT flush操作是要把内存上已脏的NAT entry刷入到外存,但是NAT entry可能是真的在NAT area中,也可能只是一个NAT journal,因此要刷到哪里就看journal空间是否足够,尽量使用journal避免频繁in-place的写入操作
SIT flush
SIT flush与NAT flush类似,即区分SIT area和SIT journal
CP procedure
脏数据刷写完成后,就进入到实际的check point执行
static void do_checkpoint(struct f2fs_sb_info *sbi, bool is_umount)
{
struct f2fs_checkpoint *ckpt = F2FS_CKPT(sbi);
nid_t last_nid = 0;
block_t start_blk;
struct page *cp_page;
unsigned int data_sum_blocks, orphan_blocks;
unsigned int crc32 = 0;
void *kaddr;
int i;
/* Flush all the NAT/SIT pages */
while (get_pages(sbi, F2FS_DIRTY_META))
sync_meta_pages(sbi, META, LONG_MAX);
// 求出last_nid,后面写到check point的next_free_nid
next_free_nid(sbi, &last_nid);
/*
* modify checkpoint
* version number is already updated
*/
// checkpoint_ver在NAT/SIT flush前已更新
ckpt->elapsed_time = cpu_to_le64(get_mtime(sbi));
ckpt->valid_block_count = cpu_to_le64(valid_user_blocks(sbi));
ckpt->free_segment_count = cpu_to_le32(free_segments(sbi));
for (i = 0; i < 3; i++) {
ckpt->cur_node_segno[i] =
cpu_to_le32(curseg_segno(sbi, i + CURSEG_HOT_NODE));
ckpt->cur_node_blkoff[i] =
cpu_to_le16(curseg_blkoff(sbi, i + CURSEG_HOT_NODE));
ckpt->alloc_type[i + CURSEG_HOT_NODE] =
curseg_alloc_type(sbi, i + CURSEG_HOT_NODE);
}
for (i = 0; i < 3; i++) {
ckpt->cur_data_segno[i] =
cpu_to_le32(curseg_segno(sbi, i + CURSEG_HOT_DATA));
ckpt->cur_data_blkoff[i] =
cpu_to_le16(curseg_blkoff(sbi, i + CURSEG_HOT_DATA));
ckpt->alloc_type[i + CURSEG_HOT_DATA] =
curseg_alloc_type(sbi, i + CURSEG_HOT_DATA);
}
ckpt->valid_node_count = cpu_to_le32(valid_node_count(sbi));
ckpt->valid_inode_count = cpu_to_le32(valid_inode_count(sbi));
ckpt->next_free_nid = cpu_to_le32(last_nid);
/* 2 cp + n data seg summary + orphan inode blocks */
// 这是summary在CP area占用的page/block个数
data_sum_blocks = npages_for_summary_flush(sbi);
// compact mode影响write_data_summaries()写入和restore_curseg_summaries()恢复
// 1-2个page内可以搞定,就设为compact
if (data_sum_blocks < 3)
set_ckpt_flags(ckpt, CP_COMPACT_SUM_FLAG);
else
clear_ckpt_flags(ckpt, CP_COMPACT_SUM_FLAG);
// orphan inode用于处理unlink/truncate时的一致性
// 基本思路:
// 1. 当需要删除/截断一个inode时,先把inode记录到orphan外存
// 2. 操作成功后再从orphan移除
// 3. 加载check point时会重做一遍仍在orphan里的操作
// 这样在1-2操作完成前宕机仍保持一致性
orphan_blocks = (sbi->n_orphans + F2FS_ORPHANS_PER_BLOCK - 1)
/ F2FS_ORPHANS_PER_BLOCK;
ckpt->cp_pack_start_sum = cpu_to_le32(1 + orphan_blocks);
if (is_umount) {
set_ckpt_flags(ckpt, CP_UMOUNT_FLAG);
ckpt->cp_pack_total_block_count = cpu_to_le32(2 +
data_sum_blocks + orphan_blocks + NR_CURSEG_NODE_TYPE);
} else {
clear_ckpt_flags(ckpt, CP_UMOUNT_FLAG);
ckpt->cp_pack_total_block_count = cpu_to_le32(2 +
data_sum_blocks + orphan_blocks);
}
if (sbi->n_orphans)
set_ckpt_flags(ckpt, CP_ORPHAN_PRESENT_FLAG);
else
clear_ckpt_flags(ckpt, CP_ORPHAN_PRESENT_FLAG);
/* update SIT/NAT bitmap */
// __bitmap_ptr指向ckpt中对应的bitmap
// 这两个函数会把对应的sit_i->sit_bitmap和nm_i->nat_bitmap拷贝到ckpt
get_sit_bitmap(sbi, __bitmap_ptr(sbi, SIT_BITMAP));
get_nat_bitmap(sbi, __bitmap_ptr(sbi, NAT_BITMAP));
crc32 = f2fs_crc32(ckpt, le32_to_cpu(ckpt->checksum_offset));
*(__le32 *)((unsigned char *)ckpt +
le32_to_cpu(ckpt->checksum_offset))
= cpu_to_le32(crc32);
// 这里的开始地址是有讲究的
// 前面讲过cp pack之间是交替存放的,间隔segment
start_blk = __start_cp_addr(sbi);
/* write out checkpoint buffer at block 0 */
cp_page = grab_meta_page(sbi, start_blk++);
kaddr = page_address(cp_page);
// 使用一个block存放ckpt
memcpy(kaddr, ckpt, (1 << sbi->log_blocksize));
set_page_dirty(cp_page);
f2fs_put_page(cp_page, 1);
// 使用orphan_blocks数目的block存放orphan
if (sbi->n_orphans) {
write_orphan_inodes(sbi, start_blk);
start_blk += orphan_blocks;
}
// compact mode和normal mode的写入方式不一样
// 使用data_sum_blocks数目的block存放data summary
write_data_summaries(sbi, start_blk);
start_blk += data_sum_blocks;
if (is_umount) {
// umount的情况还写入node summary
write_node_summaries(sbi, start_blk);
// 固定占坑3个block
start_blk += NR_CURSEG_NODE_TYPE;
}
/* writeout checkpoint block */
// 再使用一个block存放ckpt,用于校验
cp_page = grab_meta_page(sbi, start_blk);
kaddr = page_address(cp_page);
memcpy(kaddr, ckpt, (1 << sbi->log_blocksize));
set_page_dirty(cp_page);
f2fs_put_page(cp_page, 1);
// 剩下的就是善后处理
/* wait for previous submitted node/meta pages writeback */
while (get_pages(sbi, F2FS_WRITEBACK))
congestion_wait(BLK_RW_ASYNC, HZ / 50);
filemap_fdatawait_range(sbi->node_inode->i_mapping, 0, LONG_MAX);
filemap_fdatawait_range(sbi->meta_inode->i_mapping, 0, LONG_MAX);
/* update user_block_counts */
sbi->last_valid_block_count = sbi->total_valid_block_count;
sbi->alloc_valid_block_count = 0;
/* Here, we only have one bio having CP pack */
if (is_set_ckpt_flags(ckpt, CP_ERROR_FLAG))
// 出事了就进入只读模式
sbi->sb->s_flags |= MS_RDONLY;
else
sync_meta_pages(sbi, META_FLUSH, LONG_MAX);
clear_prefree_segments(sbi);
F2FS_RESET_SB_DIRT(sbi);
}
/*
* Calculate the number of current summary pages for writing
*/
int npages_for_summary_flush(struct f2fs_sb_info *sbi)
{
int total_size_bytes = 0;
// summary entry 数目
int valid_sum_count = 0;
int i, sum_space;
// 计算curseg的sum block
for (i = CURSEG_HOT_DATA; i <= CURSEG_COLD_DATA; i++) {
if (sbi->ckpt->alloc_type[i] == SSR)
valid_sum_count += sbi->blocks_per_seg;
else
// 直接加上curseg->next_blkoff
// 一个seg内next_blkoff前的sum entry均有效
valid_sum_count += curseg_blkoff(sbi, i);
}
// 为什么需要+1?
total_size_bytes = valid_sum_count * (SUMMARY_SIZE + 1)
+ sizeof(struct nat_journal) + 2
+ sizeof(struct sit_journal) + 2;
sum_space = PAGE_CACHE_SIZE - SUM_FOOTER_SIZE;
// 1个page内可以搞定
if (total_size_bytes < sum_space)
return 1;
// 2个page内可以搞定
else if (total_size_bytes < 2 * sum_space)
return 2;
// 看后面分析,normal mode在3个page内必能搞定
// 就是三种data type curseg,每种各写一个page
// (sum_blk直接拷过去)
return 3;
}
static inline block_t __start_cp_addr(struct f2fs_sb_info *sbi)
{
block_t start_addr = le32_to_cpu(F2FS_RAW_SUPER(sbi)->cp_blkaddr);
// 前面分析过 cp pack,交替使用,pack 之间间隔 segment 单位
if (sbi->cur_cp_pack == 2)
start_addr += sbi->blocks_per_seg;
return start_addr;
}
void write_data_summaries(struct f2fs_sb_info *sbi, block_t start_blk)
{
// 区分 compact mode 还是 normal mode
if (is_set_ckpt_flags(F2FS_CKPT(sbi), CP_COMPACT_SUM_FLAG))
write_compacted_summaries(sbi, start_blk);
else
write_normal_summaries(sbi, start_blk, CURSEG_HOT_DATA);
}
static void write_compacted_summaries(struct f2fs_sb_info *sbi, block_t blkaddr)
{
struct page *page;
unsigned char *kaddr;
struct f2fs_summary *summary;
struct curseg_info *seg_i;
int written_size = 0;
int i, j;
// 这里一开始传入 blkaddr 位于 CP area
// 可能是 ckpt 后面,也可能是 orphan 后面
page = grab_meta_page(sbi, blkaddr++);
kaddr = (unsigned char *)page_address(page);
/* Step 1: write nat cache */
// 写入HOT_DATA存放的NAT jorunal
seg_i = CURSEG_I(sbi, CURSEG_HOT_DATA);
memcpy(kaddr, &seg_i->sum_blk->n_nats, SUM_JOURNAL_SIZE);
written_size += SUM_JOURNAL_SIZE;
/* Step 2: write sit cache */
// 写入COLD_DATA存放的SIT journal
seg_i = CURSEG_I(sbi, CURSEG_COLD_DATA);
memcpy(kaddr + written_size, &seg_i->sum_blk->n_sits,
SUM_JOURNAL_SIZE);
written_size += SUM_JOURNAL_SIZE;
set_page_dirty(page);
/* Step 3: write summary entries */
// 写入summary entry
for (i = CURSEG_HOT_DATA; i <= CURSEG_COLD_DATA; i++) {
unsigned short blkoff;
seg_i = CURSEG_I(sbi, i);
if (sbi->ckpt->alloc_type[i] == SSR)
blkoff = sbi->blocks_per_seg;
else
// 定位到最后的valid summary entry前
blkoff = curseg_blkoff(sbi, i);
// 依次遍历即可
for (j = 0; j < blkoff; j++) {
if (!page) {
page = grab_meta_page(sbi, blkaddr++);
kaddr = (unsigned char *)page_address(page);
written_size = 0;
}
summary = (struct f2fs_summary *)(kaddr + written_size);
*summary = seg_i->sum_blk->entries[j];
written_size += SUMMARY_SIZE;
set_page_dirty(page);
// page还没满
if (written_size + SUMMARY_SIZE <= PAGE_CACHE_SIZE -
SUM_FOOTER_SIZE)
continue;
f2fs_put_page(page, 1);
page = NULL;
}
}
if (page)
f2fs_put_page(page, 1);
}
static void write_normal_summaries(struct f2fs_sb_info *sbi,
block_t blkaddr, int type)
{
int i, end;
// type 在这里传入 CURSEG_HOT_DATA
if (IS_DATASEG(type))
end = type + NR_CURSEG_DATA_TYPE;
else
end = type + NR_CURSEG_NODE_TYPE;
// 遍历DATA TYPE curseg
// 总共三种温度,各写一个page,按[HOT, WARM, COLD]顺序排放在blkaddr后面
// 如上面compact写入分析,blkaddr要么定位在ckpt后面,要么在orphan后面
for (i = type; i < end; i++) {
struct curseg_info *sum = CURSEG_I(sbi, i);
mutex_lock(&sum->curseg_mutex);
write_sum_page(sbi, sum->sum_blk, blkaddr + (i - type));
mutex_unlock(&sum->curseg_mutex);
}
}
执行过程处理这些关键路径:
- 构造ckpt结构体
- 计算data summary,决定使用compact mode还是normal mode
- SIT bitmap和NAT bitmap放入ckpt
- 开始摆放CP area,起始地址按cp pack决定
- 写入ckpt到CP area
- 写入orphan到CP area「可选」
- 写入data summary到CP area
- 写入node summary到CP area「可选」
- 写入同一份ckpt到CP area
这里还有一些细节:
- 写入data summmary可以有compact mode或者normal mode
- compact mode可以压缩data summary到1至2个block的大小
umount()时才会写入node summary
如果使能compact mode,那么会按照
[NAT-journal], [SIT-journal], [mixed-summary-entry]
的形式写入data summary;否则直接按3个 curseg->sum_blk 分别写入data summary,即
[HOT-DATA-sum_blk], [WARM-DATA-sum_blk], [COLD_DATA-sum_blk]
数据结构之间的联系见上文 mkfs.f2fs 格式化流程 对 summary block 的解释
现在已经得知 check point 的构造方式,那回滚恢复就不是什么难事,按部就班解析就行了
剩余部分鋭意製作中,先放松一下吧
Last update: 2023/10/19
 Kokona is cute!
Kokona is cute!