导读
本文首先从背景和架构上简单介绍 blk-mq 框架,随后会通过数据结构和具体流程去更加深入了解该机制的内部实现。
背景
什么是 blk-mq
The Multi-Queue Block IO Queueing Mechanism is an API to enable fast storage
devices to achieve a huge number of input/output operations per second (IOPS)
through queueing and submitting IO requests to block devices simultaneously,
benefiting from the parallelism offered by modern storage devices.
TL;DR blk-mq 是内核 block 层的多队列 IO 框架,适用于高 IOPS 要求的多队列存储设备。
为什么需要 blk-mq
 软件瓶颈
软件瓶颈
主要原因是 multi-core 和 multi-queue 的发展,性能瓶颈从硬件本身转移到软件层面上:单队列框架对于锁竞争和远端内存访问成为了性能问题。因此,重构是必须的。


在具体的跑分上,可以看出单队列框架(SQ)在扩展性上是无法满足硬件发展的。
框架概览

为了减少锁争用和尽可能利用局部性原理,blk-mq 把同时负责提交和派发的单一队列拆分为多层级和多队列。
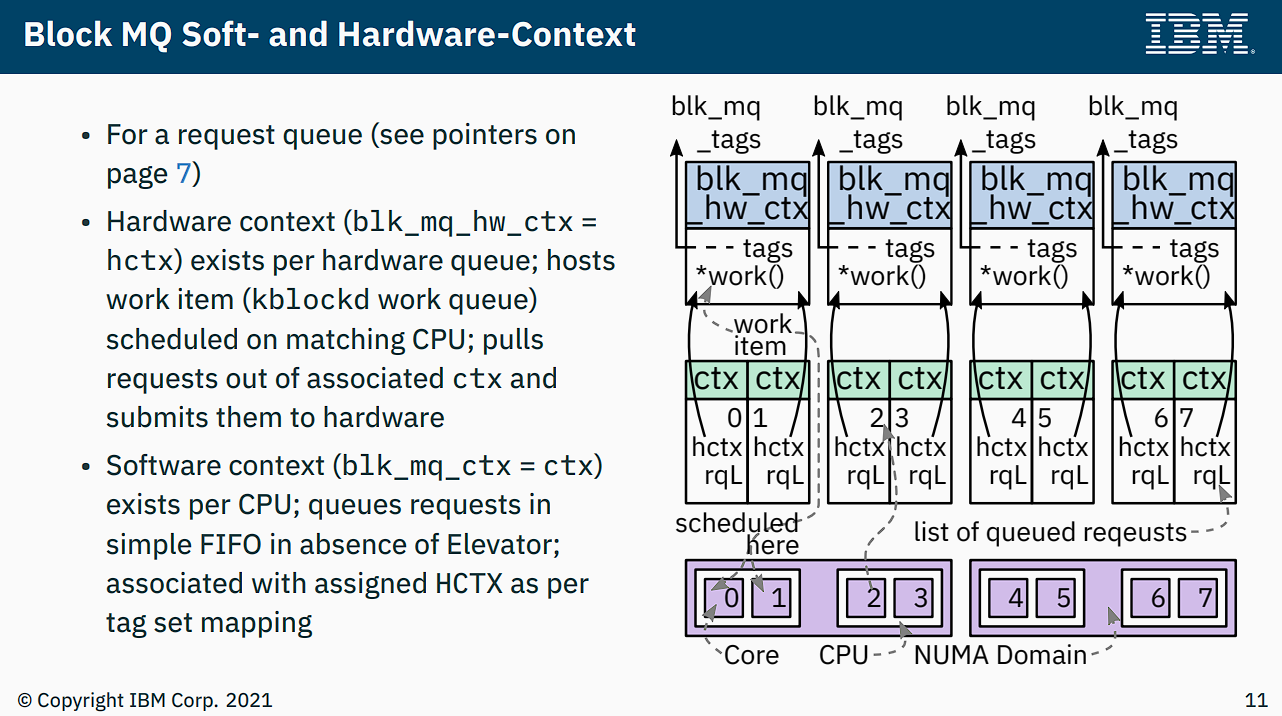
blk-mq 框架中有 2 种形式的队列:
- per-cpu 级别的软件队列 Software Staging Queue。
- 一般称为 software queue、software staging queue、ctx (context)。
- 对应于数据结构
blk_mq_ctx。
- 对应于存储设备硬件队列的 Hardware Dispatch Queue。
- 一般有 hardware queue、hctx (hardware context)、hwq 等奇怪命名。
- 对应于数据结构
blk_mq_hw_ctx。 - 进入该队列的 request 意味着已经经过了调度。
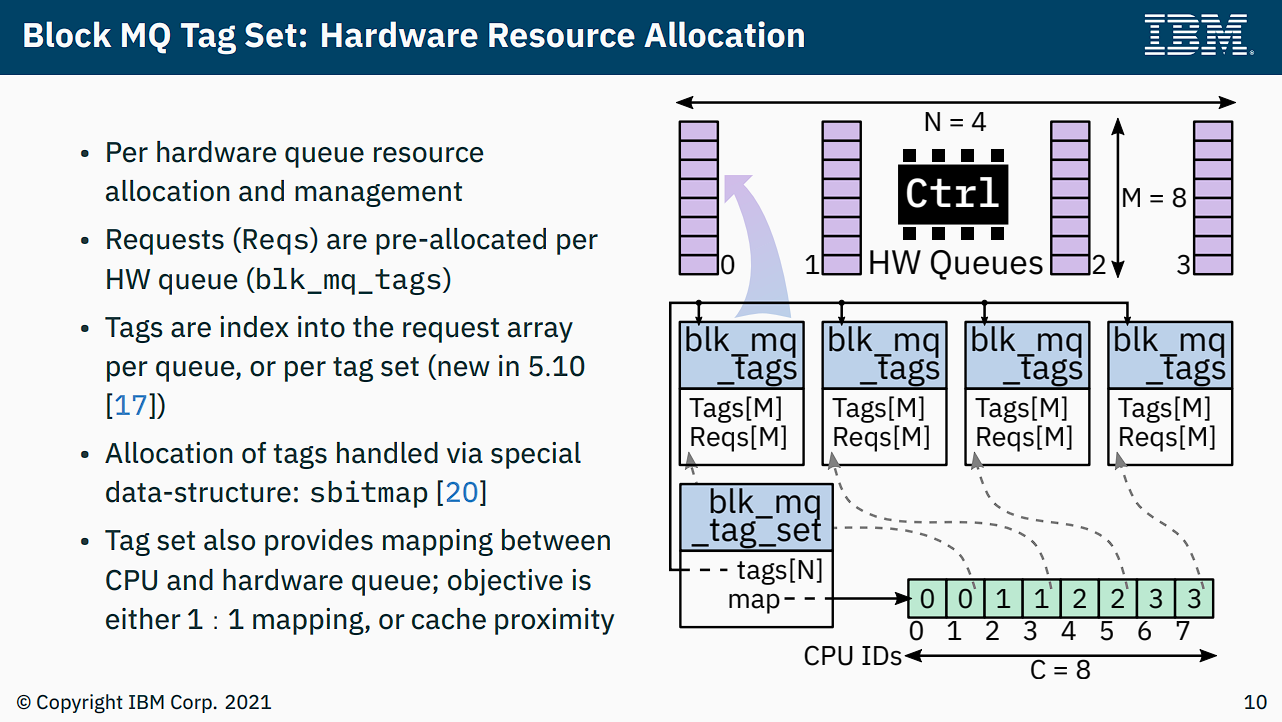
而每个存储设备有一个 controlling structure,为 blk_mq_tag_set,用于维护队列的关系:
| 字段 | 类型 | 用途 | 备注 |
|---|---|---|---|
.mq_maps
| int*,实际作为一个 int[] 数组使用,长度为 CPU 个数
| 实现 CPU 到硬件队列的映射 | 下标为 CPU 编号,对应值为映射的硬件队列编号。比如 set->mq_map[cpu_j] = hw_queue_i,其中 i 和 j 互不相干
|
.tags
| blk_mq_tags**,实际作为一个 (blk_mq_tags*)[] 数组使用,长度为 CPU 个数
| 管理 request 分配,为每个 hwq 分配 set->tags[hw_queue_id]
|
硬件队列关联了 tag(从而间接关联到 request),其结构体对应于 blk_mq_tags:
| 字段 | 类型 | 用途 | 备注 |
|---|---|---|---|
.static_rqs
| request**,实际作为一个 (request*)[] 数组使用,长度为队列深度参数 set->queue_depth
| 从 buddy 中预先分配 set->queue_depth 个 request 实例,等待后续使用
| 该数组需要 tag 分配,由搭配的一个位图(sbitmap)来快速获得空闲的 tag。每一次派发 request 前需要获取到 tag 与之绑定
|
.rqs
| request**,实际作为一个 (request*)[] 数组使用,长度为队列深度参数 set->queue_depth
| 从 static_rqs[tag] 中获得的 request 实例在非电梯调度下会放入该数组中(同下标),表示 in-flight request
|
tag-set 与 ctx 的关系可以看下图:
框架的初始化
流程之 nvme_probe
blk-mq 框架在 driver 层完成初始化,以 nvme 设备为例,初始化阶段分为上下半部。上半部开始于 nvme_probe 函数:
nvme_probe(...)
dev = kzalloc_node(...)
...
INIT_WORK(..., nvme_reset_work)
在异步流程中
nvme_reset_work(work)
dev = container_of(work, ...)
...
nvme_dev_add(dev)
...
nvme_dev_add(dev)
dev->tagset.ops = nvme_mq_ops
dev->tagset.nr_hw_queues = ...
hwq的数目最终会被限制到min(硬件队列数,CPU数)
dev->tagset.queue_depth = min(dev->q_dep, 10240) - 1
这里tagset的队列深度还不是最后确定的,如果后续过程构造失败,kernel会尝试深度折半继续重试,直到深度只有1
dev->tagset.flags = BLK_MQ_F_SHOULD_MERGE
blk_mq_alloc_tag_set(alias set = dev->tagset)
set->tags = kcalloc_node(nr_cpu_ids, sizeof *, ...)
这里说明tags是一个元素类型为blk_mq_tags*,长度为CPU数的数组
set->mq_map = kcalloc_node(nr_cpi_ids, sizeof, ...)
mq_map是一个元素类型为int,长度为CPU数的数组
blk_mq_update_queue_map(set)
这个过程完成了CPU到hw queue的映射
for-each cpu: set->mq_map[cpu] = 0
set->ops->map_queues(ret)
对应于实现nvme_pci_map_queues
for-each hwq: for-each cpu-in-mask: set->mq_map[cpu] = queue
blk_mq_alloc_rq_maps(set)
构造set->tags[0...hctx_max-1]
忽略深度折半的特殊情况
for-each hwq, i: __blk_mq_alloc_rq_map(set, alias hctx_idx = i)
构造set->tags[hctx_idx]
set->tags[hctx_idx] = blk_mq_alloc_rq_map(set, hctx_id, ...)
获取numa_node node
定义(对应队列的)tags = blk_mq_init_tags(...)
tags->nr_tags和tags_nr_reserved_tags的确认
以及sbitmap的构造
tags->rqs = kcalloc_node(nr_tags, sizeof *)
rqs是一个元素类型为request*的长度为队列深度的数组
tags->static_rqs = kcalloc_node(nr_tgags, sizeof *)
return tags
blk_mq_alloc_rqs(set, set->tags[hctx_id], hctx_id, queue_depth)
构造tags->page_list,按队列深度d将带payload的request大小乘上d,从buddy分配对应的page,(换行)\
并且用page的虚拟地址存放到static_rqs[...],其中多个page可以通过page_list遍历到
分配request后,可以从set->ops->init_request自定义初始化request
dev->ctrl.tagset = dev->tagset
流程之 nvme_alloc_ns
下半部的 caller 调用栈为:
nvme_alloc_ns
nvme_validate_ns
nvme_scan_ns_list
nvme_scan_work(async)
nvme_init_ctrl
其中,nvme_init_ctrl 是使用 workqueue 异步触发 nvme_scan_work。
nvme_alloc_ns(ctrl, nsid)
nvme_ns *ns = kzalloc_node(...)
ns->queue = blk_mq_init_queue(ctrl->tagset) ⭐
ns->queue->queuedata = ns
ns->ctrl = ctrl
...
disk = alloc_disk_node(...)
disk->fops = nvme_fops
disk->private_data = ns
disk->queue = ns->queue
ns->disk = disk
...
可以看出这里正式进入了 blk-mq 框架,并且把在上半部就构造好的 tagset 也传递到框架中。
此外,gendisk 也建立了与 nvme 的关联,与 blk-mq 有关的地方就是 disk->queue 是来自 ns 且经过 blk-mq 框架构造的 queue。
流程之 blk_mq_init_queue
这个流程是 request_queue 的初始化流程,涉及其绑定的 ctx 和 hctx。
blk_mq_init_queue(set)
q = blk_alloc_queue_node(GFP_KERNEL, ...)
略,只返回一个未(半)构造已分配的request queue
return blk_mq_init_allocated_queue(set, q)
q->mq_ops = set->ops
q->queue_ctx = alloc_percpu(...)
q->queue_hw_ctx = kcalloc_node(nr_cpu_ids)
hwctx是一个元素为指针,长度为CPU个数的数组
q->mq_map = set->mq_map
blk_mq_realloc_hw_ctxes(set, q)
这里实际分配hctx实例
for-each(i, 0, set->nr_hw_queues)
only for empty hctxs[i]
hctxs[i] = kzalloc_node(...)
blk_mq_init_hctx(q, set, hctxs[i], alias hctx_idx = i)
hctx->queue = q
hctx->flag &= ~shared
hctx->tags = set->tags[hctx_idx]
hctx->ctxs = kmalloc_array_node(nr_cpu_ids, sizeof *)
hctx->nr_ctx = 0
set->ops->init_hctx(hctx, ...)
nvme的话主要是关联驱动层nvme_queue和hctx的关系
blk_mq_sched_init_hctx(q, hctx, hctx_idx)
构造hctx->sched_tags
elevator e = q->elevator
blk_mq_sched_alloc_tags(q, hctx, hctx_id)
hctx->sched_tags = blk_mq_alloc_rq_map()
重复,见nvme流程,构造sched_tags[...]每个元素实例
blk_mq_alloc_rqs(set, hctx->sched_tags, ...)
重复,见nvme流程,static_rq相关
e->type->ops.mq.init_hctx(...)
差不多吧,只是变成了sched_tag
hctx->fq = ...
blk_mq_init_request()
重复了,略
TODO 这里会有调度层hctx构造
q->nr_queues = nr_cpu_ids
blk_queue_make_request
注册q->make_request_fn回调为blk_mq_make_request
q->nr_batching = BLK_BATCH_REQ = 32
q->nr_request = set->queue_depth
blk_mq_init_cpu_queues(q, set->nr_hw_queues)
for-each cpu, i:
get percpu ctx
ctx->cpu = i
ctx->queue = q
...
blk_mq_add_queue_tag_set(set, q)
基本上是关联q->tag_set = set
以及处理shared模式下的hctx,略
blk_mq_map_swqueue(q)
处理软件队列到硬件对垒的映射
for-each cpu, i:
hctx_id = q->mq_map[i]
从map获取CPU到hctx的映射ID
hctx = q->queue_hw_ctx[q->mq_map[cpu]]
cpumask_set_cpu(i, hctx->cpumask)
ctx->index_hw = hctx->nr_ctx
hctx->ctxes[hctx->nr_ctx++] = ctx
一个hctx可以对应多个ctx,因此用index_hw表示ctx在hctx->ctxes[]中的下标
for-each hctx(q, hctx, i):
hctx->tags = set->tags[i]
...
elevator_init_mq(q)
选择默认的elevator
单队列选择mq-deadline
多队列或者没有mq-deadline选择none
return q
框架的 IO 流程
流程之提交 IO
userspace 进行的 IO 操作,具体的 IO 类型和操作对象会以 bio 结构体描述,并在内核中会通过 submit_bio 统一接口进行提交。
submit_bio(bio)
...
IO accounting stuff
...
return generic_make_request_(bio)
q = bio->bi_disk->queue
...
workaround for stacked devices
...
return q->make_request_fn(q, bio) ⭐
从前面的流程可以知道,blk-mq 下的 make_request_fn 注册实例为 blk_mq_make_request。
blk_mq_init_allocated_queue()
...
blk_queue_make_request(q, blk_mq_make_request)
set default blk-mq limits
q->make_request_fn = blk_mq_make_request
...
流程之处理 IO
处理 IO 简而言之就是把 bio 转换为 request 结构体,并插入到请求队列中。
相较于提交 IO 是在当前进程的内核栈上进行,处理 IO 还有可能会在 kblockd 内核线程中异步执行。
blk_mq_make_request(q, bio)
按需执行bio split(通常是按软硬件限制)
按需合并到进程的plug队列,成功则结束
precondition: !FLUSH_FUA && !NOMERGE
blk_mq_sched_bio_merge
尝试将sched队列中的pending request合并,成功则返回
wbt_wait
当超过writeback limit时,在这里提供一个阻塞点
blk_mq_get_request
返回一个request,需要static_rqs和sbitmap搭配使用
note: 上面的按需合并没有完成,因此需要request
条件分支:
1. flush or fua
需要尽快下达,跳过scheduler,request插入到单独的flush队列,唤醒执行hctx
2. plug && q->nr_hw_queues == 1
单队列设备且plug则加入plug的mq_list中
3. plug && !no_merge
和case2差不多,但这里是多队列的plug,略
4. q->nr_hw_queues > 1 && sync
多队列,没有plug走blk_mq_try_issue_directly
读操作的话,应该适用于这里
5. others
走blk_mq_sched_insert_request
这里会继续细分情况,比如是否flush,是否有elevator
如果是case4:
• 非电梯情况下,就是直走到driver层提供的入队函数
• 否则,走电梯sched_insert
如果是case5:
• 非电梯情况下,会插入到ctx队列中
• 否则,走电梯sched_insert
还需要查看run_queue设置,如果有,紧接着blk_mq_run_hw_queue执行hctx来批量派发IO
一般来说是run_queue = true,除非driver层告知hctx不可用
执行 hctx(hw queue)的过程 blk_mq_run_hw_queue 可能是 sync(同步)的,也可能是 async(异步)的。在上述的条件分支中:
- 如果是 case4,那就是 sync。
- 如果是 case5,那就是 async。
blk_mq_run_hw_queue
__blk_mq_delay_run_hw_queue
__blk_mq_run_hw_queue
blk_mq_sched_dispatch_requests
这里就是sync入口
blk_mq_sched_dispatch_requests(hctx)
LIST_HEAD(rq_list)
if hctx->dispatch is not empty
list_splice_init(hctx->dispatch, rq_list)
在hctx实例中,dispatch字段是实质意义的请求队列,现在将其移交到栈上申请的rq_list
分几种情况:
1. blk_mq_dispatch_rq_list
优先派发之前在hctx中没有派发的请求到驱动
2. blk_mq_do_dispatch_sched
将sched队列中的请求移入rq_list,然后调用blk_mq_dispatch_rq_list,派发到驱动
3. blk_mq_do_dispatch_ctx
在hctx busy的情况下,直接将ctx的rq移入到rq_list,然后派发给驱动, 公平起见,会考虑到轮流对多个ctx执行派发
4. blk_mq_dispatch_rq_list
其它情况将rq_list中请求派发给驱动处理
这个过程比较复杂,整体来看就是按照 IO 的特征来进行划分:
- 设备:单队列还是多队列。
- 硬件队列(hctx):繁忙还是空闲。
- IO 调度器(电梯):是否附着于 blk-mq。
- 蓄流操作:是否使能 plug。
- 请求类型:同步还是异步。
处理分类就是依据上面的特征来组合出不同分支路径:
- 是否紧急,紧急直接下发,flush->hctx。
- 是否慢速设备,也就是单队列且 plug。
- 多队列 plug。
- IO 调度器附着,表示与 ctx 互斥。
- plug 且 nomerges 且无附着,基本是前面条件的 corner case 的意思。
- 是否跳过 ctx,即无 IO 调度器附着、设备多队列、hctx 空闲且 IO 同步。
- 默认分支,无 IO 调度且无 plug 的情况。
- 隐藏分支,本次 IO 处理失败,下次按照紧急情况处理。
上面组合后的结果一般是遵循如下的队列顺序:
-> flush ------------------------>
request -> [pluglist] -> [ctx || sched] -> hctx -> drivers/...
一些备注:
- IO 调度器队列与软件队列是互斥关系。IO 调度器附着到 blk-mq 则不使用 ctx。
- plug 是可选的。
- hctx 空闲时,部分请求是可以跳过 ctx 直达 hctx(比如路径 6)。
根据前人(一些原因,我不能提供参考链接)的分析结果,以下条件适用于默认路径(7):
- EMMC 设备(高速无 plug 单队列)的 IO 请求。
- NVME 设备,异步的 IO 请求。
- NVME 设备,同步的 IO 请求,并且 hctx 繁忙。
回到 blk_mq_run_hw_queue,异步流程会有稍微不同的入口:
blk_mq_run_hw_queue
__blk_mq_delay_run_hw_queue
- __blk_mq_run_hw_queue
+ kblockd_mod_delayed_work_on
+ mod_delayed_work_on(cpu = hctx_next_cpu, kblockd_workqueue, dwork = hctx->run_work, delay = 0)
任务分配的注册在前面的初始化流程:
blk_mq_init_hctx
...
INIT_DELAYED_WORK(&hctx->run_work, blk_mq_run_work_fn)
这里涉及到 workqueue 机制,关注一下它的使用 context:
- 线程实例:
kblockd。 - 任务类型:
delayed_work类型的hctx->run_work。 - 具体任务:其
run_work对应于blk_mq_run_work_fn。
blk_mq_run_work_fn(work)
hctx = container_of(work, ...)
__blk_mq_run_hw_queue(hctx)
其实 blk_mq_run_work_fn 峰回路转,还是回到了 sync 流程,只不过是交给了 kblockd 来处理。
不太重要的细节
blk-mq的硬件队列与驱动层的队列无关。- 虽然软件队列一般认为是 per-cpu 级别,但是 maintainer 也指出:如果在 NUMA 架构中,L3 缓存足够大的话,软件队列可以设置为 per-socket 级别,这样也许能从 cache 友好和锁竞争中获取一个平衡点。
- 硬件队列个数在不同的场合下是有歧义的,因为 kernel 里面会把超过 CPU 个数的硬件队列数目当作看不见(原因是超出部分没有意义),所以并不绝对等于硬件意义上的硬件队列个数。
- tag 虽然是给硬件队列使用,但是
blk_mq_tags实际长度是按 CPU 个数给的。 - tag 对应的
request数虽然是set提供的队列深度数,但是每次分配失败的话,会尝试把队列深度数目折半,这也会实际影响到set->queue_depth。 - 预分配
request的每个实例中其实还藏有 driver 层所需要的 payload。 ns->queue即是request_queue实例。- 提交 IO 过程中,
generic_make_request已经随着 SQ 框架的移除也被移除,改为blk_mq_submit_bio,不过本质不变。 - 处理 IO 过程中,case4 走 sync 运行 hctx 是因为 IO 操作本来就是 sync 类型的。
- “派发到 driver 层”指的是最终被
queue_rq接口调用,具体实现和驱动是强相关的。
一些使用建议
Q. 我用的是比较传统的单队列设备,需要回归单队列框架吗?
A. 不需要。一是 blk-mq 实测性能仍高于 sq 框架,二是内核版本 5.0 后已经把 sq 框架彻底删了。
Q. 多队列框架下是否需要使用 IO 调度器?
A. 如果是 HDD,要。对于(足够高性能的)SSD 的话,比方说你需要公平调度,或者做一些 QoS 也许用得着,但只看性能的话,这是一个开放的话题(不服跑个分吧)。
Q. 如果确实需要选用 IO 调度器,该怎么选?
A. redhat 文档 中给出了一些场景选择,为了节省你的 IO,我把要点摘抄下来了:
| Use case | Disk scheduler |
|---|---|
| Traditional HDD with a SCSI interface | Use mq-deadline or bfq.
|
| High-performance SSD or a CPU-bound system with fast storage | Use none, especially when running enterprise applications. Alternatively, use kyber.
|
| Desktop or interactive tasks | Use bfq.
|
| Virtual guest | Use mq-deadline. With a host bus adapter (HBA) driver that is multi-queue capable, use none.
|
Q. 你这些调度器选项太 naive 了,有没有更加 pro 的调优选项?
A. 是我太菜了……这里有另外一份 redhat 文档 可以自行参考。
TODO(已鸽🕊)
毫不意外的又鸽了相当一部分的内容:
- 完成 IO 流程(中断相关)。
- 处理 IO 流程的细节完善。
- 合并、拆分 IO 流程。
- 更新内核版本。
References
Multi-Queue Block IO Queueing Mechanism (blk-mq) – The Linux Kernel Archives
Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
Chapter 11. Setting the disk scheduler – Red Hat Customer Portal
Chapter 32. Factors affecting I/O and file system performance – Red Hat Customer Portal
An Introduction to the Linux Kernel Block I/O Stack – IBM