前言
前段时间整理了 Asio 的 C++20 协程适配,那里只关注 asio::awaitable 的实现方式,而忽略了背后 io_context.run() 的运行机制(对不起,他写得实在太变态了 orz)。因此打算顺便补上一些笔记。
不过这篇文章预期会写得比较粗略。个人整理任务调度的源码其实只是了解 io_uring_service 前所必要的回顾,但是翻过后发现 Asio 并没有使用 io_uring 的高级特性,本想着再从中抠点代码给我的 io_uring 示例 添砖加瓦的,现在已经落空了,这篇文章终究只是副产物。
总之就随便过一下流程吧,代码基于 commit ed5db1b50136bace796062c1a6eab0df9a74f8fa。
NOTE: 要想在 Asio 启用 io_uring,请参考 Asio 1.21.0 Revision History 的配置说明。
UPDATE: 澄清一下,是笔者的源码搜索姿势太菜引起了误解。Asio 用到了 io_uring 的 register buffers 和 IO drain 等特性(依赖 liburing),看来有必要再深入一点。
run()
直奔主题,看下 io_context::run() 干了什么。
io_context::count_type io_context::run()
{
asio::error_code ec;
count_type s = impl_.run(ec);
asio::detail::throw_error(ec);
return s;
}
简单来说,它只是委托给了 impl_ 成员(context 实现类)的同名函数 run()。
impl
什么是 impl_?至少要知道它是什么类型。
class io_context
: public execution_context
{
private:
typedef detail::io_context_impl impl_type;
// ...
// The implementation.
impl_type& impl_;
};
namespace detail {
#if defined(ASIO_HAS_IOCP)
typedef win_iocp_io_context io_context_impl;
class win_iocp_overlapped_ptr;
#else
typedef scheduler io_context_impl;
#endif
// ...
}
如果是 Linux,impl_ 成员对应于 detail::scheduler 类型;如果是 Windows,则是 detail::win_iocp_io_context。下面只考虑 Linux 平台。
impl_.run()
std::size_t scheduler::run(asio::error_code& ec)
{
ec = asio::error_code();
if (outstanding_work_ == 0)
{
stop();
return 0;
}
thread_info this_thread;
this_thread.private_outstanding_work = 0;
thread_call_stack::context ctx(this, this_thread);
mutex::scoped_lock lock(mutex_);
std::size_t n = 0;
for (; do_run_one(lock, this_thread, ec); lock.lock())
if (n != (std::numeric_limits<std::size_t>::max)())
++n;
return n;
}
std::size_t scheduler::do_run_one(mutex::scoped_lock& lock,
scheduler::thread_info& this_thread,
const asio::error_code& ec)
{
while (!stopped_)
{
if (!op_queue_.empty())
{
// Prepare to execute first handler from queue.
operation* o = op_queue_.front();
op_queue_.pop();
bool more_handlers = (!op_queue_.empty());
if (o == &task_operation_)
{
task_interrupted_ = more_handlers;
if (more_handlers && !one_thread_)
wakeup_event_.unlock_and_signal_one(lock);
else
lock.unlock();
task_cleanup on_exit = { this, &lock, &this_thread };
(void)on_exit;
// Run the task. May throw an exception. Only block if the operation
// queue is empty and we're not polling, otherwise we want to return
// as soon as possible.
task_->run(more_handlers ? 0 : -1, this_thread.private_op_queue);
}
else
{
std::size_t task_result = o->task_result_;
if (more_handlers && !one_thread_)
wake_one_thread_and_unlock(lock);
else
lock.unlock();
// Ensure the count of outstanding work is decremented on block exit.
work_cleanup on_exit = { this, &lock, &this_thread };
(void)on_exit;
// Complete the operation. May throw an exception. Deletes the object.
o->complete(this, ec, task_result);
this_thread.rethrow_pending_exception();
return 1;
}
}
else
{
wakeup_event_.clear(lock);
wakeup_event_.wait(lock);
}
}
return 0;
}
这里就要求我们继续挖掘不少概念,比如:
- outstanding work
- thread info
- operation queue
- task operation
- task cleanup
- work cleanup
- task run
- operation complete
一个个来吧。
outstanding work
run() 实现中,首先看到的是 outstanding_work_。这是一个计数器,外部接口关联 work_started() 和 work_finished()。从 N3388 可以了解到,它决定了 io_context.run() 是否保持阻塞执行:
- 只要还存在 outstanding work,
io_context的执行就不会停止。 - 未完成的异步函数算作一个 outstanding work。
A call to io_service::run() blocks while there is outstanding work.
Outstanding work is logically represented by an object of type io_service::work. The io_service::run() function blocks if one or more io_service::work objects exist, and all asynchronous operations behave as-if they have an associated io_service::work object.
注意这份文件比较旧了,
io_service就是 Asio 重构前的io_context,不能和后面提的 service 混为一谈。
io_context 的停止操作还可能被其它的接口所影响,比如:
- work guard。可理解为强行 outstanding+1,因此用户不手动释放的话,
io_context就一直在跑(宁可阻塞也不退出)。一般用于用户已知后续还有任务要提交,可避免io_context没任务后挂起又拉回来的行为。 stop()函数。实现上唤醒其它线程并打上stop_ = true标记,从do_run_one()可以看出,会直接跳过执行,并且跳回到run()后因不符合for循环要求而退出。
一个 io_uring 的例子就是在请求准备阶段给 outstanding work 增加一位:
// 文件:io_uring_service.ipp,位于 start_op() 函数
if (::io_uring_sqe* sqe = get_sqe())
{
op->prepare(sqe);
::io_uring_sqe_set_data(sqe, &io_obj->queues_[op_type]);
scheduler_.work_started();
post_submit_sqes_op(lock);
}
然后在 do_run_one() 内部的 ~work_cleanup() 给 outstanding work 减少一位:
struct scheduler::work_cleanup
{
~work_cleanup()
{
if (this_thread_->private_outstanding_work > 1)
{
asio::detail::increment(
scheduler_->outstanding_work_,
this_thread_->private_outstanding_work - 1);
}
else if (this_thread_->private_outstanding_work < 1)
{
scheduler_->work_finished();
}
this_thread_->private_outstanding_work = 0;
#if defined(ASIO_HAS_THREADS)
if (!this_thread_->private_op_queue.empty())
{
lock_->lock();
scheduler_->op_queue_.push(this_thread_->private_op_queue);
}
#endif // defined(ASIO_HAS_THREADS)
}
// ...
};
除此以外 executor 机制也会影响 outstanding work。比如通过 co_spawn 派生协程时,从 launch(),co_spawn_work_guard 到 basic_executor_type 等一系列流程。这方面没仔细调试过,只是提一下。
thread info
run() 实现中,this_thread 变量为 thread_info 别名,实际为 scheduler_thread_info 类型:
struct scheduler_thread_info : public thread_info_base
{
op_queue<scheduler_operation> private_op_queue;
long private_outstanding_work;
};
其中 thread_info_base 主要涉及 allocate() 和 deallocate() 定制。这一块写得有点抽象,理解为提供线程私有的内存分配即可,略了。
而 thread info 本身比较重要的点就是无锁优化,可以让本线程在合适的时机尝试缓存一定的 operation,然后一次性的连接上全局的 operation queue;以及应用于 executors 机制中的 defer 操作,意思相同,就是免去不必要的锁和线程唤醒,N4242 有非常完善的讨论。
operation queue
不管是线程共享的 scheduler,还是线程本地运行 do_run_one() 私有的 this_thread,都具有 op_queue 类型的操作队列:前者为 op_queue_ 成员,后者为 private_op_queue 成员。
template <typename Operation>
class op_queue
: private noncopyable
{
public:
// Constructor.
op_queue()
: front_(0),
back_(0)
{
}
// Destructor destroys all operations.
~op_queue()
{
while (Operation* op = front_)
{
pop();
op_queue_access::destroy(op);
}
}
// push() / pop() ...
private:
friend class op_queue_access;
// The front of the queue.
Operation* front_;
// The back of the queue.
Operation* back_;
};
这里的核心问题在于:Operation 是谁。
class scheduler // ...
{
// ...
typedef scheduler_operation operation;
// The queue of handlers that are ready to be delivered.
op_queue<operation> op_queue_;
// ...
};
非常简单的问题,Operation 就是 scheduler_operation 类型。
scheduler operation
// Base class for all operations. A function pointer is used instead of virtual
// functions to avoid the associated overhead.
// 类型名字后面的 handler_tracking 机制(ASIO_INHERIT_TRACKED_HANDLER)也是非常劲爆的排查工具
// 可以直接生成可视化的异步操作调用图!
// 可惜没时间了解实现,客官们感兴趣自己看下
class scheduler_operation ASIO_INHERIT_TRACKED_HANDLER
{
public:
typedef scheduler_operation operation_type;
void complete(void* owner, const asio::error_code& ec,
std::size_t bytes_transferred)
{
func_(owner, this, ec, bytes_transferred);
}
void destroy()
{
func_(0, this, asio::error_code(), 0);
}
protected:
typedef void (*func_type)(void*,
scheduler_operation*,
const asio::error_code&, std::size_t);
scheduler_operation(func_type func)
: next_(0),
func_(func),
task_result_(0)
{
}
// Prevents deletion through this type.
~scheduler_operation()
{
}
private:
friend class op_queue_access;
scheduler_operation* next_;
func_type func_;
protected:
friend class scheduler;
unsigned int task_result_; // Passed into bytes transferred.
};
很显然,就是一个同步回调过程。起码脑海里显现出来的蓝图就是,事件的完成操作就是不断从操作队列拿出操作,其操作的函数签名完全相同(func_type),只需执行回调。非常简单的实现。
非常简单?简单个毛线啊。协程意义下的 operation 类型抹除非常复杂,调试干扰项相当多(看上一篇文章就知道后果有多惨重了),推荐使用普通函数然后通过 asio::post() 观察行为,会轻松不少。
不管是协程用途的 co_spawn(),还是直接的 asio::post(),内部的流程都会走到共同的代码。在最简单的情况下(设完成令牌为 void(void) 签名的回调函数),post 途径:
post(executor, completion_token)
initiation = initiate_post_with_executor(executor)
return async_initiate(initiation, completion_token)
return async_result::initiate(initiation, completion_token /*, args... */)
return initiation(token, ...)
和以前分析过的一样,其中 initiation 即 initiate_post_with_executor 需要调用 operator():
template <typename Executor>
class initiate_post_with_executor
{
public:
typedef Executor executor_type;
explicit initiate_post_with_executor(const Executor& ex)
: ex_(ex)
{
}
executor_type get_executor() const noexcept
{
return ex_;
}
template <typename CompletionHandler>
void operator()(CompletionHandler&& handler,
enable_if_t<
execution::is_executor<
conditional_t<true, executor_type, CompletionHandler>
>::value
>* = 0,
enable_if_t<
!detail::is_work_dispatcher_required<
decay_t<CompletionHandler>,
Executor
>::value
>* = 0) const
{
associated_allocator_t<decay_t<CompletionHandler>> alloc(
(get_associated_allocator)(handler));
asio::prefer(
asio::require(ex_, execution::blocking.never),
execution::relationship.fork,
execution::allocator(alloc)
// 关键的 execute()
).execute(
// 在最简单的情况下,bind_handler() 返回
// asio::detail::binder0 类型
// 也就是 0 个参数的意思
asio::detail::bind_handler(
static_cast<CompletionHandler&&>(handler)));
}
// ...
};
顺便补充一下 binder0,是个很简单的类型:
- 只存放
handler,也就是完成令牌。(如果是其它的非 0 类型,需要额外存放参数列表) - 通过
operator()调用handler()。
接下来需要关注 execute() 行为,在这里传入的参数 f 就是 binder0(completion_token):
template <typename Allocator, uintptr_t Bits>
template <typename Function>
void io_context::basic_executor_type<Allocator, Bits>::execute(
Function&& f) const
{
typedef decay_t<Function> function_type;
// Invoke immediately if the blocking.possibly property is enabled and we are
// already inside the thread pool.
if ((bits() & blocking_never) == 0 && context_ptr()->impl_.can_dispatch())
{
// Make a local, non-const copy of the function.
function_type tmp(static_cast<Function&&>(f));
#if !defined(ASIO_NO_EXCEPTIONS)
try
{
#endif // !defined(ASIO_NO_EXCEPTIONS)
detail::fenced_block b(detail::fenced_block::full);
static_cast<function_type&&>(tmp)();
return;
#if !defined(ASIO_NO_EXCEPTIONS)
}
catch (...)
{
context_ptr()->impl_.capture_current_exception();
return;
}
#endif // !defined(ASIO_NO_EXCEPTIONS)
}
// Allocate and construct an operation to wrap the function.
typedef detail::executor_op<function_type, Allocator, detail::operation> op;
typename op::ptr p = {
detail::addressof(static_cast<const Allocator&>(*this)),
op::ptr::allocate(static_cast<const Allocator&>(*this)), 0 };
// 一个被抹除得只剩指针的.p
p.p = new (p.v) op(static_cast<Function&&>(f),
static_cast<const Allocator&>(*this));
ASIO_HANDLER_CREATION((*context_ptr(), *p.p,
"io_context", context_ptr(), 0, "execute"));
// 在这里 push
context_ptr()->impl_.post_immediate_completion(p.p,
(bits() & relationship_continuation) != 0);
p.v = p.p = 0;
}
void scheduler::post_immediate_completion(
scheduler::operation* op, bool is_continuation)
{
#if defined(ASIO_HAS_THREADS)
if (one_thread_ || is_continuation)
{
if (thread_info_base* this_thread = thread_call_stack::contains(this))
{
++static_cast<thread_info*>(this_thread)->private_outstanding_work;
static_cast<thread_info*>(this_thread)->private_op_queue.push(op);
return;
}
}
#else // defined(ASIO_HAS_THREADS)
(void)is_continuation;
#endif // defined(ASIO_HAS_THREADS)
work_started();
mutex::scoped_lock lock(mutex_);
op_queue_.push(op);
wake_one_thread_and_unlock(lock);
}
很显然,在 io_context::basic_executor_type::execute() 里面产生了 operation 并 push 到 operation queue 中。其中,operation 的真实面目是 executor operation。
executor operation
下面给出 executor operation 的全貌,还得找一下 op::ptr 到底是什么。
template <typename Handler, typename Alloc,
typename Operation = scheduler_operation>
class executor_op : public Operation
{
public:
// op::ptr 中的 ptr 类型藏在这里
ASIO_DEFINE_HANDLER_ALLOCATOR_PTR(executor_op);
template <typename H>
executor_op(H&& h, const Alloc& allocator)
// scheduler_operation::func_指向 executor_op::do_complete
// 因此 do_run_one 消费任务时:
// o->complete(this <scheduler>, ec, task_result)
// func_(scheduler, this <scheduler_op>, ec, bytes_transferred = task_result);
// executor_op::do_complete(...)
// handler(...)
: Operation(&executor_op::do_complete),
handler_(static_cast<H&&>(h)),
allocator_(allocator)
{
}
static void do_complete(void* owner, Operation* base,
const asio::error_code& /*ec*/,
std::size_t /*bytes_transferred*/)
{
// Take ownership of the handler object.
ASIO_ASSUME(base != 0);
executor_op* o(static_cast<executor_op*>(base));
Alloc allocator(o->allocator_);
ptr p = { detail::addressof(allocator), o, o };
ASIO_HANDLER_COMPLETION((*o));
// Make a copy of the handler so that the memory can be deallocated before
// the upcall is made. Even if we're not about to make an upcall, a
// sub-object of the handler may be the true owner of the memory associated
// with the handler. Consequently, a local copy of the handler is required
// to ensure that any owning sub-object remains valid until after we have
// deallocated the memory here.
Handler handler(static_cast<Handler&&>(o->handler_));
p.reset();
// Make the upcall if required.
if (owner)
{
fenced_block b(fenced_block::half);
ASIO_HANDLER_INVOCATION_BEGIN(());
// 用户回调
static_cast<Handler&&>(handler)();
ASIO_HANDLER_INVOCATION_END;
}
}
private:
Handler handler_;
Alloc allocator_;
};
ptr 隐藏在 ASIO_DEFINE_HANDLER_ALLOCATOR_PTR 里面,并且所有实现都用宏表达,直接看代码比较麻烦,还是打印吧:
(gdb) macro expand ASIO_DEFINE_HANDLER_ALLOCATOR_PTR(executor_op);
struct ptr {
const Alloc* a;
void* v;
executor_op* p;
~ptr() { reset(); }
static executor_op* allocate(const Alloc& a) {
typedef typename ::asio::detail::get_recycling_allocator<
Alloc, ::asio::detail::thread_info_base::default_tag>::type
recycling_allocator_type;
typename std::allocator_traits<
recycling_allocator_type>::template rebind_alloc<executor_op>
a1(::asio::detail::get_recycling_allocator<
Alloc, ::asio::detail::thread_info_base::default_tag>::get(a));
return a1.allocate(1);
}
void reset() {
if (p) {
p->~executor_op();
p = 0;
}
if (v) {
typedef typename ::asio::detail::get_recycling_allocator<
Alloc, ::asio::detail::thread_info_base::default_tag>::type
recycling_allocator_type;
typename std::allocator_traits<
recycling_allocator_type>::template rebind_alloc<executor_op>
a1(::asio::detail::get_recycling_allocator<
Alloc, ::asio::detail::thread_info_base::default_tag>::get(*a));
a1.deallocate(static_cast<executor_op*>(v), 1);
v = 0;
}
}
}
ptr 的实现回到了 thread info 的内存分配机制,这一块以后有机会再调研吧。
现在可以理解为 ptr 等价于一个三元组 {allocator, void*, executor_op*}。其中完成令牌副本的实例以 placement new 的形式存放在 void *v 的位置,并由 executor_op *p 指向该实例地址 v。
下半部总结
void sayhello() {
std::cout << "hello" << std::endl;
}
int main() {
asio::io_context io_context;
asio::post(io_context.get_executor(), sayhello);
io_context.run();
}
对照上面示例并回到 impl_.run() 实现,do_run_one() 下半部分 else 分支的代码已经足以了解:
- 投递任务,executor.execute() 会生成抹除类型的 operation。
- 由于投递的任务允许“立即完成”(post immediate completion),插入到 operation queue。
- 消费任务,从 operation queue 获得的 operation 调用 complete 接口实现完成操作(do complete)。
- 所谓完成操作,就是调用用户声明的完成令牌。
这里由于不存在 IO 行为,因此具有“立即完成”的特性。
后续还有不同的 service 来提供不同行为的 operation,这些通常需要 IO 或者定时,因此并非立即完成。
task operation
在 do_run_run() 实现中,调度器尝试从 operation queue 中拿出一个 operation,但是特判了 task_operation_。这个概念就很重要,涉及到等待就绪(reactor 前提)或者等待完成(proactor 前提)操作。
task operation 本身在数据结构上的实现非常简单:
// 作为 scheduler 的成员
// Operation object to represent the position of the task in the queue.
struct task_operation : operation
{
task_operation() : operation(0) {}
} task_operation_;
但是仅是这样的话,operation queue 中并不会存在 task operation。这需要初始化过程:
void scheduler::init_task()
{
mutex::scoped_lock lock(mutex_);
if (!shutdown_ && !task_)
{
task_ = get_task_(this->context());
op_queue_.push(&task_operation_);
wake_one_thread_and_unlock(lock);
}
}
这个初始化的触发时机就说来话长了,需要了解 Asio 的基本原理。
Basic Asio Anatomy
Asio 的基本操作可以拆分成两个图和六个步骤:
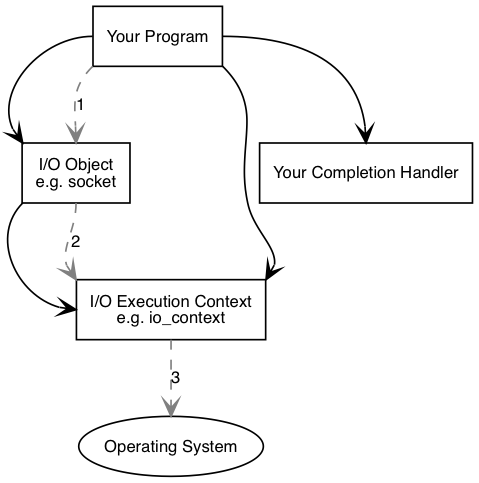 提交 IO
提交 IO
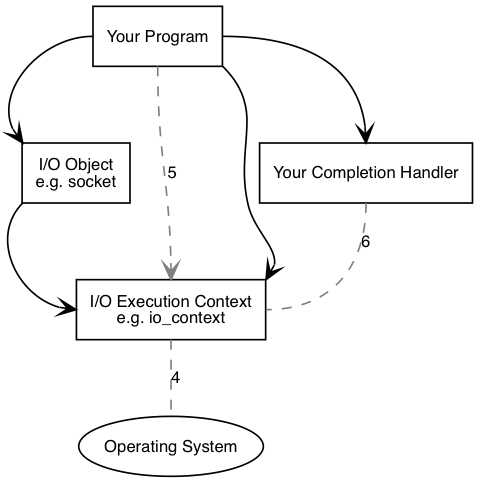 完成 IO
完成 IO
Basic Asio Anatomy
When an asynchronous operation is used, a different sequence of events occurs.
- Your program initiates the connect operation by calling the I/O object.
- The I/O object forwards the request to the I/O execution context.
- The I/O execution context signals to the operating system that it should start an asynchronous connect.
Time passes. (In the synchronous case this wait would have been contained entirely within the duration of the connect operation.)
- The operating system indicates that the connect operation has completed by placing the result on a queue, ready to be picked up by the I/O execution context.
- When using an io_context as the I/O execution context, your program must make a call to io_context::run() (or to one of the similar io_context member functions) in order for the result > to be retrieved. A call to io_context::run() blocks while there are unfinished asynchronous operations, so you would typically call it as soon as you have started your first asynchronous > operation.
- While inside the call to io_context::run(), the I/O execution context dequeues the result of the operation, translates it into an error_code, and then passes it to your completion > handler.
要讨论上面 task operation 的初始化,要从 IO object 的行为说起。
io object
在 Asio 中如果需要 IO 操作,那就需要产生至少一个 IO object。以 asio::ip::tcp::acceptor 为例,其构造函数为:
basic_socket_acceptor(const executor_type& ex,
const endpoint_type& endpoint, bool reuse_addr = true)
: impl_(0, ex)
{
// ...
}
这里 impl_ 是 acceptor 的成员,其类型是一个跨平台跨实现的 IO object 实现类:
#if defined(ASIO_WINDOWS_RUNTIME)
detail::io_object_impl<
detail::null_socket_service<Protocol>, Executor> impl_;
#elif defined(ASIO_HAS_IOCP)
detail::io_object_impl<
detail::win_iocp_socket_service<Protocol>, Executor> impl_;
// 我们看这个实现
#elif defined(ASIO_HAS_IO_URING_AS_DEFAULT)
detail::io_object_impl<
detail::io_uring_socket_service<Protocol>, Executor> impl_;
#else
detail::io_object_impl<
detail::reactive_socket_service<Protocol>, Executor> impl_;
#endif
再到 IO object 的构造:
template <typename IoObjectService,
typename Executor = io_context::executor_type>
class io_object_impl
{
// Construct an I/O object using an executor.
explicit io_object_impl(int, const executor_type& ex)
// IO object 需要使用 service
: service_(&asio::use_service<IoObjectService>(
io_object_impl::get_context(ex))),
executor_(ex)
{
service_->construct(implementation_);
}
// ...
}
IO object 在构造时需要指定需要的 service,service 是 io_context 能获取到 OS 资源的具体实现(也就是上面图示中的第三步和第四步)。在这里,use service 展开为 asio::use_service<asio::detail::io_uring_socket_service<asio::ip::tcp> >。
service
template <typename Service>
inline Service& use_service(execution_context& e)
{
// Check that Service meets the necessary type requirements.
(void)static_cast<execution_context::service*>(static_cast<Service*>(0));
return e.service_registry_->template use_service<Service>();
}
use service 关联了 service 和 execution context 的关系:后者提供前者的注册。
template <typename Service>
Service& service_registry::use_service()
{
execution_context::service::key key;
init_key<Service>(key, 0);
factory_type factory = &service_registry::create<Service, execution_context>;
return *static_cast<Service*>(do_use_service(key, factory, &owner_));
}
template <typename Service, typename Owner>
execution_context::service* service_registry::create(void* owner)
{
return new Service(*static_cast<Owner*>(owner));
}
execution_context::service* service_registry::do_use_service(
const execution_context::service::key& key,
factory_type factory, void* owner)
{
asio::detail::mutex::scoped_lock lock(mutex_);
// First see if there is an existing service object with the given key.
execution_context::service* service = first_service_;
while (service)
{
if (keys_match(service->key_, key))
return service;
service = service->next_;
}
// Create a new service object. The service registry's mutex is not locked
// at this time to allow for nested calls into this function from the new
// service's constructor.
lock.unlock();
// 第一次生成的服务会走到这里
auto_service_ptr new_service = { factory(owner) };
new_service.ptr_->key_ = key;
lock.lock();
// Check that nobody else created another service object of the same type
// while the lock was released.
service = first_service_;
while (service)
{
if (keys_match(service->key_, key))
return service;
service = service->next_;
}
// Service was successfully initialised, pass ownership to registry.
new_service.ptr_->next_ = first_service_;
first_service_ = new_service.ptr_;
new_service.ptr_ = 0;
return first_service_;
}
服务注册的代码比较啰嗦,简单理解为生成 key-value 的形式,避免重复加入。也就是说,如果不存在 service 就构造并插入到 execution context 的 service 链表中,如果已存在那就直接返回。
回到具体的用例,这里会通过 factory 生成服务。因此会 new io_uring_socket_service(...):
// Constructor.
io_uring_socket_service(execution_context& context)
: execution_context_service_base<
io_uring_socket_service<Protocol>>(context),
io_uring_socket_service_base(context)
{
}
io_uring_socket_service_base::io_uring_socket_service_base(
execution_context& context)
: io_uring_service_(asio::use_service<io_uring_service>(context))
{
io_uring_service_.init_task();
}
void io_uring_service::init_task()
{
// 在这里插入了 task operation
scheduler_.init_task();
}
从 io_uring_socket_service,io_uring_socket_service_base 再到 io_uring_service,总算生成了 task operation。
TIPS: 另外有一个与本文关联不大的实现细节:scheduler 也是一种 service。详情请自行查看 io_context 的构造过程。
task run
再次回顾前面提到的 scheduler 流程:
- task operation 插入到 operation queue。
- 当 task operation 出队时,执行
task_->run(...)。
task_ 初始化同样出现在 init_task() 流程,只有一行:
task_ = get_task_(this->context());
但又不只是一行,这得回到 scheduler 的构造函数:
// Constructor. Specifies the number of concurrent threads that are likely to
// run the scheduler. If set to 1 certain optimisation are performed.
ASIO_DECL scheduler(asio::execution_context& ctx,
int concurrency_hint = 0, bool own_thread = true,
// 默认的情况
get_task_func_type get_task = &scheduler::get_default_task)
: get_task_(get_task) // ...
{ /*...*/ }
scheduler_task* scheduler::get_default_task(asio::execution_context& ctx)
{
#if defined(ASIO_HAS_IO_URING_AS_DEFAULT)
// 只是返回了一个 service
return &use_service<io_uring_service>(ctx);
#else // defined(ASIO_HAS_IO_URING_AS_DEFAULT)
return &use_service<reactor>(ctx);
#endif // defined(ASIO_HAS_IO_URING_AS_DEFAULT)
}
也就是说 task_->run() 应该理解为 io_uring_service->run():
class io_uring_service
: public execution_context_service_base<io_uring_service>,
public scheduler_task
{
// Wait on io_uring once until interrupted or events are ready to be
// dispatched.
ASIO_DECL void run(long usec, op_queue<operation>& ops);
// ...
};
void io_uring_service::run(long usec, op_queue<operation>& ops)
{
__kernel_timespec ts;
int local_ops = 0;
if (usec > 0)
{
ts.tv_sec = usec / 1000000;
ts.tv_nsec = (usec % 1000000) * 1000;
mutex::scoped_lock lock(mutex_);
if (::io_uring_sqe* sqe = get_sqe())
{
++local_ops;
::io_uring_prep_timeout(sqe, &ts, 0, 0);
::io_uring_sqe_set_data(sqe, &ts);
submit_sqes();
}
}
::io_uring_cqe* cqe = 0;
int result = (usec == 0)
? ::io_uring_peek_cqe(&ring_, &cqe)
: ::io_uring_wait_cqe(&ring_, &cqe);
if (local_ops > 0)
{
if (result != 0 || ::io_uring_cqe_get_data(cqe) != &ts)
{
mutex::scoped_lock lock(mutex_);
if (::io_uring_sqe* sqe = get_sqe())
{
++local_ops;
::io_uring_prep_timeout_remove(sqe, reinterpret_cast<__u64>(&ts), 0);
::io_uring_sqe_set_data(sqe, &ts);
submit_sqes();
}
}
}
bool check_timers = false;
int count = 0;
while (result == 0 || local_ops > 0)
{
if (result == 0)
{
if (void* ptr = ::io_uring_cqe_get_data(cqe))
{
if (ptr == this)
{
// The io_uring service was interrupted.
}
else if (ptr == &timer_queues_)
{
check_timers = true;
}
else if (ptr == &timeout_)
{
check_timers = true;
timeout_.tv_sec = 0;
timeout_.tv_nsec = 0;
}
else if (ptr == &ts)
{
--local_ops;
}
else
{
io_queue* io_q = static_cast<io_queue*>(ptr);
io_q->set_result(cqe->res);
// 默认情况,获得完成的 IO operation,插入到 operation queue 中
ops.push(io_q);
}
}
::io_uring_cqe_seen(&ring_, cqe);
++count;
}
result = (count < complete_batch_size || local_ops > 0)
? ::io_uring_peek_cqe(&ring_, &cqe) : -EAGAIN;
}
decrement(outstanding_work_, count);
if (check_timers)
{
mutex::scoped_lock lock(mutex_);
timer_queues_.get_ready_timers(ops);
if (timeout_.tv_sec == 0 && timeout_.tv_nsec == 0)
{
timeout_ = get_timeout();
if (::io_uring_sqe* sqe = get_sqe())
{
::io_uring_prep_timeout(sqe, &timeout_, 0, 0);
::io_uring_sqe_set_data(sqe, &timeout_);
push_submit_sqes_op(ops);
}
}
}
}
如果了解过 io uring,就能明白这就是 submit and wait 的过程。这是一个可能阻塞的过程,但是在 io_context 多线程环境下,只可能有一个线程持有该 task,其它线程就只会消费其它已完成任务,或者因无其它任务而陷入 wait,等待当前 io uring 执行线程的唤醒。
io uring 收割到的 operation 可以存放到当前线程私有的 operation queue 中,具体由传参决定。
task cleanup
在 scheduler 的 do_run_one 流程还存在收尾工作:
task_cleanup on_exit = { this, &lock, &this_thread };
struct scheduler::task_cleanup
{
~task_cleanup()
{
if (this_thread_->private_outstanding_work > 0)
{
asio::detail::increment(
scheduler_->outstanding_work_,
this_thread_->private_outstanding_work);
}
this_thread_->private_outstanding_work = 0;
// Enqueue the completed operations and reinsert the task at the end of
// the operation queue.
lock_->lock();
scheduler_->task_interrupted_ = true;
scheduler_->op_queue_.push(this_thread_->private_op_queue);
scheduler_->op_queue_.push(&scheduler_->task_operation_);
}
scheduler* scheduler_;
mutex::scoped_lock* lock_;
thread_info* this_thread_;
};
基本来说,就是前呼后应:
- 收割到的 operation 切回线程共享 operation queue。
- 继续埋下一个 task operation,从而持续执行
run()。
上半部总结
- io context 拆离了两部分,一部分是 scheduler,另一部分是 service。
- service 用以实现 OS 资源的交互(不管是 epoll 还是 io uring,文件 IO 还是网络 IO)。
- io object 发起请求时,就向 io context 申请使用对应的 service 资源。
- io context 会通过基类的 service registry 管理 service 资源。
- service 资源的创建会生成 task operation,并插入到对应 scheduler 的 operation queue 中。
- operation queue 的消费过程中遇到 task operation 时,就会触发 service 的等待收割过程。
- 收割完成后,operation queue 会填充收割到的 operation 供所有线程消费,并通过收尾操作再次埋下 task operation,如此往复。