前言
本文介绍简化的 C++ 内存模型,涉及到 memory order,modification order 和 release sequence 等概念。虽然内容对于 C++ 标准有所删减,但我希望相比 C++ 标准和 cppreference 都更易于理解。
注意文内的括号、虚线和加粗部分可能表明这是一个专用名词。
问题
先给出一个问题:如果有 2 个线程并发执行以下代码,结果是否正确(断言 assert 是否为真)?
int val;
bool flag {false};
void writer() {
val = 1;
flag = true;
}
void reader() {
while(!flag);
assert(val == 1);
}
上面的代码描述:
writer线程写完val数据后设置flag表示操作已完成,reader等待flag设置后读取val数据。
虽然过程很直观,但是断言不一定为真:因为这些非原子的读写操作不满足强制的内存访问顺序。
语言标准是基于抽象机器去描述的,因此这里不必(也不应该)从具体的体系结构去分析原因。
而所需要的强制内存访问顺序在 C++ 中需要 2 种关系去确认:
- happens-before(先行关系)
- synchronizes-with(同步关系)
先行关系
先行关系的概念用于确定操作之间的可见性(visible side effect)。如果说操作 A 先行于操作 B,那么 A 对 B 可见。
这里的操作就是执行的语句,包括表达式求值和副作用。
而可见性能约束对非原子变量执行读操作时能读到的范围(reads-from)。
那么怎样才能得到先行关系?单线程下如果满足先序关系(sequenced-before)即可得到一种先行关系。而先序关系指的是程序顺序(program order)的前后顺序。比如有如下代码:
int x = 5; // L1
int y = 7; // L2
在程序顺序上,第一行代码(L1)早出现在第二行代码(L2)的前面,因此 L1 先行于 L2。
但是此时只有先序关系并不能保证线程安全,因为先序关系只适用于单个线程,只提供了某种「偏序」。回到问题提到的代码里:
void writer() {
val = 1; // xL1
flag = true; // xL2
}
void reader() {
while(!flag); // yL1
assert(val == 1); // yL2
}
按照先行关系,显然 xL1 < xL2,且 yL1 < yL2。但是 xL2 和 yL1 的关系并没有确认,换句话说就是根本不能假定 y 能看到 x 操作产生的结果。
怎样才能描述线程安全?可惜 C++ 标准中没有线程安全的定义。但可简单认为至少需保证免数据竞争(data-race-free)。
简单来说,以下条件全部符合则是 data race:
- 有任意 2 个操作。
- 是对同一地址/对象的操作。
- 至少有一个写操作。
- 操作不在同一线程。
- 任意一边为非 atomic 操作。
- 双边不具有 happens-before 关系。
反过来,只需破坏以上任一条件就是 data-race-free。你可以看到最后一个条件就是先行关系。
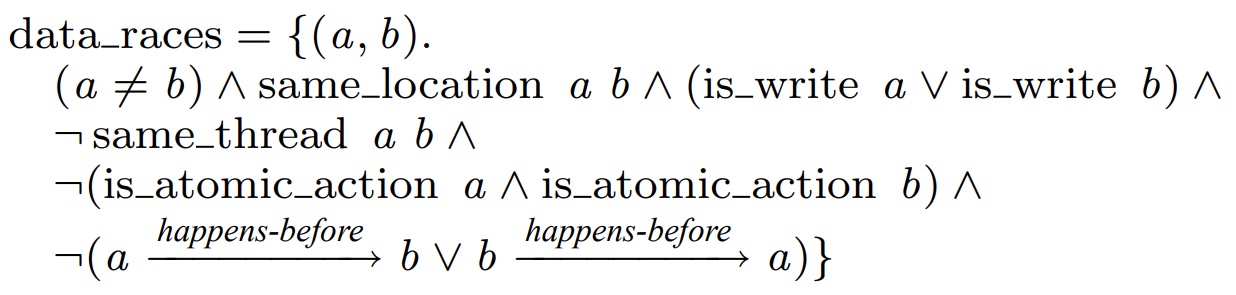
同步关系
为了解决线程间的先行关系,还需引入新的概念:同步关系。同步关系通过可传递性,从而构成线程间的先行关系(inter-thread happens-before)。
同步关系相比先行关系,性质比较特殊:
- 只作用于同一个原子变量的读写操作。
- 需要加上合适的标记,才允许读写操作之间产生同步关系。
- 不同的标记可提供不同强度的同步关系。
而上面提到的标记即是内存序(memory order),用于指定如何进行内存访问。
一般来说,内存序有三种标记提供给开发者使用:
relaxedacq-relseq-cst
这种内存访问分类也是按照同步的强弱程度划分的:
- 不需要同步:relaxed 宽松模型。
- 需要同步:acquire-release 获取释放模型。
- 需要同步且要求全局顺序一致:sequential consistency 顺序一致模型。
如果希望获取同步,则至少需要使用获取释放模型,且读操作获取(acquire)到写操作释放(release)的对应值,才能构成读操作与写操作之间的同步关系。
内存序需要完整标记,如果有一个 writer thread 的原子变量的写操作施放
seq_cst而对应 reader thread 同一原子变量的读操作却只施放relaxed,那么在语言层面上并不提供同步和全局顺序一致性的保证。
内存序中还存在一种 consume 标记,但是 redhat 的某篇分享中提到 consume 实现上可能存在歧义(TL;DR: Don’t use
memory_order_consume)。虽然 C++20 对此已经有所进展,但是本文仍不做讨论。
全局顺序一致指的是所有的线程能同一个顺序地观测到所有的改动,即只要某个线程观测到某个操作的结果,那么所有线程也都能观察到。大白话就是全局只有一种顺序。
现在把问题中的代码修改为 atomic 类型,来提供同步关系:
int val;
std::atomic<bool> flag {false};
void writer() {
val = 1; // xL1
flag.store(true, std::memory_order_release); // xL2
}
void reader() {
while(!flag.load(std::memory_order_acquire)); // yL1
assert(val == 1); // yL2
}
此时使用了获取释放模型来让 xL2 同步于 yL1,只要 yL1 读到 xL2 提供的值(因为 flag 是 atomic,原子变量本身是可以看到自身的改动,更多说明见改动序列),那么就产生同步关系构成线程间的先行关系,即 xL1 < xL2 < yL1 < yL2。
简单来说,通过 synchronizes-with 和 happens-before 的可传递性,即可保证线程安全。
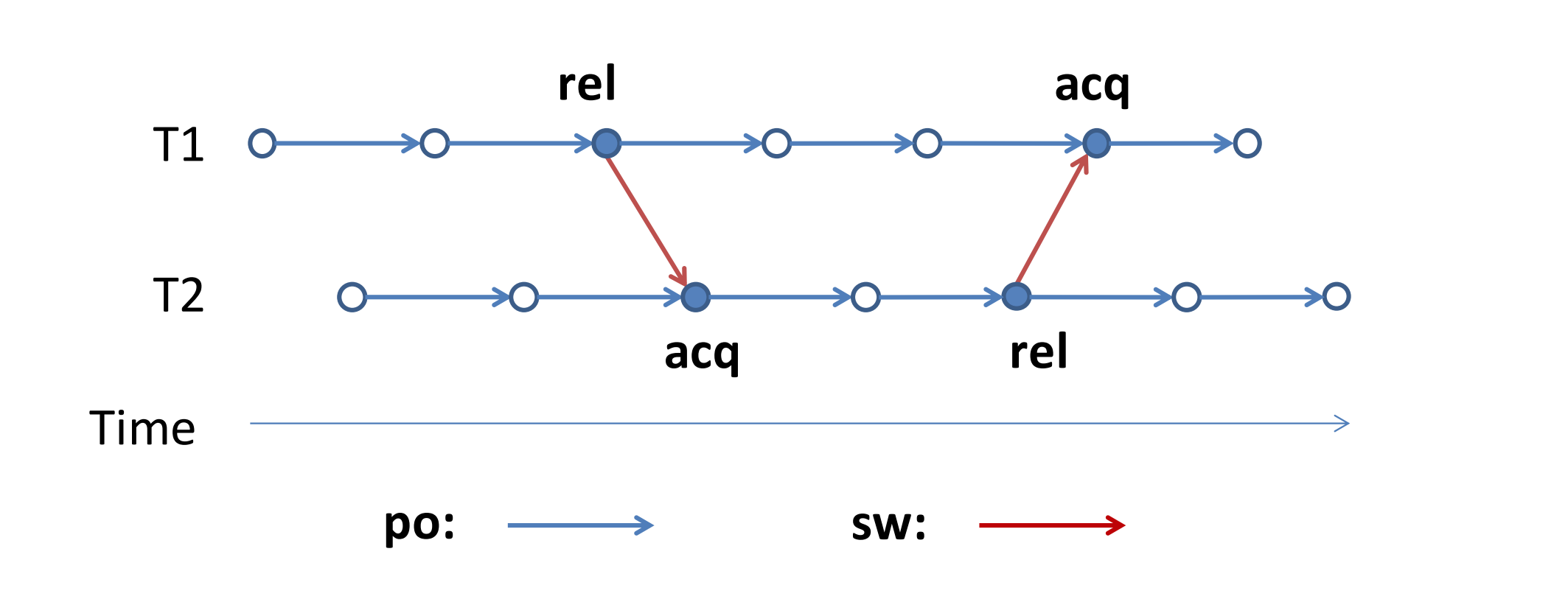
*po = program order
*sw = synchronizes-with
为什么不把同步关系等同视为线程间先行关系?这说的好像同一回事啊——那当然是概念上有简化,比如 inter-thread happens-before 还可以通过 dependency-ordered before 来构成。这种简化的关系在 C++20 被定义为 simply happens-before,其他细节略。
先行关系满足两者之一即可构成,一是 sequenced-before,二是 inter-thread happens-before。
补充一点内存序与可见性的联系。这章节总结得出内存序通过同步关系构成了先行关系,而前面提到先行关系可以提供可见性,这是怎样关联的?其实有 2 条规则:
- Every write action that happens-before the read with no intervening write is a visible side effect.
- Non-atomic actions must read-from visible side effect.
关于 seq-cst 标记:一个必要使用该标记的场合是 IRIW(独立读-独立写)。
改动序列
前面提到,原子变量本身可以看到自身的改动,这涉及到改动序列(modification order)。
可以认为,每个原子变量都维护一个全局(所有线程可见)的改动序列,其序列中的每一个值由写操作提供,而读操作则读入改动序列中的某一个值。
严格来说这里又得引入连贯性(coherence)的概念,比如读写连贯(read-write coherence)、写写连贯(write-write coherence)等等。但这里简化一点,知道感性的规则即可:
- 序列中的每个值由写操作提供。
- 序列中的第一个值就是原子变量初始化时提供的值。
- 如果某线程的读操作得到某个值 v,那么这个线程此后读的结果要么是 v,要么是序列中比 v 更靠后(更新)的值,这个线程后续的写操作提供的值也会 append 到序列的后方。
- 如果某线程进行写操作后接着读操作,那么该线程读操作得到的值要么是刚才最后一次写操作的结果 v,要么是序列中比 v 更新的值。
因此,你可以得知 atomic::load() 函数就是获取改动序列某个下标的值:这个序列在所有线程中都长一样且同步更新,但是每个线程私有的访问下标却不一样,但不管怎样,每个线程的下标都是单调递增地变动。也就是说原子读操作可能读到「旧值」,但肯定不是「脏值」。
关于「新值」和「旧值」:
释放序列
当一个原子变量执行了 release 操作(记为 A),此后任意线程对该原子变量的 RMW 操作所形成的最长子序列就称为——以 A 为首的释放序列(release sequence)。
这个概念有什么用?其实是用于补全释放获取模型的完整性,使得代码符合开发者直觉。在释放获取模型中,直接的理解就是:标记 acquire 的读操作能看到 release 前的所有操作(只要能读到对应的值)。但加上释放序列的概念后还可以如此补充:标记 acquire 的读操作能看到释放序列前的所有操作(只要能读到对应的值)。
可以看如下的生产者 - 消费者例子,如果缺少释放序列,那么这段代码可能是错误的:
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
#include <mutex>
std::vector<int> queue_data;
std::atomic<int> count;
std::mutex m;
void process(int i) {
std::lock_guard<std::mutex> lock(m);
std::cout << "id " << std::this_thread::get_id() << ": " << i << std::endl;
}
void populate_queue() {
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0;i<number_of_items;++i) {
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release); //#1 The initial store
}
void consume_queue_items() {
while (true) {
int item_index;
if ((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0) { //#2 RMW
std::this_thread::sleep_for(std::chrono::milliseconds(500)); //#3
continue;
}
process(queue_data[item_index - 1]); //#4 Reading queue_data is safe
}
}
int main() {
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
}
这段代码中有一个生产者 a,两个消费者 b 和 c。a 处理好私有数据后通过 release 操作发布 queue_data,后续被 b 和 c 不断消费。
这段代码是符合开发者直觉的,但是如果没有释放序列的话,虽然有以下的同步关系:
a#1<b#2a#1<c#2
但是注意如果线程是按照这样的顺序执行:
a生产queue_data,通过release发布出去。b消费了一个item_index。c消费了一个item_index。
这里由于步骤 2 的操作是 RMW,改动了 atomic 类型 count 的值,那么步骤 3 的操作并没有与步骤 1 构成同步关系,此时 c 接着读入 queue_data 就是一个未定义行为(因为此时 count 已经不是由 a#1 通过 release 标记写入的值,c#2 中 acquire 标记已经无济于事,所以 queue_data 也未发布给 c)。
而如果引入释放序列来修正获取释放模型,那么 c#2 读到的是以 a#1 为首的释放序列当中的任意值,因此仍然满足 acquire-release。
RMW 操作即使是 relaxed 标记,也能形成释放序列。cppreference 对此有一个示例(godbolt 备份)。
操作 A 是 release 操作而不只是写操作,也就是要求写操作时施放 release 标记才行。
「读到对应的值」指的不仅是 release 操作写入的值,还包括以它为首的整个释放序列中的任意值。
如果该例子中只有一个消费者,那无需释放序列也能保证正确性。
关联文章
如果并行编程很难,那我能做点什么?
使用 GenMC 检验 C/C++ 内存模型
References
C++ Concurrency in Action, 2nd
std::memory_order – cppreference
c++ - What does “release sequence” mean? – Stack Overflow
Release-acquire ordering: must load the value that was stored – cppreference
Concurrency: Algorithms and Theories – Hongjin Liang’s homepage
原文发布于 2023/02/02,全文重写于 2023/11/20。