CSAPP 第 7 章就是用来讲解链接过程的,不算深入但了解全面,适合整理总结,因此做一遍笔记。
什么是链接
如果了解目标文件的概念,那么链接过程就是从编译过程拿到的可重定位目标文件中生成出可执行目标文件。
不了解也没关系,后面会有解释。
为什么需要链接
链接使得分离编译成为可能。如果平时写的是小项目,那你可认为是没有必要,杀鸡焉用牛刀;但是大型项目中,分离编译可以大量提高编译效率,充分利用并行性能。另外,模块化在现实世界中是客观存在的。
为什么需要了解链接
- 避免踩坑,合格的开发者必然会经历过链接问题。
- 它会影响性能(轻微)和内存开销,你需要斟酌什么情况下使用。
- 它有一些特殊的用途,比如符号介入,你可能会用到。
- 第三方提供的可能是一个库,而不是代码,你得至少学会用……
什么时候发生链接
如果是按照整个文件生成到执行的过程来看的话,一般情况是这样的:
- 编译阶段
- 预处理
- 编译
- 汇编
- 链接阶段←here
- 装载阶段
而实际上,链接本身是可以位于不同的时机:
- 编译时
- 装载时
- 运行时
第一种是静态库所用到的时机,也是上面提到的“一般情况”,而后两种是动态库用到的。
静态链接
静态链接过程中,linker 会把可重定向目标文件(作为输入)组合在一起,形成可执行文件(作为输出)。在这些可重定向目标文件中,包含多个 section,比如代码(或者是指令)一个 section,未初始化变量一个 section 等。在 Linux 中,这些工作由静态链接器 ld 完成。
linker 的工作分为 2 个部分:
- 符号解析。
- 重定位。
符号解析
什么是符号?你可认为是一个函数,一个全局变量,或者是一个 static 变量。在后面的 ELF 文件解析中,有更加具体的“符号”定义。
目标文件既定义符号,也引用符号。而符号解析就是把每一个符号的引用,关联到对应的、唯一的符号的定义。
CSAPP 里面的概念其实都简化过。对于符号,你可以参考我后面写的文章 (ELF 符号:复杂又麻烦的技术细节)。
重定位
编译器(和汇编器)生成 text section 和 data section,在编译器眼里,它们是开始于地址 0 的。而链接器则是把符号的定义,各自关联到某一个内存的地址。此时需要把符号的引用都做出修正,以正确指向对应的内存地址。
稍后会看到链接器如何利用汇编器生成的可重定位条目,来完成重定位工作。
目标文件
目标文件有三种类型:
- 可重定位目标文件。
- 共享目标文件(一种特殊的可重定位目标文件)。
- 可执行目标文件。
编译过程负责的工作就是生成可重定位目标文件(含共享目标文件),链接过程负责的工作就是生成可执行目标文件。
我们说的目标文件(object file),就是一个以文件形式,存储在磁盘的目标模块。而目标模块(object module),就是一串字节。当然,字节不是随意摆放的,我们有一定的规范来描述字节的布局。在 Linux 中遵循这种规范实现的目标文件,我们称之为 ELF (Executable and Linkable Format)。
ELF 布局
ELF 可重定位目标文件的布局如下:
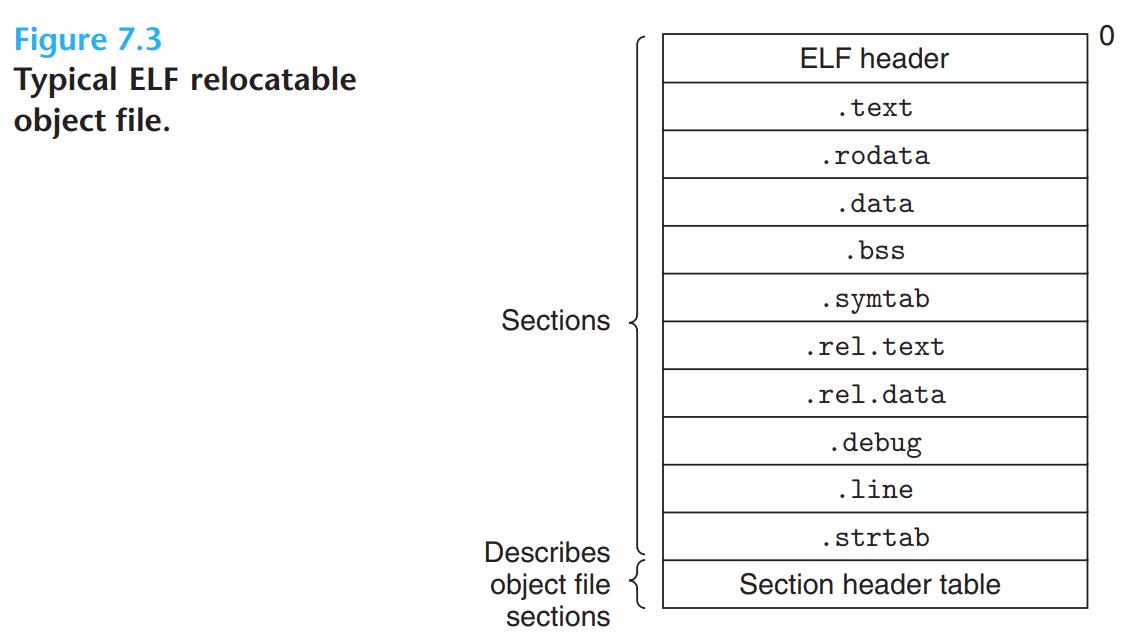
ELF 可执行目标文件的布局如下:
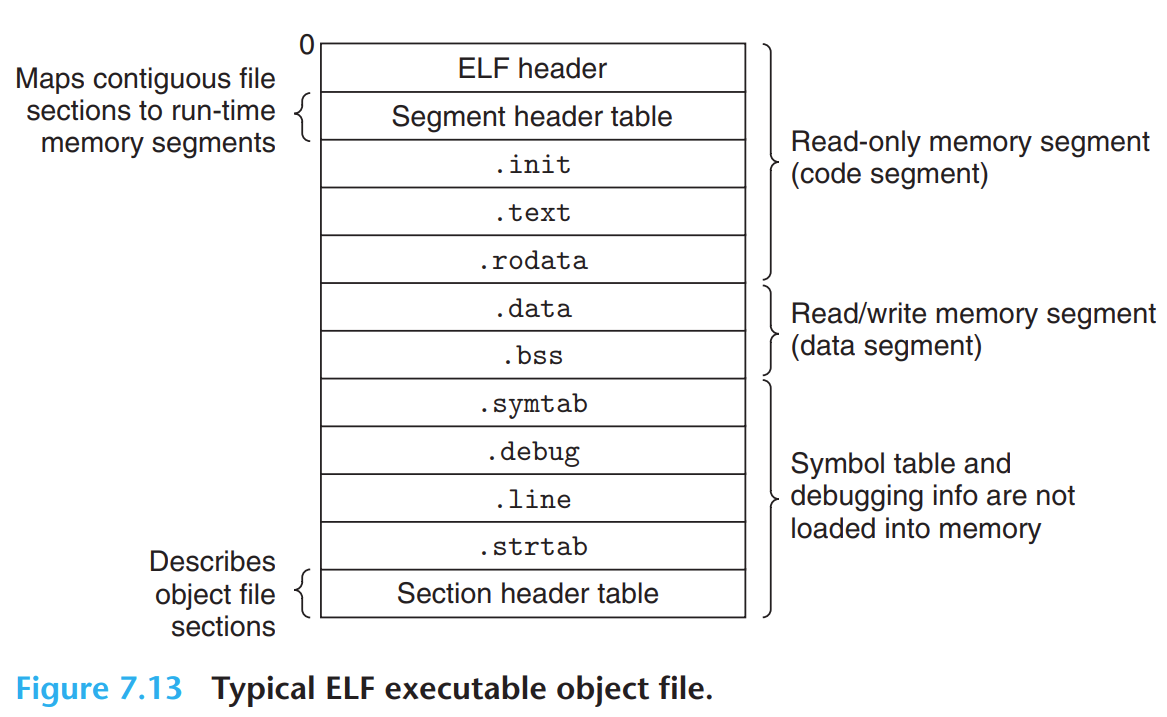
它们的共性就是自低到高位如下分布(链接器视角):
- ELF header。
- 若干 section。
- section header table。
ELF header
可以通过 readelf -h 查阅 ELF header 的内容。
任选一个 ELF 文件查阅如下所示:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x10a0
Start of program headers: 64 (bytes into file)
Start of section headers: 55560 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 36
Section header string table index: 35
可以看到,ELF 开头是 64 字节大小(size of this header),其实这个大小是固定的。
字面意思比较好理解的就先不说,这里额外了解一下 entry point address。Entry point address 就是程序启动时首先用到的地址,对于上述 ELF 文件进行 objdump,可以看到地址 0x10a0 反汇编代码为:
00000000000010a0 <_start>:
10a0: f3 0f 1e fa endbr64
10a4: 31 ed xor %ebp,%ebp
10a6: 49 89 d1 mov %rdx,%r9
10a9: 5e pop %rsi
10aa: 48 89 e2 mov %rsp,%rdx
10ad: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
10b1: 50 push %rax
10b2: 54 push %rsp
10b3: 4c 8d 05 e6 01 00 00 lea 0x1e6(%rip),%r8 # 12a0 <__libc_csu_fini>
10ba: 48 8d 0d 6f 01 00 00 lea 0x16f(%rip),%rcx # 1230 <__libc_csu_init>
10c1: 48 8d 3d c1 00 00 00 lea 0xc1(%rip),%rdi # 1189 <main>
10c8: ff 15 12 2f 00 00 callq *0x2f12(%rip) # 3fe0 <__libc_start_main@GLIBC_2.2.5>
10ce: f4 hlt
10cf: 90 nop
__libc_start_main 很显然跟启动流程有关,详见后面参考。
其实 ELF header 有许多细节,但是本文只涉及 CSAPP 讲述的内容,后续可能单独出一篇文章来说说 ELF header。
Section header table
可以通过 readelf -S 读取 section header table(section headers),简称为 SHT。从前面的 ELF header 信息可以看到,ELF 头部是记录着 start of section headers,因此找到它是很轻松的事情。而 SHT 的作用就是用于定位到文件中所有的 section,它本身是一个数组,至少它提供了各个 section 的偏移和大小等信息。
各种 section
从前面的 readelf -S 可以看到不少常见的 section 名字:
.text.data.bss.symtab.rel.strtab- …很多很多。
每一种 section 具有类型、地址和偏移量的属性,而 section 间的顺序并没有强制要求。
可以通过 Linker Script 来定制 section,感兴趣也可以看下我的笔记。
ELF 符号表
刚才的.symtab 就是名副其实的符号表,用于存放当前目标模块所引用和定义的符号。
关于符号,就是前面提到的:函数,全局变量和 static 变量。
更细分地,linker 根据引用定义关系把符号分为两种全局符号和一种局部符号:
- 被当前目标模块定义,被其它目标模块引用的全局符号。
- 被当前目标模块引用,被其它目标模块定义的全局符号。
- 只被当前模块定义和引用的局部符号。
注意这里的局部符号并不是指局部变量,而是指 static 关键字作用的函数和全局变量。
这个命名有点绕,用
C来说明:一般来说static变量是内部链接,而局部变量是无链接(no linkage)。
ELF 中通过 binding 字段以区分局部符号还是全局符号,通过 type 字段以区分函数还是变量(详见 Elf64_Symbol)。
有三种伪 section(special pseudosection)在 SHT 中没有条目:
- ABS:存放不需要重定位的符号。
- UNDEF:存放该目标模块中被引用但未有定义(可能在别的模块)的符号。
- COMMON:现在没啥用了,见下方符号解析。
一些小细节
- 由于字符串不定长的原因,符号表所用到的字符串会额外存放于.strtab,便于管理。
- 符号表由汇编器构造完成,即.s 文件的作用之一就是构造符号表。
符号解析
符号解析分为局部符号解析和全局符号解析:
- 局部符号解析就是对 static local variables 处理,确保它有唯一的名字即可。
- 而全局符号解析,每当遇到一个不在本目标模块内定义的符号,则认为是被定义在其它的目标模块中,因此编译器需要在符号表中生成一个条目,交给后续的链接器处理。
符号解析需要处理不同模块间相同名字的问题,linker 的做法就是把符号分为强符号和弱符号。
注意,强弱符号是给全局符号用的,而局部符号本身是对其它目标模块不可见,因此不需要讨论。
规则如下:
- 强符号不允许多个名字存在。
- 同时存在重复名字的强符号和弱符号时,选用强符号。
- 同时存在重复名字的弱符号时,任意选择其一。
强弱符号的分配规则如下:
- 全局符号,要么是强符号,要么是弱符号。
- 函数及初始化的全局变量为强符号。
- 未初始化的全局变量为弱符号。
这里涉及到 COMMON 段的问题:当编译器遇到一个为弱符号的全局符号,因为它不知道这个值是否被其它目标模块所定义,也不知道链接器会选用哪一个符号,因此它把这个符号放到 COMMON 段。
然而,这个在勘误中指出,gcc 已经不这么干了:p. 680, Section 7.6.1. Recent versions of gcc such as gcc10 now default to -fno-common, so programs with multiply-defined weak symbols will now elicit a linker error. Posted 2/14/2022. Michaël Cadilhac
小细节
- 对于全局变量,如果显式地初始化为 0,那也算是强符号。
- 对于 inline function,归类为弱符号,也恰好符合 choose any of 的特性(规则三)。
- 对于可执行目标文件,全局变量是最终(直到链接时再)放到.data 或者.bss,但在此前的过程中可放在 COMMON(注意上方勘误)。
重定位
上面的符号解析把引用和定义正确关联在一起。
接下来的重定位工作就是合并目标模块,并且为符号赋上运行时地址。重定位分为 2 个阶段:
- 对 section 和符号定义进行重定位。
- 对 section 内的符号引用进行重定位。
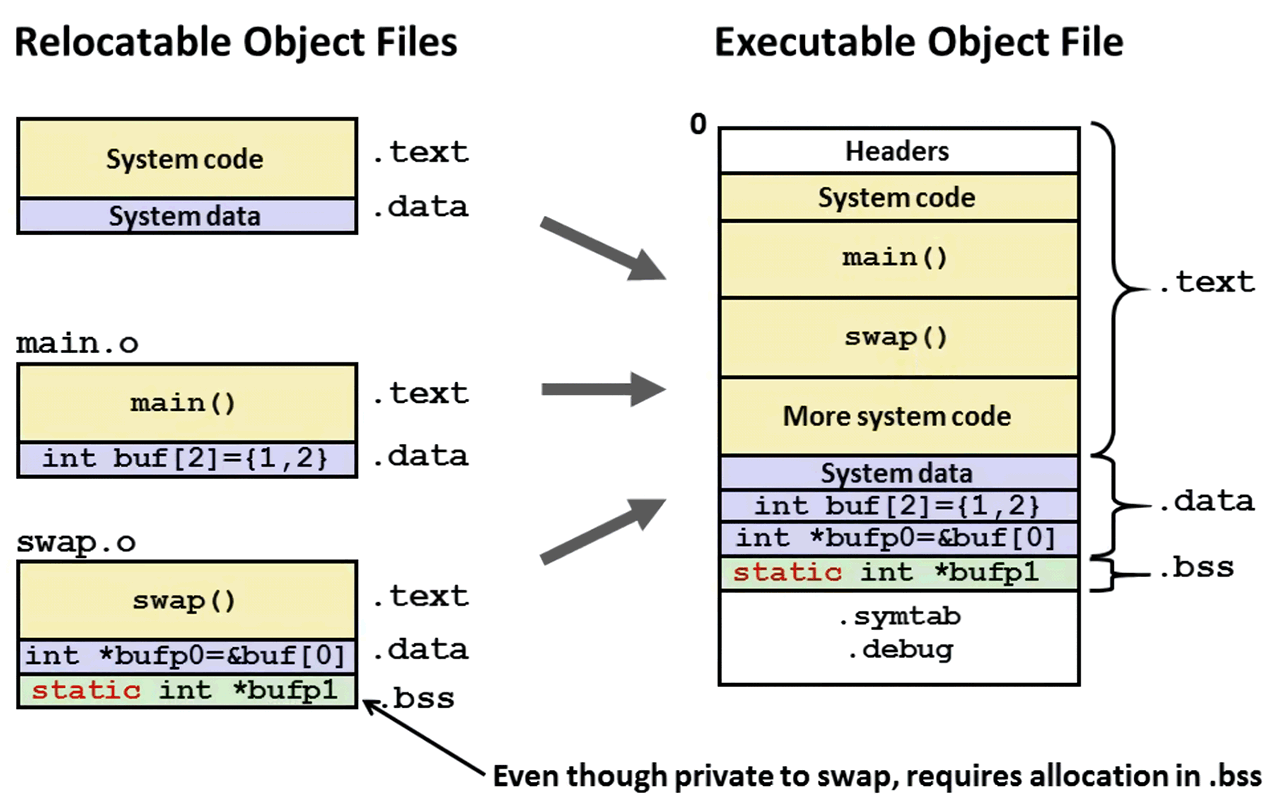
第一个阶段很好理解,就是把符号解析阶段多个重定位目标文件的相同 section 的合并(如下图所示),以及为符号的定义分配运行时地址(如下图,main() 和 swap() 等定义有了具体的地址)。
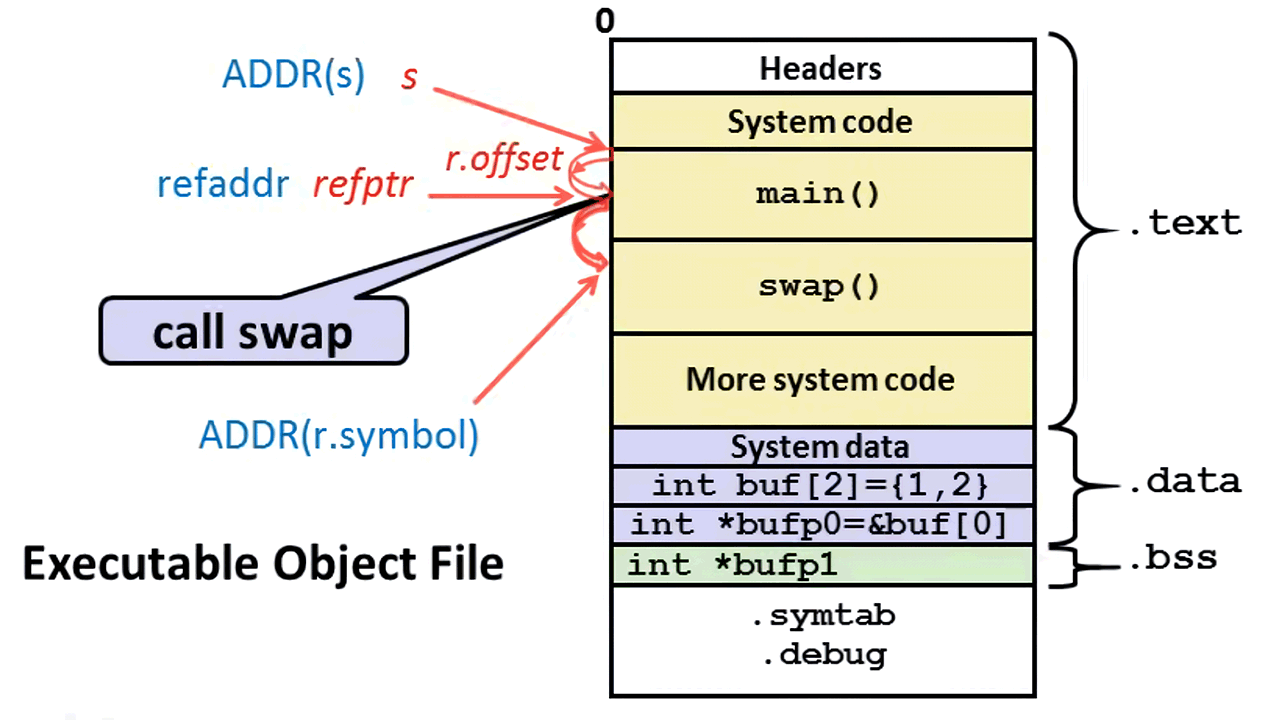
第二阶段相对复杂点,需要处理的是 section 内的符号引用,如 main 里调用 swap,则是一个 call <address> 的过程,此时符号引用也需要重定位。
在开始前,需要了解重定位用到的 section:.rel。.rel 是重定位信息,如 .rel.text 是 .text 的重定位信息,.rel.data 是 .data 的重定位信息。这些重定位用到的信息,称之为重定位条目,它们是由汇编器认为无法识别的符号引用所生成的。在数据结构层面,条目包含以下字段:
offset:当前 section 开始的偏移量,用于标记某个需要重定位的地方。symbol:符号信息,表示某个函数或变量。type:重定位类型,分为 PC 相对地址重定位类型(PC32)和绝对地址重定位类型(32)。addend:显式加数,用于修正当前符号与下一条指令地址的差值。
通过这些字段,可以实现下面的重定位算法:

以 PC32 相对寻址作为重定位算法的说明:
s表示文件内指向 section 的指针。r.offset表示需要重定位的符号对于这个 section 的文件内偏移量。refptr表示文件内需要重定位的符号的指针。ADDR(s)表示链接器赋予的s的运行时地址。refaddr表示需要重定位的指令的运行时地址。ADDR(r.symbol)表示链接器赋予的符号的运行时地址。r.addend表示显式加数,用于修正当前符号与下一条指令地址的差值。*refptr表示真正的重定位操作。
注:回到上面 ELF 的布局图,我们可以看到,.rel 在最终的可执行目标模块是没有的,因为它已完成了重定位而不再需要。
动态库
静态库有自己的问题:
- 难以维护更新。
- 容易重复占用内存资源。
动态库能克服这些问题,因为他允许加载时和运行时链接,并且提供 COW 机制。
动态库的实现使用了 PIC 机制,后面介绍这一特殊的机制。
PIC
PIC 是生成位置无关代码(position-independent code)。它允许共享库被加载到任意内存地址,这样做的目的是为了避免固定地址而导致的内存碎片化。
它涉及到位置的就是变量和函数,下面看看如何处理。
对于变量,我们根据代码段和数据段的距离是已知的,引入了 GOT(Global Offset Table),它位于.data 的头部。当处于装载阶段时,动态链接器修改 GOT 的每一个条目,使得能找到对应变量的绝对地址(真实的符号地址)。也就是说,当我们的程序需要得到共享库的变量时,只需间接访问 GOT[] 数组即可。
如果函数也照着这么干(间接访问 GOT)是不是可以呢?我觉得可以。但考虑到函数符号的数量问题,对于函数,使用的是一种 lazy binding 的技巧。因此除了 GOT,还引入了 PLT(Procedure Linkage Table),后者位于代码段,它的作用是把需要重定位的函数延迟到首次调用才会写到 GOT。
这个过程是怎么做到的,很有意思。
首先需要了解一些特殊的条目:
GOT[0], GOT[1]: 动态链接器解析参数时用到的临时条目。GOT[2]: 动态链接器的地址。PLT[1]: 用于跳转到动态链接器。- 用户所用到的下表起始分别是
GOT[3]和PLT[2]。 - 每个
GOT条目初始状态下指向原PLT的下一条指令,即访问PLT[i]时,PLT[i]指向GOT[j],此时GOT[j]会指向PLT[i]+1。
好,接下来就看看像跳舞一样的控制流是怎样完成 lazy binding 的:
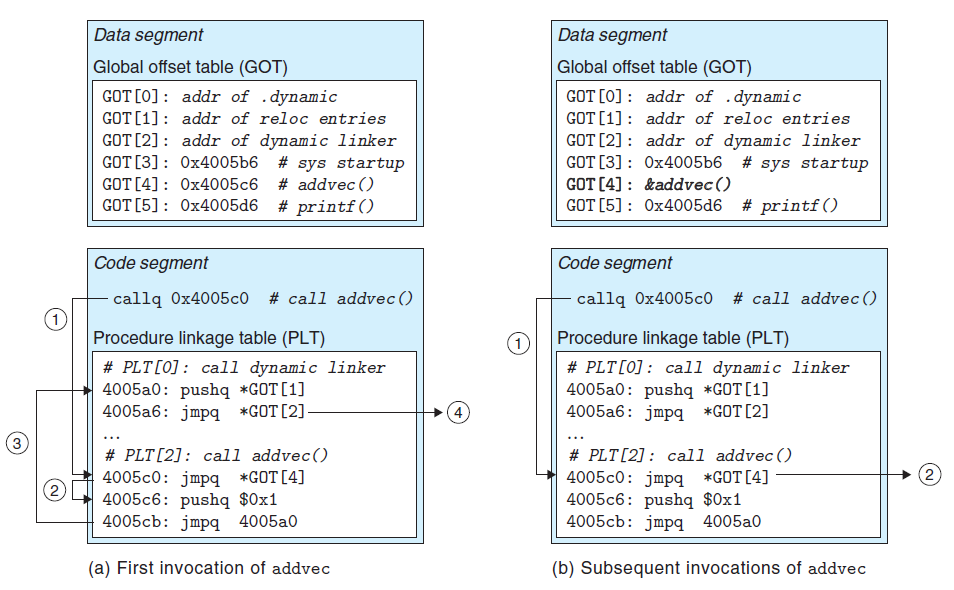
上述图示是一个调用 addvec() 的例子,由于使用了 PLT,因此是间接访问了 PLT[2],经过一系列操作,最终才能得到一个具体的 addvec() 地址:
- 访问
PLT[2],其指向GOT[4]。 - 根据上述规则 5,
GOT[4]跳转到PLT[2]的第二行,PLT位于代码段,这里会执行4005c6和4005cb。压栈,$0x1为addvec的 ID,压栈后跳转到4005a0。 4005a0为PLT[0],压栈GOT[1],根据上述规则 1,GOT[1]是提供给动态链接器的参数;继续执行4005a6,跳转到GOT[2]提供的地址,根据规则 3,会跳转到动态链接器,而动态链接器就是利用上面压栈的两个参数来完成重定位,修改GOT[4]为真正的符号地址。修改后,动态链接器只需把控制流跳到PLT[2],就能获取真正的写好了符号地址的GOT[4],即&addvec。
第一次肯定有点绕(相当于做了一个 cache 操作),但是以后的操作就简单了:
- 访问 PTL。
- 访问 GOT。
下一篇文章:ELF 符号:复杂又麻烦的技术细节
References
Computer Systems: A Programmer’s Perspective, 3/E (CS:APP3e)
Errata for CS:APP3e and its Instructors Manual (cmu.edu)
elf(5) - Linux manual page (man7.org)
Start analysis at any position in elf is Entry Point? - Reverse Engineering Stack Exchange
Inline Functions in C and C++ (etherealwake.com)
bilibili/BV19X4y1P7zW