由于要做年轻人的第一次技术分享,因此我挑了个 epoll 实现原理作为课题,主要是先做下快速介绍,然后直接杠源码(长篇大论没人听警告)
PS. 不想看一堆代码可直接快速浏览文中的流程图,点我直达
涉及到的内容
epoll是什么,大概怎么用- 了解
epoll实现前需要知道的工具 - 三大实现流程,及其内部数据结构
- 实际需要考虑的问题及总结
epoll 是什么
epoll 全称 eventpoll,是 linux 内核实现 IO 多路复用的一种实现。
IO 多路复用的意思是在一个操作里同时监听多个输入输出源,在其中一个或多个输入输出源可用的时候返回,然后对其的进行读写操作。
因此,epoll 的行为就是只用一个线程,监听多个 fd(文件描述符),阻塞直到任意一个 fd 可以进行 IO 操作(视 IO 操作为一个 event),然后返回,交给我们处理
怎么用
总共只有三个操作
- 创建 epoll 实例
- 选择(修改)epoll 需要监听的事件(fd+epoll_event)
- epoll 阻塞等待,直到有事件或超时才返回
具体到 API 层面如下所示
创建 epoll 实例
// epoll_create, epoll_create1 - open an epoll file descriptor
int epoll_create(int size);
int epoll_create1(int flags);
对 epoll 关注的事件进行增删改
// epoll_ctl - control interface for an epoll file descriptor
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd: 刚才创建的epoll实例返回的fd
// op: 操作,有 EPOLL_CTL_ADD EPOLL_CTL_MOD EPOLL_CTL_DEL可选
// fd: epoll监听的fd
// event:关注的事件,如果是EPOLL_CTL_DEL则忽略
// The event argument describes the object linked to the file descriptor fd.
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
events比较多可关注的事件,最常见的有三个
EPOLLIN
The associated file is available for read(2) operations.
EPOLLOUT
The associated file is available for write(2) operations.
EPOLLERR
Error condition happened on the associated file descriptor. This event is also reported for the write
end of a pipe when the read end has been closed. epoll_wait(2) will always report for this event; it
is not necessary to set it in events.
等待 IO 操作
// epoll_wait, epoll_pwait - wait for an I/O event on an epoll file descriptor
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
timeout<0则阻塞直到有事件到来
timeout==0则非阻塞立刻返回
timeout>0为阻塞超时阈值(ms为单位)
前置工具快速上手
这里会介绍两个最常用到的数据结构和一个文件系统的机制,后面我们会逐一深入
list_head
list_head 是内核链表,在 linux 中大量用到,作为一种侵入式容器,较为反直观,通常一个链表是这样实现
template <typename T>
class ListNode {
public:
T data;
ListNode *prev, *next;
};
ListNode<int> lambdadelta, bernkastel;
lambdadelta.next = &bernkastel;
而 list_head 并不会持有任何 data
struct list_head {
list_head *prev, *next;
};
怎么用那当然是“嵌入”地使用
struct Item {
int data;
list_node node; // 嵌入到具体的结构体中
};
Item furniture, weapon;
furniture.node.next = &weapon.node;
它们主要在指向的地址方面存在差异,尽管如此,Item 仍然可通过 node 的地址计算偏移量,进而得到另一个 Item 的首地址
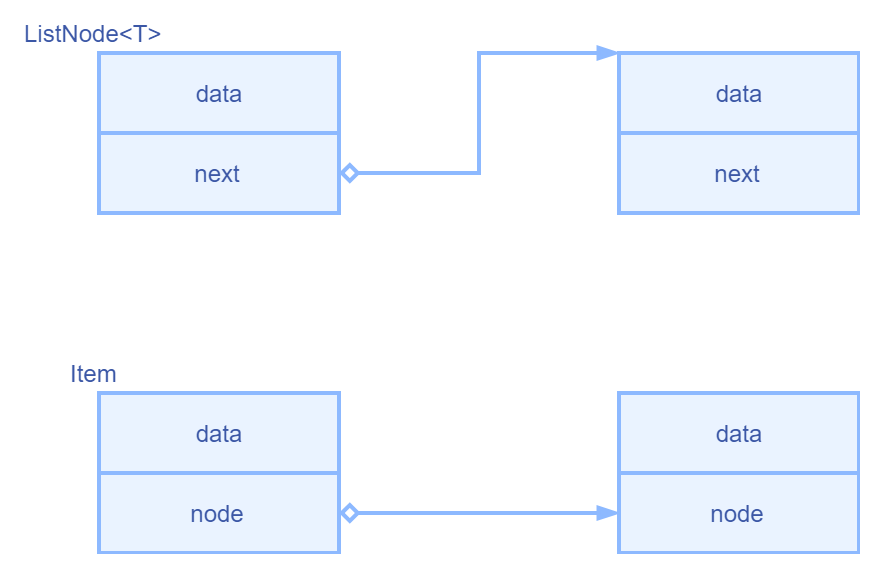
由于在实现过程中有大量用到,因此简单给个印象
wait_queue
另一个频繁且至关重要的工具是等待队列 wait_queue,用于完成两个操作:task 的等待与唤醒(task 并没有限制是什么东西,一般是进程)
主要有两个结构体 wait_queue_head 和 wait_queue
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
struct __wait_queue {
unsigned int flags; // 可选WQ_FLAG_EXCLUSIVE
void *private; // 一般指向关联进程的task_struct
wait_queue_func_t func; // 默认是wakeup函数,当唤醒时调用
struct list_head task_list;
};
注意,虽然第二个结构体命名叫 __wait_queue,但它也是作为结点 entry,而不是一个队列
它们之间的关联通过 task_list 连接在一起,我直接画图来表示吧
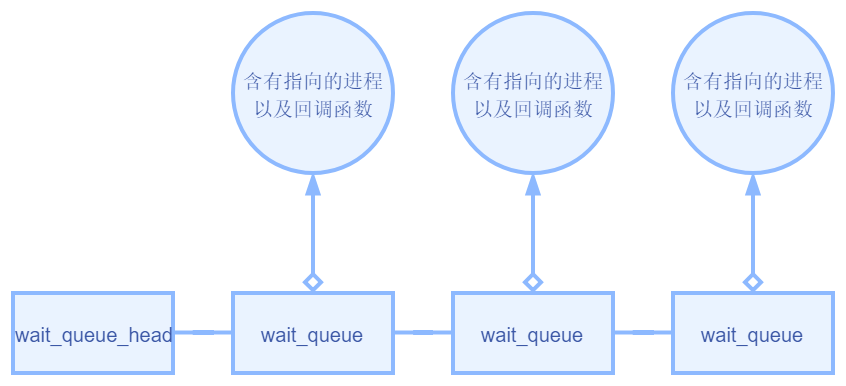
等待的进程会构造关联的 wait_queue 挂到某一个 wake_queue_head 上
当 wake_queue_head 决定要唤醒时,会逐一遍历整个链表,调用回调函数使得唤醒 wait_queue 对应的进程(默认情况下)
特殊的情况后面再讲
f_op->poll
这里介绍文件系统的 poll() 机制,它是一种主动获取文件状态变化的接口,具体是怎么实现的,由各自的 file 来决定
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op; // ⭐
// ...
};
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, bool spin);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *); // ⭐
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
// ...
};
由上面看出,poll 只是一个函数指针,换句话说,就是提供一个接口,用 C 来实现 OOP
可以通过一个简单的实现来大概了解它是怎么做的,这里给出管道文件对应的实现
// 代码位于:fs/pipe.c
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll, // ⭐
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
};
static __poll_t
pipe_poll(struct file *filp, poll_table *wait) // 不必在意细节
{
__poll_t mask;
struct pipe_inode_info *pipe = filp->private_data;
int nrbufs;
// poll_table *wait由调用方提供,主要是提供一个_qproc的自定义回调
poll_wait(filp, &pipe->wait, wait); // 允许用户自定义的操作,十分关键 ⭐⭐
// 这个函数翻译过来就是wait->_qproc(filp, &pipe->wait, wait);
// 即允许调用方在f_op->poll()时对pipe->wait和filp“动手脚”
/* Reading only -- no need for acquiring the semaphore. */
nrbufs = pipe->nrbufs;
mask = 0;
if (filp->f_mode & FMODE_READ) {
mask = (nrbufs > 0) ? EPOLLIN | EPOLLRDNORM : 0;
if (!pipe->writers && filp->f_version != pipe->w_counter)
mask |= EPOLLHUP;
}
if (filp->f_mode & FMODE_WRITE) {
mask |= (nrbufs < pipe->buffers) ? EPOLLOUT | EPOLLWRNORM : 0;
/*
* Most Unices do not set EPOLLERR for FIFOs but on Linux they
* behave exactly like pipes for poll().
*/
if (!pipe->readers)
mask |= EPOLLERR;
}
return mask; // 返回可读,可写,错误,挂起等。。。
}
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
typedef struct poll_table_struct {
poll_queue_proc _qproc;
__poll_t _key;
} poll_table;
/*
* structures and helpers for f_op->poll implementations
*/
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
无非就是三大步骤:
- 获取
pipe实例 - 调用
poll_wait - 根据实例当前的状态给出就绪信息
mask
我们可以在 poll_wait 中添加自己的回调,在后面会有关键的应用
尝试自己实现一个 IO 多路复用?
其实从前面的 f_op->poll 和 wait_queue 的讲解,我们可以简单的猜测出一种 IO 多路复用的实现模型
假设我用 1 个线程 t 去监听 10 个 fd,全部只关注是否可读,任意一个可读就不再阻塞
伪代码:
实现一个多路复用监听接口 `check(int fds[])`
1. 定义callback函数:把线程 `t` 插入到 `fd` 的等待队列中,表示在将来一旦wake up则唤醒当前线程t
2. for(i = 1...10)
对第i个fd进行file->f_op->poll(callback)
mask = f_op->poll(callback)
if(mask & POLLIN) 直接跳到4
3. 没有一个满足(所有mask == 0),阻塞当前线程,如果因任意情况唤醒则回到2
4. 再次扫描for(i = 1...10) 为每一个fd进行poll(NULL),获得每个fd的当前就绪状态,把这些状态返回给用户
这么做似乎是可行的,也略微接近 epoll 的模型
那 epoll 是不是这么干的?显然没这么蠢:
- 假设要监听 \(N\) 个
fd,要想知道是否就绪,这种实现是\(O(N)\),因为需要逐步遍历,而epoll可以做到 \(O(1)\) - 每次操作都要拷贝整个
fds数组到内核态,epoll可以按需拷贝(绝对不拷贝是不可能的)
epoll 不仅比上面的实现更为高效,而且还有更多高级特性:
- 前面的
check肯定是一个LT操作,但epoll还有ET的支持 epoll还支持exclusive的唤醒方式epoll自己也可以被监听
想知道怎么做到的,就需要了解它的实现流程
限于篇幅,高级特性支持的流程会大量略过
实现流程 1 - epoll_create
我们将通过 epoll_create() ——创建 epoll 实例的函数实现,来大概浏览一下 epoll 内部是什么样的
这个模块相对简单,可以让我们知道 epoll 模型到底使用怎样的数据结构来支撑它的运行
PS. 关于 epoll 实现的代码都是采用 4.18 版本
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
return do_epoll_create(flags);
}
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return do_epoll_create(0);
}
// epoll_create1相比epoll_create只有O_CLOEXEC的flag可设置
/*
* Open an eventpoll file descriptor.
*/
// eventpoll是核心的数据结构,内核维护ep,返回关联的fd
// 1. 检查flags
// 2. 初始化ep,使用kmalloc
// 3. 获取fd
// 4. 从anon_inode获取file
// 5. 关联fd file和ep
static int do_epoll_create(int flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
/* Check the EPOLL_* constant for consistency. */
BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
if (flags & ~EPOLL_CLOEXEC)
return -EINVAL;
/*
* Create the internal data structure ("struct eventpoll").
*/
error = ep_alloc(&ep); // ⭐ ep的分配
if (error < 0)
return error;
/*
* Creates all the items needed to setup an eventpoll file. That is,
* a file structure and a free file descriptor.
*/
// 为ep处理fd和file
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
// 初始化
ep->file = file;
fd_install(fd, file); // Install a file pointer in the fd array
return fd;
out_free_fd:
put_unused_fd(fd);
out_free_ep:
ep_free(ep);
return error;
}
static int ep_alloc(struct eventpoll **pep)
{
int error;
struct user_struct *user;
struct eventpoll *ep;
user = get_current_user();
error = -ENOMEM;
// 差不多是 kmalloc(size, flags | __GFP_ZERO),基于slab分配
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
if (unlikely(!ep))
goto free_uid;
mutex_init(&ep->mtx);
rwlock_init(&ep->lock);
init_waitqueue_head(&ep->wq);
init_waitqueue_head(&ep->poll_wait);
INIT_LIST_HEAD(&ep->rdllist);
ep->rbr = RB_ROOT_CACHED;
ep->ovflist = EP_UNACTIVE_PTR;
ep->user = user;
*pep = ep;
return 0;
free_uid:
free_uid(user);
return error;
}
epoll 实例 - eventpoll
从前面可看出 epoll_create 是返回 fd,但是内核却维护一个 eventpoll 的结构体:eventpoll 是 epoll 的实例,也是最为核心的数据结构
/*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*/
// 这里提到,eventpoll存储于file->private_data,并且是整个epoll接口的主要数据结构
// 在实现过程一般简称eventpoll为ep,它管理的若干事件称为epi(epoll-item)
// 这里为了方便讲解,把内部字段的顺序稍微调整了一下
struct eventpoll {
// 为了线程安全,ep一共用了三种锁 (epmutex mtx lock)
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
// 在等待事件时必须用到的互斥锁
struct mutex mtx;
/* Lock which protects rdllist and ovflist */
rwlock_t lock;
/* RB tree root used to store monitored fd structs */
// 红黑树的根,ep维护一棵红黑树用于快速查找是否有对应的epi(感兴趣的event)
// 也就是说,红黑树下的每一个结点都对应一个epi
struct rb_root_cached rbr;
// ep维护两个【等待队列】,稍后讲解wait_queue的原理
// 主要用到wq
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
// 维护两个就绪队列(ready-list + overflow list)。表明已经就绪的fd
// 一个是侵入式的双向链表(list_head),另一个是单向链表(epitem有指向下一个epitem的字段)
/* List of ready file descriptors */
struct list_head rdllist;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
// 分配获得的file文件
struct file *file;
// 后面的比较细节,跳过
};
总结:核心的数据结构 ep 大概维护以下几大类的成员
- 锁:要求线程安全
- 红黑树:要求维护一个存储若干
epi的数据结构 - 等待队列:用于阻塞/唤醒机制
- 就绪队列:事件到来时用到的数据结构
- 文件:
ep归属于哪个文件中
被监听的红黑树结点 - epitem
epitem 在实现流程简称 epi,由前面的 API 调用介绍的第二步 epoll_ctl
// epoll_ctl - control interface for an epoll file descriptor
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
可看出,epoll 是创建实例后,需要添加监听的 fd 和事件类型 event
其实在内部实现中,内核也是维护另外一个数据结构 epitem 来表示 fd 和 event 在 epoll 实例的关系
/*
* Each file descriptor added to the eventpoll interface will
* have an entry of this type linked to the "rbr" RB tree.
* Avoid increasing the size of this struct, there can be many thousands
* of these on a server and we do not want this to take another cache line.
*/
// 上面大概就是说
// 1. 它是ep维护的红黑树的结点,
// 2. 并且因为会大量用到epitem,要尽量减少这个结构体的大小
struct epitem {
// 自身红黑树的结点
union {
/* RB tree node links this structure to the eventpoll RB tree */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
// ep的ready list的结点
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
// 指向同一ep维护的下一个epi,形成单链表,表示下一个在ovflist的epitem结点
struct epitem *next;
/* The file descriptor information this item refers to */
// epi的file和fd
struct epoll_filefd ffd;
/* The "container" of this item */
// epi的容器,归属于哪一个ep
struct eventpoll *ep;
/* The structure that describe the interested events and the source fd */
// 要监听的事件,由调用方调用epoll_ctl得到
struct epoll_event event;
// 下面的用处不大,略
};
总结:被监听的 epitem 维护以下特性:
- 在红黑树的位置(
rbn) - 在就绪队列的位置(
rdllink / next) - 归属的
ep实例容器(ep) - 感兴趣的事件(
event) - 文件(
ffd)
这是最为核心的两个数据结构,任意操作流程都会涉及到
可以通过创建 epoll 实例(epoll_create)和添加监听文件描述符和事件(epoll_ctl(EPOLL_CTL_ADD))的流程来了解两个结构体之间的关系,如下所示
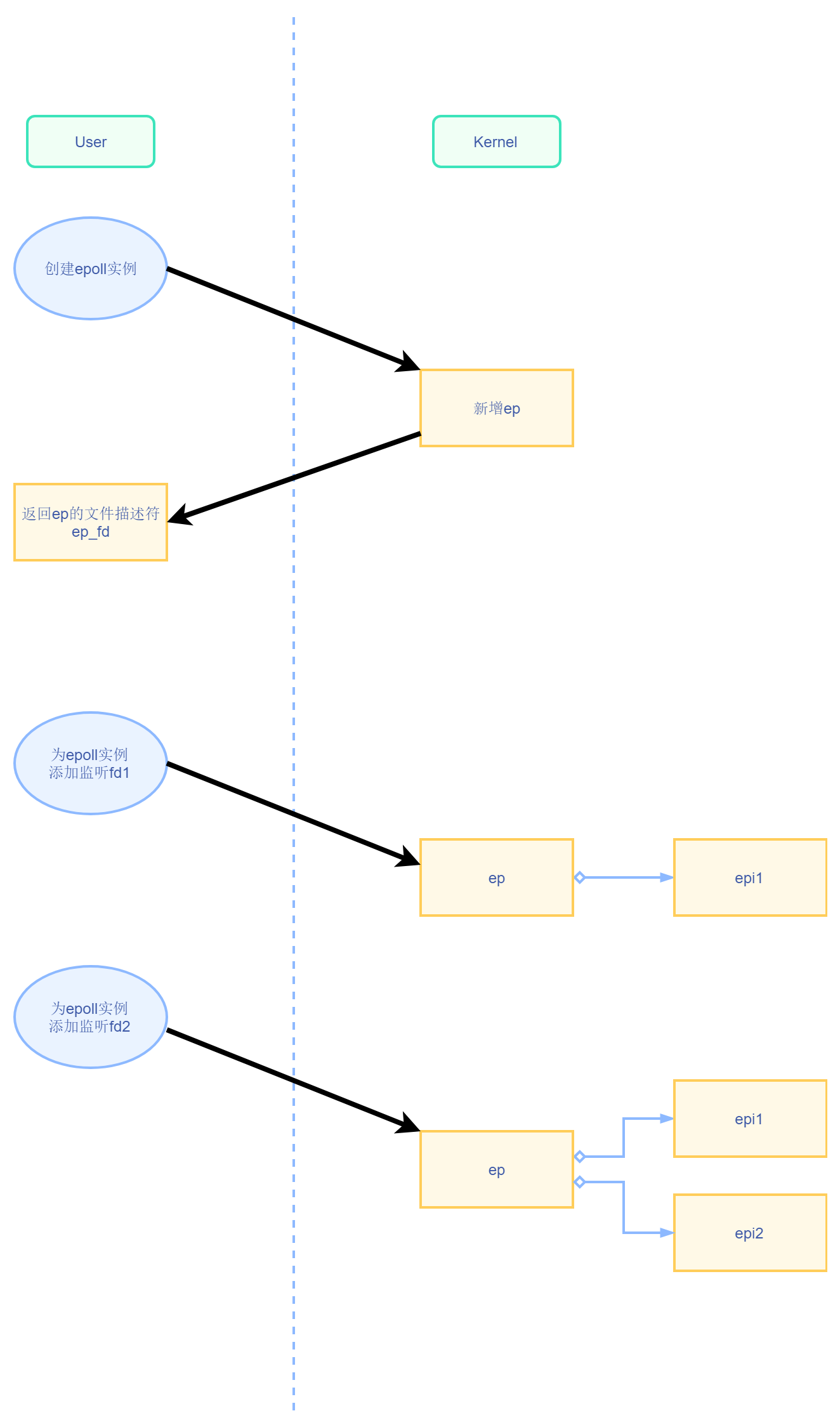
实现流程 2 - epoll_ctl
这里描述的就是上图【添加监听】的流程(epoll_ctl 可以添加、删除、修改监听的事件,这里只详细展开添加的流程)
从上图我们只知道,每次添加,ep 维护的红黑树都会新增一个 epi 结点
但除此以外,并没有明确知道维护的结点有什么用,如何仅通过一个 epi 来实现 IO 多路复用,这些还需要接着了解代码
(这里会删减大量非主干的逻辑)
/*
* The following function implements the controller interface for
* the eventpoll file that enables the insertion/removal/change of
* file descriptors inside the interest set.
*/
// 处理用户态拷贝epds
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct epoll_event epds;
// del不传递epds
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
return -EFAULT;
return do_epoll_ctl(epfd, op, fd, &epds, false);
}
int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds,
bool nonblock)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct eventpoll *tep = NULL;
error = -EBADF;
f = fdget(epfd);
if (!f.file)
goto error_return;
/* Get the "struct file *" for the target file */
tf = fdget(fd);
if (!tf.file)
goto error_fput;
/* The target file descriptor must support poll */
error = -EPERM;
if (!file_can_poll(tf.file)) // 要求file_operations支持poll,内部实现为return file->f_op->poll;
goto error_tgt_fput;
/* Check if EPOLLWAKEUP is allowed */
if (ep_op_has_event(op))
ep_take_care_of_epollwakeup(epds); // 去除EPOLLWAKEUP
error = -EINVAL;
// ep的f不能等同于epi的tf
if (f.file == tf.file || !is_file_epoll(f.file)) // 内部实现为 return file->f_op == &eventpoll_fops;
goto error_tgt_fput;
if (ep_op_has_event(op) && (epds->events & EPOLLEXCLUSIVE)) {
// ... 略
}
ep = f.file->private_data;
error = epoll_mutex_lock(&ep->mtx, 0, nonblock);
if (error)
goto error_tgt_fput;
// ...
// 已经处于线程安全的状态,在红黑树中查找epi
epi = ep_find(ep, tf.file, fd);
error = -EINVAL;
// 核心操作,分别对应于ep_insert / ep_remove / ep_modify
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds->events |= EPOLLERR | EPOLLHUP; // 默认会监听EPOLLERR和EPOLLHUP
error = ep_insert(ep, epds, tf.file, fd, full_check); // ⭐
} else // 不支持重复ADD
error = -EEXIST;
break;
case EPOLL_CTL_DEL:
// ...
case EPOLL_CTL_MOD:
// ...
}
if (tep != NULL)
mutex_unlock(&tep->mtx);
mutex_unlock(&ep->mtx);
error_tgt_fput:
if (full_check) {
clear_tfile_check_list();
loop_check_gen++;
mutex_unlock(&epmutex);
}
fdput(tf);
error_fput:
fdput(f);
error_return:
return error;
}
可以看出,插入 epi 的真正实现在 ep_insert()
一直到 ep_insert() 之前,大多都只做一些简单的检查
/*
* Must be called with "mtx" held.
*/
// 1. 构造epi
// 2. epi插入到rbtree
// 3. 构造封装类epq,注册回调ep_ptable_queue_proc
// 4. poll调用,获取revent
// 5. 处理ready-list
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
int error, pwake = 0;
__poll_t revents;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
lockdep_assert_irqs_enabled();
user_watches = atomic_long_read(&ep->user->epoll_watches);
if (unlikely(user_watches >= max_user_watches))
return -ENOSPC;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL))) // 分配空间
return -ENOMEM;
// 构造epi
/* Item initialization follow here ... */
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd); // 用tfile和fd构造ffd
epi->event = *event;
epi->nwait = 0; // nwait和pwqlist只用于清理的过程,这里会删去与之相关的代码
epi->next = EP_UNACTIVE_PTR; // EP_UNACTIVE_PTR决定是否优先使用overflow-list
// 构造完成
ep_rbtree_insert(ep, epi);
error = -EINVAL;
// callback放入epq
epq.epi = epi;
// 注册回调,应用于vfspoll中 ⭐
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); // pt->_qproc = qproc; pt->_key = ~(__poll_t)0; /* all events enabled */
// 进行epi对应fd的poll调用,对fd进行poll可以获得revents
revents = ep_item_poll(epi, &epq.pt, 1); // ⭐
error = -ENOMEM;
if (epi->nwait < 0)
goto error_unregister;
/* We have to drop the new item inside our item list to keep track of it */
write_lock_irq(&ep->lock);
/* record NAPI ID of new item if present */
ep_set_busy_poll_napi_id(epi);
/* If the file is already "ready" we drop it inside the ready list */
// 已经ready但是没有在rdllist
if (revents && !ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq)) // 内部实现 !list_empty(&wq_head->head)
wake_up(&ep->wq); // 唤醒ep->wq下的所有task_struct, 问题:什么时候ep->wq有挂载的结点?
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
write_unlock_irq(&ep->lock);
return 0;
error_unregister:
ep_unregister_pollwait(ep, epi);
error_remove_epi:
// ...
error_create_wakeup_source:
kmem_cache_free(epi_cache, epi);
return error;
}
这里涉及到关键的操作,
一是构造了一个 epq 的封装类实例,用它来关联 epi 和回调函数,并通过这种方式注册一个 ep_ptable_queue_proc 回调函数
二是针对新构造的 epi 调用了 ep_item_poll 来获取 revents(received event),这里把上面提到的回调函数 ep_ptable_queue_proc 传入进去
三是涉及到 ready-list 的插入,以及 ep->wq 的唤醒,但这里我们并不知道 ep->wq 里面是什么时候有结点的,以及 ready-list 是否还有其它的插入流程
后面了解剩下的 ep_item_poll 流程以及 pt(即 ep_ptable_queue_proc)的行为
/*
* Differs from ep_eventpoll_poll() in that internal callers already have
* the ep->mtx so we need to start from depth=1, such that mutex_lock_nested()
* is correctly annotated.
*/
// 通过epi得到对应file,并调用其f_op->poll(它本身不是epoll file的话)
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
struct file *file = epi->ffd.file;
__poll_t res;
pt->_key = epi->event.events;
if (!is_file_epoll(file)) // f->f_op == &eventpoll_fops, 非嵌套进入该分支
res = vfs_poll(file, pt); // 调用file->f_op->poll(file, pt)
else // 这个分支我们并不关心
res = __ep_eventpoll_poll(file, pt, depth);
return res & epi->event.events; // revents
}
ep_item_poll 只干一件事情,那就是调用 vfspoll 接口,它的具体实现,取决于 file 的 f_op->poll()
前面已经提供,用户可以通过主动地去 poll 来获取这个 fd 的就绪事件 res
那么在 vfspoll 中接着传递下去的回调 ep_ptable_queue_proc 是希望在我们主动 poll 的时候做什么样的事情
/*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/
// 放入epq的callback,主要处理pwq
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead, // pwq 将插入到 whead,以pipe为例,whead就是pipe->wait
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt); // // 从pt获取自身容器epi
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
// 并且pwq本身插入到whead中,wakeup whead时pwq调用ep_poll_callback
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist); // pwq也挂到epi->pwqlist上
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
这里的 pwq 也是一个简单的封装类,用于关联 epitem 和 wait_queue(whead 指向监听 fd 的 wait_queue_head,wait 是 epi 自身的等待队列结点)
在 poll 的流程中,epi 被插入到 fd 的等待队列 whead 中(取决于具体实现),并且插入到队列时注册一个 ep_poll_callback 函数,当唤醒 whead 队列时,轮到 epi 对应的 wait_queue 则会调用 ep_poll_callback
/*
* This is the callback that is passed to the wait queue wakeup
* mechanism. It is called by the stored file descriptors when they
* have events to report.
*/
// 1. 获取pollflags
// 2. 检查events
// 3. epi插入到overflow-list或者ready-list,如果是overflow-list则结束流程
// 4. 唤醒阻塞在ep->wq的进程
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait); // 差不多是container_of
struct eventpoll *ep = epi->ep;
__poll_t pollflags = key_to_poll(key); // 转换类型,回调时传入获得的flag
int ewake = 0; // ewake用于return,具体的含义我觉得是允许exclusive wake的意思,具体看__wake_up_common的逻辑
spin_lock_irqsave(&ep->wq.lock, flags);
ep_set_busy_poll_napi_id(epi);
/*
* If the event mask does not contain any poll(2) event, we consider the
* descriptor to be disabled. This condition is likely the effect of the
* EPOLLONESHOT bit that disables the descriptor when an event is received,
* until the next EPOLL_CTL_MOD will be issued.
*/
if (!(epi->event.events & ~EP_PRIVATE_BITS)) // 关注event连基本的EPOLLIN之类的都没有
goto out_unlock;
/*
* Check the events coming with the callback. At this stage, not
* every device reports the events in the "key" parameter of the
* callback. We need to be able to handle both cases here, hence the
* test for "key" != NULL before the event match test.
*/
if (pollflags && !(pollflags & epi->event.events)) // 没有用户感兴趣的event
goto out_unlock;
/*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/
if (ep->ovflist != EP_UNACTIVE_PTR) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi; // 插头
if (epi->ws) {
/*
* Activate ep->ws since epi->ws may get
* deactivated at any time.
*/
__pm_stay_awake(ep->ws);
}
}
goto out_unlock;
}
// 如果插入到ovflist,则不会进入ready-list
/* If this file is already in the ready list we exit soon */
if (!ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
}
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!(pollflags & POLLFREE)) {
switch (pollflags & EPOLLINOUT_BITS) {
case EPOLLIN:
if (epi->event.events & EPOLLIN)
ewake = 1;
break;
case EPOLLOUT:
if (epi->event.events & EPOLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up_locked(&ep->wq);
}
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep->wq.lock, flags);
if (!(epi->event.events & EPOLLEXCLUSIVE))
ewake = 1;
return ewake;
}
ep_poll_callback 是 fd 开始 wake up 进行的操作,主要处理
- 插入等待队列
- (可能)唤醒
ep->wq
实现流程 3 - epoll_wait
epoll_wait 接口会主动引起阻塞 (timeout != 0 时),并随后唤醒返回有多少就绪事件
/*
* Implement the event wait interface for the eventpoll file. It is the kernel
* part of the user space epoll_wait(2).
*/
// 从epfd获取ep实例
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
int error;
struct fd f;
struct eventpoll *ep;
/* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
/* Verify that the area passed by the user is writeable */
if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event)))
return -EFAULT;
/* Get the "struct file *" for the eventpoll file */
f = fdget(epfd);
if (!f.file)
return -EBADF;
/*
* We have to check that the file structure underneath the fd
* the user passed to us _is_ an eventpoll file.
*/
error = -EINVAL;
if (!is_file_epoll(f.file))
goto error_fput;
/*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
ep = f.file->private_data;
/* Time to fish for events ... */
error = ep_poll(ep, events, maxevents, timeout); // ⭐
error_fput:
fdput(f);
return error;
}
/**
* ep_poll - Retrieves ready events, and delivers them to the caller supplied
* event buffer.
*
* @ep: Pointer to the eventpoll context.
* @events: Pointer to the userspace buffer where the ready events should be
* stored.
* @maxevents: Size (in terms of number of events) of the caller event buffer.
* @timeout: Maximum timeout for the ready events fetch operation, in
* milliseconds. If the @timeout is zero, the function will not block,
* while if the @timeout is less than zero, the function will block
* until at least one event has been retrieved (or an error
* occurred).
*
* Returns: Returns the number of ready events which have been fetched, or an
* error code, in case of error.
*/
// 如果timeout == 0
// 则会直接检查event的ready-list,如果ready-list存在entry则ep_send_events,然后直接return res
// 如果timeout > 0
// 1. 先进入fetch流程,同时该流程仅针对就绪队列为空才执行
// 1.1 当前调用epoll_wait的current加入到ep->wq,使用默认的callback
// 1.2 只要被唤醒不符合条件(没event||没超时||没中断),则会再次wait
// 2. 进入到check流程
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res = 0, eavail, timed_out = 0;
unsigned long flags;
long slack = 0;
wait_queue_t wait;
ktime_t expires, *to = NULL;
if (timeout > 0) {
struct timespec end_time = ep_set_mstimeout(timeout);
slack = select_estimate_accuracy(&end_time);
to = &expires;
*to = timespec_to_ktime(end_time);
} else if (timeout == 0) {
/*
* Avoid the unnecessary trip to the wait queue loop, if the
* caller specified a non blocking operation.
*/
// timed_out为true将不会进入for(;;)
timed_out = 1;
spin_lock_irqsave(&ep->lock, flags);
goto check_events;
}
fetch_events: // 当没有event时,current作为entry加入到ep->wq中,后面将陷入阻塞,直到存在event/超时/中断
if (!ep_events_available(ep))
ep_busy_loop(ep, timed_out);
spin_lock_irq(&ep->wq.lock);
if (!ep_events_available(ep)) { // 检查rdllist ovflist,当前没有就绪的就进行阻塞
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
init_waitqueue_entry(&wait, current);
__add_wait_queue_exclusive(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
set_current_state(TASK_INTERRUPTIBLE);
/*
* Always short-circuit for fatal signals to allow
* threads to make a timely exit without the chance of
* finding more events available and fetching
* repeatedly.
*/
if (fatal_signal_pending(current)) {
res = -EINTR;
break;
}
if (ep_events_available(ep) || timed_out)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irq(&ep->wq.lock);
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) // 调度,sleep until timeout
timed_out = 1;
spin_lock_irq(&ep->wq.lock);
}
__remove_wait_queue(&ep->wq, &wait);
__set_current_state(TASK_RUNNING);
}
check_events: // 检查是否有event就绪
/* Is it worth to try to dig for events ? */
eavail = ep_events_available(ep);
spin_unlock_irq(&ep->wq.lock);
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && !timed_out) // ⭐
goto fetch_events; // timeout==0的情况下肯定不会goto
// 如果timeout>0的情况下尚未超时,会不断地在限定时间内尝试fetch_events(因为ep_send_events给出地esed.res为0返回无意义)
// ep_events_available == true 但是 ep_send_events == 0 可能是put_user无法完成等原因导致的
// 只要单次获得大于0的ep_send_events(或出错)则跳出goto循环
return res;
}
epoll_wait 会进行阻塞直到有事件返回,这个过程分为两部分:fetch_events 和 fetch_events
其中,fetch_events 实现了阻塞的过程,而 check_events 不只是检查 event,还会处理遍历 ready-list 并传递到用户态的细节
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct ep_send_events_data esed;
esed.maxevents = maxevents;
esed.events = events;
ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false);
return esed.res;
}
/**
* ep_scan_ready_list - Scans the ready list in a way that makes possible for
* the scan code, to call f_op->poll(). Also allows for
* O(NumReady) performance.
*/
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *, // sproc == ep_send_events_proc
struct list_head *, void *),
void *priv, int depth, bool ep_locked) // priv == esed
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist); // transaction list
if (!ep_locked)
mutex_lock_nested(&ep->mtx, depth);
spin_lock_irqsave(&ep->lock, flags);
list_splice_init(&ep->rdllist, &txlist); // 合并两个链表到txlist,然后rdllist重置为empty list
ep->ovflist = NULL; // 允许使用ovflist
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Now call the callback function.
*/
error = (*sproc)(ep, &txlist, priv); // 对txlist进行vfspoll等操作
spin_lock_irqsave(&ep->lock, flags);
/*
* During the time we spent inside the "sproc" callback, some
* other events might have been queued by the poll callback.
* We re-insert them inside the main ready-list here.
*/
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* We need to check if the item is already in the list.
* During the "sproc" callback execution time, items are
* queued into ->ovflist but the "txlist" might already
* contain them, and the list_splice() below takes care of them.
*/
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist); // 把overflow-list的swap到ready-list
ep_pm_stay_awake(epi);
}
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
ep->ovflist = EP_UNACTIVE_PTR;
/*
* Quickly re-inject items left on "txlist".
*/
list_splice(&txlist, &ep->rdllist); // 在sproc阶段,如果对于txlist的各个epi,任意一个出错(有revent但无法put_user)会重新插回txlist并退出sproc流程
__pm_relax(ep->ws);
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
// 可能是监听文件状态变化wakeup导致插入新的ready-list(这种情况在ctl阶段已经wakeup-exclusive了)
// 也可能是前面overflowlist/txlist残留
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
if (!ep_locked)
mutex_unlock(&ep->mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return error;
}
// sproc
// 遍历txlist的epi,进行vfspoll
// 处理要拷贝到用户态的events
// LT逻辑,重新插回ready-list
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head, // head == txlist
void *priv) // priv只用于传递esed封装类
{
struct ep_send_events_data *esed = priv;
__poll_t revents;
struct epitem *epi;
struct epoll_event __user *uevent;
struct wakeup_source *ws;
poll_table pt;
init_poll_funcptr(&pt, NULL);
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
for (esed->res = 0, uevent = esed->events;
!list_empty(head) && esed->res < esed->maxevents;) {
epi = list_first_entry(head, struct epitem, rdllink);
list_del_init(&epi->rdllink);
revents = ep_item_poll(epi, &pt, 1); // epi进行vfspoll,此时pt为NULL
if (revents) {
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
// 出错了
list_add(&epi->rdllink, head);
ep_pm_stay_awake(epi);
if (!esed->res)
esed->res = -EFAULT;
return 0;
}
esed->res++;
uevent++; // 下一个 esed.events大小由用户指定,内核不做额外检查,直接++
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
// LT特色,此前已经list_del_init(&epi->rdllink);重新插回ready-list
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
}
return 0;
}
流程图
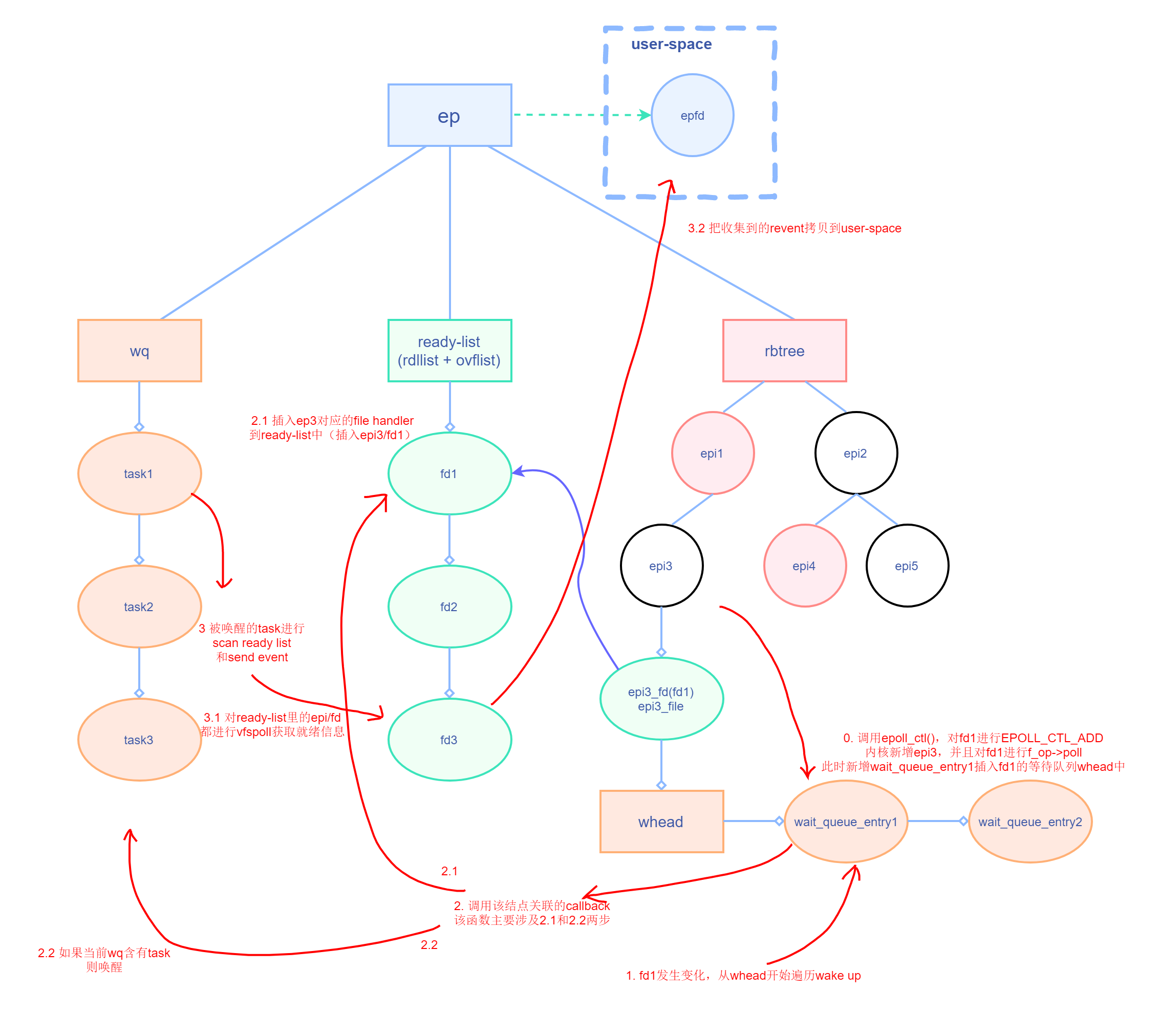
值得思考的问题
下面会提出几个问题,这些都可以在流程里总结出来
epoll 快在哪里
epoll 的实现对比之前上文提到的低配版实现,其实是通过很简单的方式来做到高效
- 每次检查
vfspoll只在ready-list上检查,而不遍历所有关注的事件,只要 \(O(1)\) 判断ready-list为空就知道必然没有就绪事件 - 通过分出
epoll_ctl和epoll_wait接口,并内部维护容器(红黑树)来避免每次调用都全盘拷贝
哪些文件支持 epoll
前面已经提到,epoll 调用到 f_op->poll(),因此,实现了 poll 接口的文件都可以
int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds,
bool nonblock)
{
// ...
/* Get the "struct file *" for the target file */
tf = fdget(fd);
if (!tf.file)
goto error_fput;
/* The target file descriptor must support poll */
error = -EPERM;
if (!file_can_poll(tf.file)) // 要求file_operations支持poll,内部实现为return file->f_op->poll;
goto error_tgt_fput;
常见支持的文件类型有 socket,pipe,timerfd
像普通的磁盘文件 (ext4 为例) 是不支持的
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
}; // 没有.poll
另外,epoll_create 返回一个 epfd 给用户,其实这么写也是为了让 epoll 文件自身也支持被 epoll 监听
LT 与 ET,区别与坑
在前面的流程有写到
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head, // head == txlist
void *priv) // priv只用于传递esed封装类
{
// ...
for (esed->res = 0, uevent = esed->events;
!list_empty(head) && esed->res < esed->maxevents;) {
// ...
revents = ep_item_poll(epi, &pt, 1);
if (revents) {
// ...
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
// LT特色,此前已经list_del_init(&epi->rdllink);重新插回ready-list
list_add_tail(&epi->rdllink, &ep->rdllist); // ⭐
ep_pm_stay_awake(epi);
}
}
}
return 0;
}
函数大概是收集 ready-list 上的 epi 的就绪信息,里面有一条细节
只要有 revents 并且不是 ET 模式,就重新插回 ready-list
这意味着:下次 epoll_wait 唤醒,这些曾经有过 revents 的 epi 也会再次遍历,直到下次 vfspoll 没有 revents 返回才不再插回
这样满足了只要有就绪事件,就不断可以通知的机制,因此称为 LT 模型(在我们刚才实现的低配版多路复用也是 LT 模型)
而 ET 模型的差别在于,有就绪事件,则只会通知一次,如果不一次性(在下一次 epoll_wait 前)处理完,则不再通知
(因为并没有在 ready-list 中)
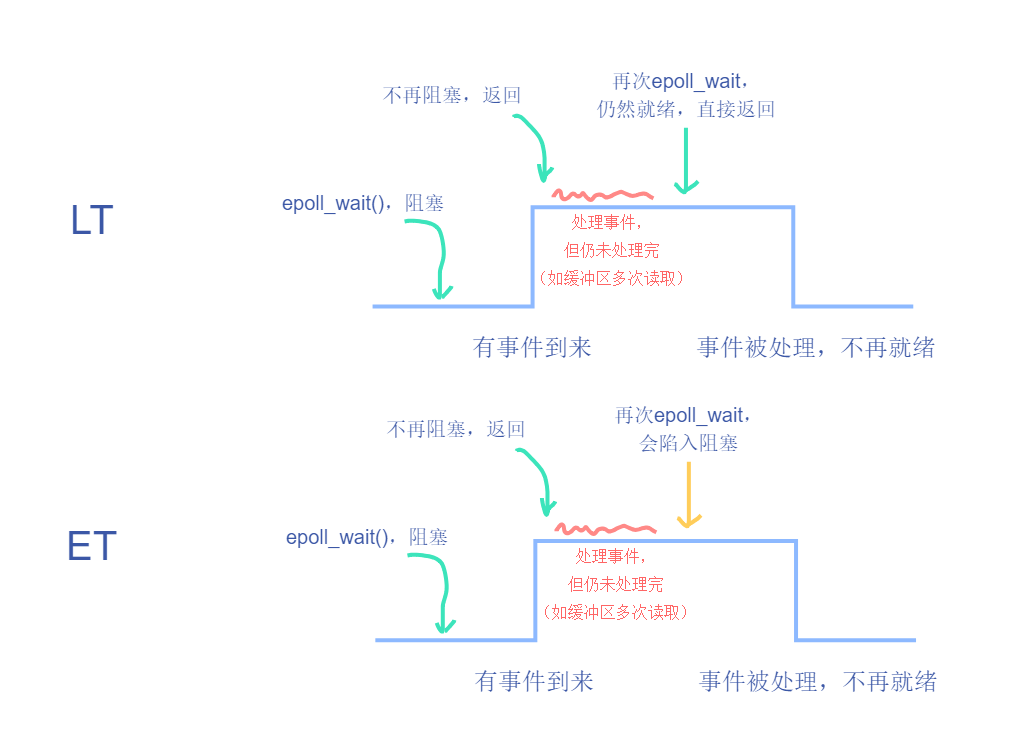
因此,对于 ET 模式的使用,需要 epoll_wait 获取事件时,必须单次处理完成所有就绪事件,否则会丢失信息
“惊群”问题
当多个 epoll 实例(每个线程各占一个实例)监听同一个 fd,并且都陷入 epoll_wait 阻塞时,如果此时有一个事件就绪,将会导致所有 epoll_wait 阻塞全部唤醒,这种现象称为惊群
原因在于被监听 fd 的等待队列 whead,会遍历队列去执行,那如果是把整个队列都调用了每个 ep 实例所注册的 ep_ptable_queue_proc,则会引起多个 epoll 实例唤醒
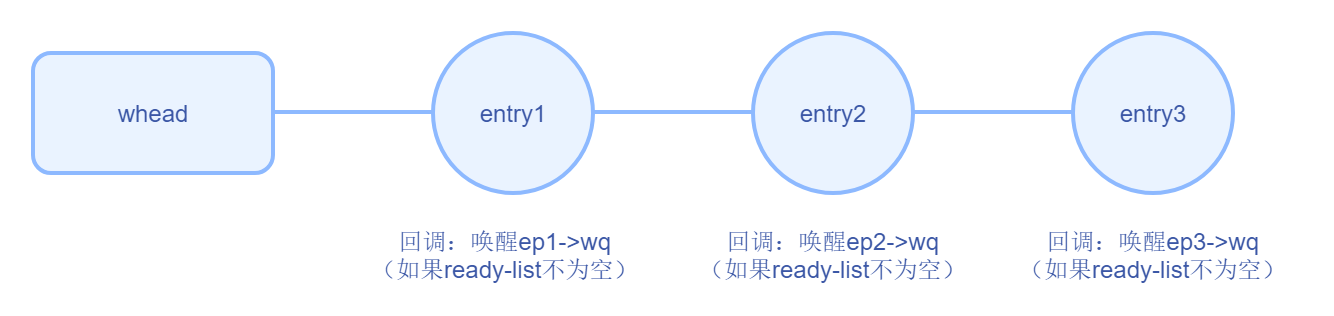
(详细回调见前面流程图的 2.1 和 2.2)
能不能避免这种不必要的惊群?(同一个 fd 只能被某个 epoll 实例处理,多个唤醒属于多余的行为)
Linux 解决这个问题的做法是允许用户在 epoll_ctl 添加一个 EPOLLEXCLUSIVE 的 flag,这个关联到等待队列的一种特性
我们在前面提到了,默认情况下,等待队列会从头结点开始逐一遍历结点并回调相应函数,因此层层递进造成了前面的惊群现象
但是等待队列也允许插入“互斥”的结点(默认是不互斥的),在这里提一下不互斥(简称 N)与互斥(简称 E)的结点有哪些不同的行为
在插入等待队列上:N 插入头部,E 插入尾部
在遍历上:迭代到 N 无条件继续处理,迭代到 E 则计数器减一,计数为 0 则终止
由于插入行为上的不同,一个等待队列总是会保持前缀为 N,后缀为 E 的性质,即 NNNNNNEEEE,只要遍历时计数器为 1,则每次至多只处理 1 个互斥结点(如果全部都是互斥结点的话)
回到 EPOLLEXCLUSIVE,这个 flag 就是决定前面的插入顺序,Linux 只用如此精简的策略就能避免一定的惊群
// vfspoll时的poll_wait调用
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
// ...
// wakeup whead时pwq调用ep_poll_callback
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait); // 使得wake up时允许互斥
else
add_wait_queue(whead, &pwq->wait);
// ...
}
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
(互斥唤醒还有更加复杂的细节,比如在 wakeup 时回调为 ep_poll_callback,其返回值 ewake 也有限制什么时候允许互斥的分类处理,如果 ewake 为 0,即使结点本身是互斥的,遍历时也会仍按照非互斥的方式去处理)
图文无关
最近在云通关《海猫鸣泣之时》,绘梨花这副嚣张又吃瘪的模样实在是令人忍俊不禁

23.6.19 update
偶尔回顾一下自己写的文章(特么的写得真好),感觉对当时取的标题不太满意
这篇文章以前就叫epoll in depth,长度上短了点,于是我让 new bing 帮我取了一个新的标题
又改了一遍,AI 起的名字还是太长了