回顾自己的陈年笔记,诧异于以前还整理过这方面的资料。可惜我完全没有印象,不如重新整理一遍,Linux 版本更新为 6.4.8。
NOTE: 本文暂不包含 MGLRU 部分(Pixel 8 / Android 14 默认启用),后面有机会再另开一篇文章。
内存回收类型
内存回收分为:
- 快速回收。
- 直接回收。
- kswapd 回收。
主要区分点是触发时机和处理页面类型。
快速回收的触发时机为低水位快速路径内存分配失败时。可以处理非脏页。
直接回收的触发时机为慢速路径内存分配过程中,内存整理失败时。可以处理非脏页。
kswapd 回收的触发时机为快速路径分配失败后,进入慢速分配路径,先于直接回收执行 kswapd 回收。可以处理所有页面,包括脏页。
它们的共同点是均使用 LRU 链表等数据结构作为回收用的容器,并且回收流程相似。对于匿名页,可以放入到 swap 分区;对于文件页,脏页可以进行写回操作,非脏页直接释放即可。
数据结构
数据结构主要是 LRU 链表(lruvec),以及 LRU 缓存(pagevec)。
LRU 缓存
LRU 缓存的数据结构如下:
/* Layout must match folio_batch */
struct pagevec {
unsigned char nr;
bool percpu_pvec_drained;
struct page *pages[PAGEVEC_SIZE];
};
/**
* struct folio_batch - A collection of folios.
*
* The folio_batch is used to amortise the cost of retrieving and
* operating on a set of folios. The order of folios in the batch may be
* significant (eg delete_from_page_cache_batch()). Some users of the
* folio_batch store "exceptional" entries in it which can be removed
* by calling folio_batch_remove_exceptionals().
*/
struct folio_batch {
unsigned char nr;
bool percpu_pvec_drained;
struct folio *folios[PAGEVEC_SIZE];
};
/*
* The following folio batches are grouped together because they are protected
* by disabling preemption (and interrupts remain enabled).
*/
struct cpu_fbatches {
local_lock_t lock;
struct folio_batch lru_add;
struct folio_batch lru_deactivate_file;
struct folio_batch lru_deactivate;
struct folio_batch lru_lazyfree;
#ifdef CONFIG_SMP
struct folio_batch activate;
#endif
};
LRU 缓存 pagevec 通过 page 到 folio 的封装关联 folio_batch 和 cpu_fbatches,前者提供批量页面(改为 folio 形式)操作,后者提供 每 CPU 同名变量 cpu_fbatches 缓存。因此 LRU 缓存是 folio 兼容的。
提供 LRU 缓存的目的是为了减缓频繁的锁操作,如果 LRU 每次对单个页的添加移除都需要操作 LRU 上的锁,那么会有不必要的冲突。因此,使用 LRU 缓存来提供批量操作:先将需要变动的页面放入到 LRU 缓存中,再批量处理。LRU 缓存能批量处理的页面数为 PAGEVEC_SIZE,即固定值 15,这个数字加上首部数据符合 2 的幂。
15 pointers + header align the pagevec structure to a power of two.
LRU 链表
LRU 链表存放于 per-node 级别的 pglist_data 中,数据结构如下:
struct lruvec {
struct list_head lists[NR_LRU_LISTS];
/* per lruvec lru_lock for memcg */
spinlock_t lru_lock;
/*
* These track the cost of reclaiming one LRU - file or anon -
* over the other. As the observed cost of reclaiming one LRU
* increases, the reclaim scan balance tips toward the other.
*/
unsigned long anon_cost;
unsigned long file_cost;
/* Non-resident age, driven by LRU movement */
atomic_long_t nonresident_age;
/* Refaults at the time of last reclaim cycle */
unsigned long refaults[ANON_AND_FILE];
/* Various lruvec state flags (enum lruvec_flags) */
unsigned long flags;
#ifdef CONFIG_LRU_GEN
/* evictable pages divided into generations */
struct lru_gen_folio lrugen;
/* to concurrently iterate lru_gen_mm_list */
struct lru_gen_mm_state mm_state;
#endif
#ifdef CONFIG_MEMCG
struct pglist_data *pgdat;
#endif
};
NOTE: 如果使用了 memcg,即使是 UMA 架构的情况,那也不只是一个 lruvec。这部分细节可以看上方链接的注释。
出于页面特征(文件页和匿名页)的区分和运行效率考虑,LRU 链表分为 5 种类型:
- ACTIVE FILE
- INACTIVE FILE
- ACTIVE ANON
- INACTIVE ANON
- UNEVICITABLE
其中 UNEVICITABLE 较为特殊,适用于被锁定的内存页面:
- Those owned by ramfs.
- Those owned by tmpfs with the noswap mount option.
- Those mapped into SHM_LOCK’d shared memory regions.
- Those mapped into VM_LOCKED
mlock()ed VMAs.
NOTE: 在 Multi-Gen LRU 机制(CONFIG_LRU_GEN)中,ACTIVE 和 INACTIVE 被归为某种 generation,而 generation 是可配置的,并不只是 ACTIVE 和 INACTIVE。
基本操作
LRU 的基本操作(插入、移动)集中在 mm/swap.c,6.x 后 page 均经过 folio 封装。
比如一个 add 操作(folio_add_lru())的简化代码就是:
folio_add_lru(folio):
folio_ref_inc(folio)
local_lock(cpu_fbatches.lock)
fbatch = this_cpu(cpu_fbatches.lru_add)
folio_batch_add_and_move(fbatch, folio, lru_add_fn) ⭐
local_unlock(cpu_fbatches.lock)
基本操作主要依靠 folio_batch_add_and_move(..., move_fn_t) 接口和接受的 move_fn_t 类型的回调函数 lru_add_fn() 完成。简单来说,接口部分就是将 folio 页面添加到 fbatch 缓存中,如果缓存已满,则遍历缓存中的所有页面并执行回调;实现部分挑选页面对应的 LRU 链表(lruvec_add_folio())并插入。
状态转移
Double CLOCK lists
Per node, two clock lists are maintained for file pages: the
inactive and the active list. Freshly faulted pages start out at
the head of the inactive list and page reclaim scans pages from the
tail. Pages that are accessed multiple times on the inactive list
are promoted to the active list, to protect them from reclaim,
whereas active pages are demoted to the inactive list when the
active list grows too big.
fault ------------------------+
|
+--------------+ | +-------------+
reclaim <- | inactive | <-+-- demotion | active | <--+
+--------------+ +-------------+ |
| |
+-------------- promotion ------------------+
/* 状态转移 */
如上图,页面在 LRU 中进行状态转移的基本情况为:
- 当首次 page fault 时(产生映射),会加入到 INACTIVE 当中。
- 当 INACTIVE 中的 page 被访问多次,会 promote 到 ACTIVE。
- 当 ACTIVE 过大时,会 demote 到 INACTIVE(以平衡两端大小)。
- 页面在链表的位置按照 LRU 算法来定位。
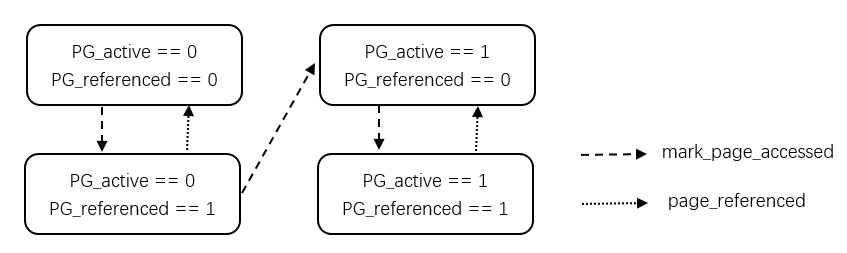 状态转移 pro
状态转移 pro
实现上,页面的转移依靠 page flags 标记,如上图所示。这方面也可以看 folio_mark_accessed() 的注释。一个结论是 INACTIVE 链表上的页面被标记访问两遍即提升(promote)到 ACTIVE 链表。
NOTE: 时过境迁,上图的第一个函数 mark_page_accessed 已改名 folio_mark_accessed,第二个函数 page_referenced 更改为 folio_referenced。
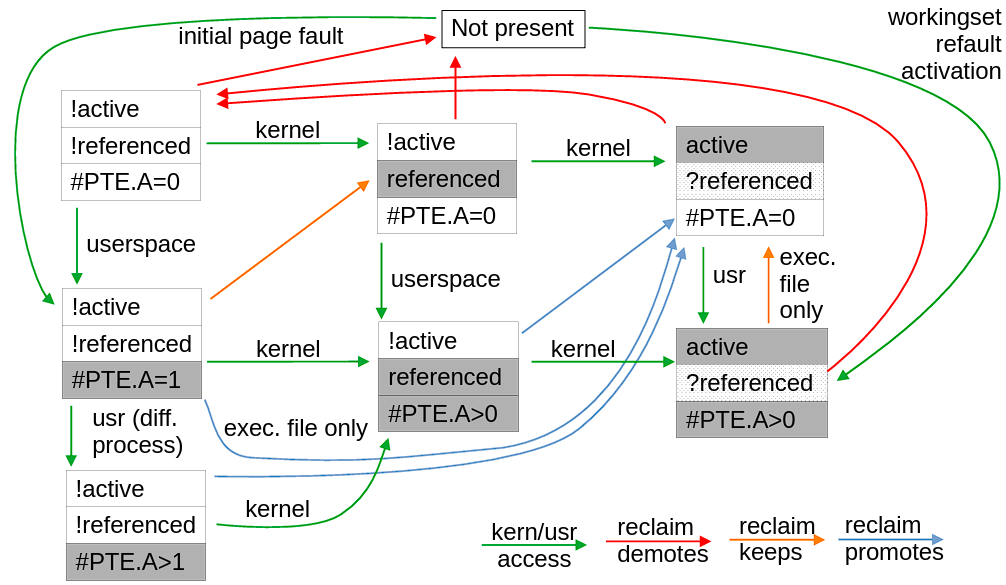 状态转移 pro max
状态转移 pro max
另外提供一份更加复杂的状态转移图。这里 PTE.A 指的是 struct page 通过反向映射得到的对应页表项 A 位(accessed bit)的统计个数(因为一个 struct page 可以映射到多个 PTE)。X86 中的 A 位访问页表就会自动置一,只能通过手动的方式置零(显然 kernel access 可以手动控制,但是 userspace 没有办法)。问号 ? 表示此时并不关心该字段。diff. 表示不同的进程,因为不同的进程有不同的页表,因此可以做到 PTE.A>1。回收保留(keep)操作虽然使得页面保留在原链表上,但是会置于尾部。其它的细节较多,请看作者的演讲。
另外再提一下页面的初始状态。对于匿名页,会在 do_anonymous_page()(也就是 page fault 时)产生页面并加入到 LRU 中,在早期版本如 5.4.1,是直接加入到 ACTIVE 链表中,参考这行代码;而在后期版本如 5.11.22(随手找的,具体时间点请翻 blame)又变动为 INACTIVE 链表,参考这行代码;直到 6.4.8 仍然是 INACTIVE,但是修改成 folio 封装函数,参考这行代码。对于文件页就没啥好说的,必然 INACTIVE。
/* 备忘录:关于初始状态 (v6.4.8) */
// 匿名页的 LRU 加入时机
do_anonymous_page
folio_add_lru_vma
folio_add_lru
// 文件页的 LRU 加入时机
filemap_fault
__filemap_get_folio
filemap_add_folio
folio_add_lru
至于我是怎么发现匿名页行为区别的,是因为之前写了一个 meminfo parser,偶然观察到不同版本的 LRU 统计有区别,这篇文章记录了 5.15 的 mmap 测试结果,这里又记录了 5.4 和 5.15 的差异。
工作集检测
这一块比较抽象,细节可以参考 mm/workingset.c 对 refault distance 算法的注释。
LRU 的淘汰机制会导致回收抖动的存在(页面不断往复于被回收和再次载入的状态,也就是 refault),因此需要工作集检测。个人理解是 refault 其实是应该作为活跃页面去看待,但是 LRU 会反复由回收载入,原因出现在把页面放入到 INACTIVE 上。因此,如果能检测出工作集,那就直接放入到 ACTIVE 链表(如上图 working set refault activation),不仅少走几步弯路,也避免了错误的回收。
精准的计算是难以实现的,内核的做法是使用估算访问距离(access distance,同一页面两次访问的时间间隔中,LRU 所访问的页面数)的算法。下面是对算法的一些比较枯燥的解释。
观察两个事实:
- 访问首次缺页异常(fault)的页面,该页面会插入到 INACTIVE 链表头部,相当于该链表淘汰另一个页面,并且链表上所有的页面都往尾部方向挪动一个单位;
- 访问 INACTIVE 链表上的页面若引发某页面的提升行为,那么从链表头部到该页面前的其它页面也相当于往尾部方向挪动一个单位。
得出两个结论:
- INACTIVE 链表上,任意时间段的最小访问距离 ≈ 该时间段的淘汰次数和提升次数之和(sum)。
- INACTIVE 链表上,如果一个页面能往尾部方向移动 N 个单位,至少要访问 N 次(其它)页面。
再次推理:
- in-cache distance:一个页面从载入到淘汰,那就至少访问 \(NR\_inactive\)(INACTIVE 链表长度)次页面。所以页面在缓存内的访问距离为 \(NR\_inactive\)。
- out-of-cache distance:页面淘汰时的 sum 记为 \(E\),再次载入时的 sum 记为 \(R\),缓存外的访问距离即为 \(R-E\)。(同时这个也是 refault distance)
- complete access distance:从 (new)fault 到 refault 的完整访问距离,就是将缓存内外时间段的访问距离结合起来,即 \(NR\_inactive + (R-E)\)。
推理到第三点就可以玩更抽象的了。只要访问距离小于等于内存总和,那就能让页面免受淘汰:
\[\begin{equation} \begin{aligned} NR\_inactive + (R-E) &\le total\_memory \\ NR\_inactive + (R-E) &\le NR\_inactive + NR\_active \\ (R-E) &\le NR\_active \end{aligned} \end{equation}\]NOTE: 为什么如此绕弯路,理论上保证 INACTIVE 链表长度大于等于 \(R\)(以 fault 为时间起点)不就能保证 refault 页面存活了吗?我觉得这确实是对的,但是工作集检测算法的妙处在于不需要这种条件,因为工作集检测出 refault 页面,是直接加入到 ACTIVE 链表,无需确保 INACTIVE 下限,可谓是二流企业看现金流,顶流企业看预期前景。这样避免了 INACTIVE 链表过长从而 ACTIVE 链表过短(毕竟长度不是凭空冒出来的……)导致 LRU 和 second chance 算法的缓存特性被动减弱。
但是考虑到 LRU 链表拆分为文件页类型和匿名页类型,式子左边的 \(NR\_inactive\) 应为具体的某个类型,而右边 \(total\_memory\) 是算上四种组合的 LRU 链表,也就是说最后应该是这样的形式:
对于文件页:
\[(R-E) \le NR\_active\_file + NR\_inactive\_anon + NR\_active\_anon\]对于匿名页:
\[(R-E) \le NR\_active\_anon + NR\_inactive\_file + NR\_active\_file\]算法实现见 workingset_refault() 流程,左边的式子靠 lruvec 提供一个 nonresident_age 计数器来完成(搭配一种称为 shadow entry 的技巧),右边的式子就是所谓的工作集大小。总之,结论是满足以上公式就能做到上一章节图示的 working set refault activation,也就是 folio_set_active(folio)。
全局回收
无论是快速回收、直接回收还是 kswapd 回收,它们的回收算法都会集中在同一个流程。
// 快速回收
get_page_from_freelist
node_reclaim
__node_reclaim
shrink_node
// 直接回收
__alloc_pages_slowpath
__alloc_pages_direct_reclaim
__perform_reclaim
try_to_free_pages
do_try_to_free_pages
shrink_zones
shrink_node
// kswapd 回收
kswapd
balance_pgdat
kswapd_shrink_node
shrink_node
因此 shrink_node() 就是回收算法的核心。这里区分全局回收和 memcg 回收,但是由于本文作者太菜,所以只考虑全局回收。这部分包含的几块内容分小节分析。
页面扫描
回收算法需要决定扫描页面的数目,以及文件页和匿名页的扫描比例。在算法实现上,页面扫描的决策大概分了两步:一是根据当前负载分析出一些特殊场合,二是根据回收的成本来决定页面类型之间的扫描比例。页面扫描的行为有相当大量的细节集中在扫描控制结构,也可以看下里面的注释。
继续探究页面扫描之前先了解一下 LRU 链表的平衡处理。
链表平衡
链表平衡指的是依靠降级(demote)将过短的 INACTIVE 链表延长。通常来说 LRU 维护的准则是 ACTIVE 链表拥有更高占比,而 INACTIVE 占比在撑得住 refault 压力的前提下尽可能小。
为了避免极端情况,需要一些简单快速的平衡保底方法。内核中 inactive_is_low() 判定是直接按总内存划分比例的方式来计算的。只要 \(\frac{active}{inactive} > target\_ratio\) 就是 low,这就可能引起降级。
注释里也直接给出了一些提前算好的参考值:
| total memory | target ratio | max inactive |
|---|---|---|
| 10MB | 1 | 5MB |
| 100MB | 1 | 50MB |
| 1GB | 3 | 250MB |
| 10GB | 10 | 0.9GB |
| 100GB | 31 | 3GB |
| 1TB | 101 | 10GB |
| 10TB | 320 | 32GB |
\(target\_ratio:1\) 的代码实现也很直接,1GB 以下的总内存按照 1:1 的比例,更高内存总量则按照 \(\sqrt{\frac{10 \times (active + inactive)}{2^{18}}}:1\) 比例。(\(active\) 和 \(inactive\) 的单位是 4K,除掉 \(2^{18}\) 就是转换到 GB 为单位,至于开根乘 10 有点像大学考试的挂科捞人算法,确实捞人也是一种 balancing……)
负载分析
回到页面扫描的准备阶段,在 prepare_scan_count() 函数中存在几种特殊场景的判断:
- may_deactive: 观察到 refault 现象且链表长度失衡。
- cache_trim_mode: 有足够多的非活跃 page cache(easily reclaimable cold cache)。
- file_is_tiny: 内存高压,文件页过少(The file folios are dangerously low)。
When refaults are being observed, it means a new workingset is being established. Deactivate to get rid of any stale active pages quickly. mm/vmscan.c
除此以外还包括一些零散的场景,概括的判断逻辑如下表:
| 特殊场景 | 判断条件 | 影响 |
|---|---|---|
| 没有交换空间 | !may_swap | 如果满足条件,扫描平衡强制设为 SCAN_FILE,表示不扫描匿名页。 |
| 接近 OOM | 1. !priority 2. swappiness | 如果满足条件,扫描平衡强制设为 SCAN_EQUAL,表示平等地扫描文件页和匿名页。 |
| may_deactive | 1. refault 2. inactive_is_low | 如果满足条件,允许执行 shrink_active_list();否则,标记为 skipped_deactivate,跳过降级操作,同时直接回收中的下一次启动不允许再次跳过。 |
| cache_trim_mode | 1. inactive_file > \(2^{priority}\) 2. !may_deactive(INACTIVE_FILE) | 如果满足条件,扫描平衡强制设为 SCAN_FILE,表示不扫描匿名页。 |
| file_is_tiny | 1. !memcg 2. inactive_file+active_file+free < high_watermark 3. !may_deactive(INACTIVE_ANON) 4. inactive_anon > \(2^{priority}\) | 如果满足条件,扫描平衡强制设为 SCAN_ANON,表示只扫描匿名页。 |
NOTE: 其实 priority 为 0 就可以表达「接近 OOM」的意思,swappiness 不为 0 的判断是暗讽用户在 OOM 救火前就不要自作主张做压力平衡(见页面成本小节),除非你严重反对地禁止了 swap。
TODO: priority 和 swappiness 说明,默认优先级优化场景。
页面成本
匿名页和文件页的实际回收成本并不相同(可能某种页面需要更多的 IO,取决于设备和负载等因素),因此需要定义成本(或者是压力,内核注释也会描述为 pressure balancing)。
成本的估算定义在 lru_note_cost(),会在链表缩容(ACTIVE 和 INACTIVE)或者 refault 检测中触发计算。计算方式是同时考虑 IO 和 CPU 的处理开销,分别统计写页次数 \(pageout\) 和 LRU 旋转次数 \(scanned - reclaimed\),最终把 \(cost\) 结果存放于 lruvec 的 file_cost 或 anon_cost 字段中。
NOTE: \(pageout\) 的作用见 pageout(),表示对脏页执行 writepage(),清除 PG_dirty 和标记 PG_reclaim 位等操作;公式具体怎样考虑的也可以看下 commit 的解释,反正我也不太懂……
在一般场景(没有在特殊场景里面设置扫描平衡)中,扫描平衡模式是 SCAN_FRACT,也就是基于「fractional cost model」去划分页面扫描比例,大白话就是按各自成本的倒数做除法运算。
NOTE: 我调试的时候发现有点不合预期(并不是简单按成本比例的倒数,注释里提了一句 we limit that influence to ensure no list gets left behind completely),主要是 L3074 和 L3075 行的叠加导致的,只能说成本对比例的影响有限。我顺手把测试样例抽离出来了,里面也有 fractional cost model 的简化公式,你可以自己试试。
总之,简记 anon_cost 为 \(a\),file_cost 为 \(b\),swappiness 为 \(x\),代入算法并简化。
对于匿名页要扫描的数目为:
\[scan \times \frac{(a+2b)x}{400a+200b+(b-a)x}\]对于文件页要扫描的数目为 scan 减去匿名页扫描数:
其实了解这个公式没什么意义,一方面它不是给人看的(我是用表达式简化工具算出来的),另一方面算法总是会不断优化而变动的。
这里的扫描数目存放于 nr[] 数组中,会在后续链表缩容环节用到。
链表缩容
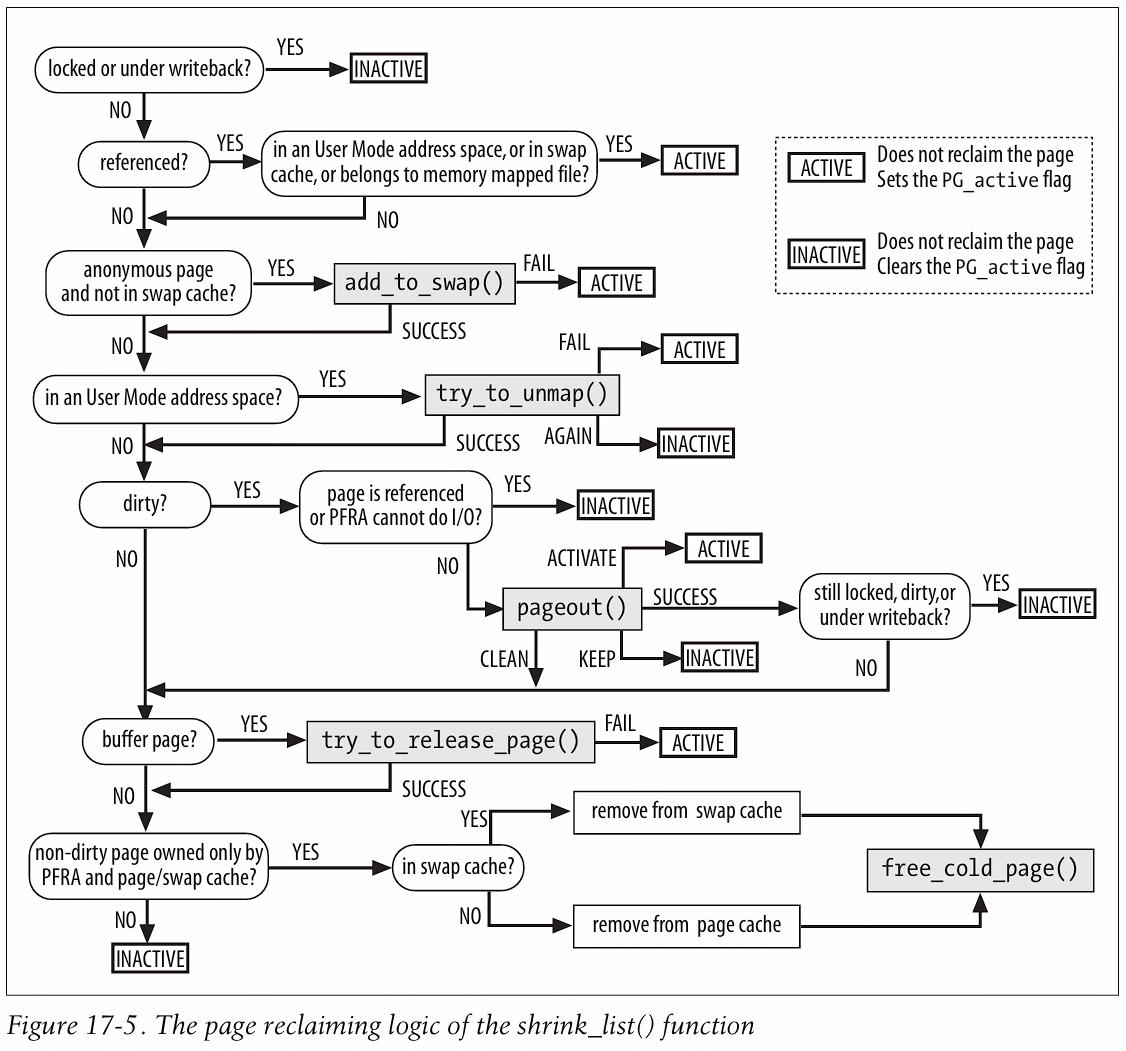
在全局回收算法中,完成了前面提到的准备工作后即可进入链表缩容流程 shrink_list()(从 shrink_lruvec() 进入)。如果是简单理解的话,就是区分 shrink_active_list() 和 shrink_inactive_list(),对于遍历扫描到的页面,前者尝试降级操作,后者尝试回收操作。
但实际上 shrink_list() 的代码实现只能用丧心病狂来形容(被自己菜哭( ´_ゝ`)旦),先放个 ULK 书里的示意图吧,这是很多年前的实现不一定对得上 6.x 版本,需要花点时间看代码。
!!!!! WORK IN PROGRESS !!!!!
TODO
🕊️ watermark 行为,boost 特性等。
🕊️ 三种回收触发流程,扫描控制初始化等。
🕊️ slab 缩容。
References
Overview of Memory Reclaim in the Current Upstream Kernel
深入理解 Linux 内存管理(七)内存回收
linux 内存源码分析 - 内存回收 (lru 链表)
linux 内存源码分析 - 内存回收 (整体流程)
跟踪 LRU 活动情况和 Refault Distance 算法
Linux 中的内存回收 [二]
linux 内存回收 之 File page 的 lru list 算法原理
Page PG_referenced vs PG_active bit?
Better active/inactive list balancing
Unevictable LRU Infrastructure
内存回收 2:关键结构体 struct scan_control