早些年前也翻过一遍 perfbook,记得每天午休都是从公司闲逛到清河地铁站,边走边看。可惜由于本人太菜,品鉴不到什么。现在重新做点笔记,常读常新。
注意这里 perfbook 指的是 paulmck 大神的 Is Parallel Programming Hard, And, If So, What Can You Do About It?,不是 dendibakh 的同名手册。看的版本是 v2023.06。
共享内存的系统
作者在开篇提到一个问题:并行编程是否应该尽可能抽象而不去关注硬件特性?回答是不要这么做。忽略硬件特性可以简化问题,但在大多数情况下其实相当愚蠢。一方面,追求并行编程的目的就是为了性能,那么性能是取决于硬件特性,在逻辑上就要求工程师至少需要了解一些硬件特性;另一方面,认知不足的工程师做不出像样的玩意。
以缓存互联为例

上图给了一个经典的系统硬件架构。当一个内存上的数据尝试读取到寄存器,或者从寄存器写入到内存的时候,系统必须要处理 cacheline。但是缓存可能是 CPU 共享的,也可能是独立且互联的。
For example, if CPU 0 were to write to a variable whose cacheline resided in CPU 7’s cache, the following over-simplified sequence of events might ensue:
- CPU 0 checks its local cache, and does not find the cacheline. It therefore records the write in its store buffer.
- A request for this cacheline is forwarded to CPU 0’s and 1’s interconnect, which checks CPU 1’s local cache, and does not find the cacheline.
- This request is forwarded to the system interconnect, which checks with the other three dies, learning that the cacheline is held by the die containing CPU 6 and 7.
- This request is forwarded to CPU 6’s and 7’s interconnect, which checks both CPUs’ caches, finding the value in CPU 7’s cache.
- CPU 7 forwards the cacheline to its interconnect, and also flushes the cacheline from its cache.
- CPU 6’s and 7’s interconnect forwards the cacheline to the system interconnect.
- The system interconnect forwards the cacheline to CPU 0’s and 1’s interconnect.
- CPU 0’s and 1’s interconnect forwards the cacheline to CPU 0’s cache.
- CPU 0 can now complete the write, updating the relevant portions of the newly arrived cacheline from the value previously recorded in the store buffer.
像上面的示例行为就是缓存一致性协议的简化形式,由 CAS 操作引起。从该硬件特性可以看到,即使是单个指令,也会引起可观的协议开销。另一个层面上,协议对于长时间不更新的数据是允许跨 CPU cachelines 做到多个副本并存,而我们也依靠这种硬件特性来实现 read-mostly 变量的优化(也就是 RCU 等延迟处理技术)。
原子操作的开销
| Operation
| Cost (ns)
| Ratio (cost/clock)
| CPUs
|
| Clock period
| 0.5
| 1.0
|
|
| Same-CPU
|
|
| 0
|
| CAS
| 7.0
| 14.6
|
|
| lock
| 15.4
| 32.3
|
|
| On-Core
|
|
| 224
|
| Blind CAS
| 7.2
| 15.2
|
|
| CAS
| 18.0
| 37.7
|
|
| Off-Core
|
|
| 1–27, 225–251
|
| Blind CAS
| 47.5
| 99.8
|
|
| CAS
| 101.9
| 214.0
|
|
| Off-Socket
|
|
| 28–111, 252–335
|
| Blind CAS
| 148.8
| 312.5
|
|
| CAS
| 442.9
| 930.1
|
|
| Cross-Interconnect
|
|
| 112–223, 336–447
|
| Blind CAS
| 336.6
| 706.8
|
|
| CAS
| 944.8
| 1,984.2
|
|
| Off-System
|
|
|
|
| Comms Fabric
| 5,000
| 10,500
|
|
| Global Comms
| 195,000,000
| 409,500,000
|
|
上表是一个 8-Socket with Intel Xeon Platinum 8176 CPUs 的系统,用以观察 CAS 操作的开销。
Same-CPU 前缀表示正在某个变量上执行 CAS 操作的 CPU 是上一次访问该变量的同一个 CPU。也就是说对应的 cacheline 在执行 CAS 前就已经缓存了。lock 可视为两次的 CAS 操作,即 acquire 和 release,所以开销接近翻倍。注意这份表都是以 CPU 0 的视角为前提。
On-Core 涉及同一核心的不同硬件线程之间的交互。由于硬件线程之间完全共享了缓存层次架构,其开销接近于 Same-CPU 操作。这里的 CPU 224 与 CPU 0 是同核心超线程的关系。
Blind CAS 指的是直接指定 cmpxchg 时的旧值参数(一般命名为 expected 或者 old)而无需查看内存地址。这种一般适用于持锁操作,比如一个 unlocked 状态使用 0 去表示,locked 状态使用 1 去表示,用于 lock() 实现的 CAS 操作只需判断旧值为 0,新值为 1。与常规 CAS 不同在于,这里只有 1 次(CAS 操作本身的)内存地址访问,因此开销会更低。
常规 CAS 操作的旧值是从之前早期的 load 操作得到的。比如尝试做一次原子增加计数的操作,load 操作先获取当前值;然后该数值加一以产生另一个数值;再到 CAS 操作,刚才实际被 load 的值作为旧值,产生的值作为新值。这里有 2 次内存地址访问操作,一次是 load 操作,另一次是 CAS 操作本身,因此开销会更高。所以这种额外的 load 操作并非免费的午餐,对比之下,On-Core blind CAS 和 Same-CPU CAS 的开销是接近的。
剩下的跨核心、跨 socket 这些,只能说域之间的距离越远,通信带来的延迟惩罚越大。对比一个普通指令,其开销已有百倍到千倍的差距。
硬件优化的方向
这本书不关注硬件优化这个话题,只给方向。除了传统的加大缓存、写入缓冲、预取优化和投机执行以外,还提供了更加先进的方向比如 3D 堆叠、新型材料、加速卡和光子芯片等等供人参考,唉跟不上 paul 大神的思维了。
软件实现的启发
CAS 操作通常要假设大概率要与外部 CPU 通信,这代表着(因被动地响应 invalidate message 而导致)cache miss 的产生。而且从上表来看,越是复杂庞大的系统要承受的开销占比则越高。
我们必须依靠硬件的特性减少通信的次数。就基本策略来看,一种思路是使用几乎没有通信的彼此隔离的线程,另一种思路是确保任何共享数据都是以读取为主。书里要讲的技巧基本都围绕这两点展开。
并行原语和工具
第四章开头比较偏手册(堆 API),就不摘抄太多了。总之作者的意思是,如果不强求「do parallel programming the hard way」,你可以考虑直接使用 shell 实现并行编程,比如 & 搭配 wait,或者是管道 |。除此以外,POSIX thread 和 GCC(classic)/C11/GCC(modern) atomic 库都是趁手的工具。
线程和锁的讨论
POSIX 通过 lock 原语避免 data race。为了避免可能存在的歧义,这里需要同步一下本文适用的 data race 概念:A data race occurs when there are multiple concurrent accesses to a given variable, at least one of which is a plain C-language access and at least one of which is a store. 另外,作者在这里没有深入讨论良性的数据竞争(benign data race,也就是符合上面定义,且不影响结果的正确性),只给结论:编译器越是先进(激进),这种现象就越是稀少(见共享变量的恶意小节)。
顺手找了些资料,还有一点个人说明:
- Oracle 的文档提供了一个
良性的示例。注意这里可能假定了编译器不做激进优化。
- HP 的论文给出了观点:(会被编译器介入的)源码层面的 data race 应该全部视为错误。
- 一个更简单的良性示例:假设两个线程并发访问同一个计数器,一个线程不断写入,另一个线程不断读取。已知在特定场合中写入的数值必然是单调递增的,读线程只需要得知计数器是否大于 5,而在并发访问时已经读到了 7,不管写线程同时写入了什么数值,其结果都是不影响正确性的。良性的数据竞争可能要求体系结构的 plain store 具有原子性,这点在 Oracle 的文档里也有提示。
- 关于 data race:C++ 使用的概念有所不同,主要是关联到 atomic 操作(store/load/RMW)和 happens-before 关系。此事在先前写的笔记中亦有记载。

POSIX 还为(线程数量上)读者多而写者少的场合提供了 POSIX Reader-Writer Locking(即读写锁 pthread_rwlock_t),以期望相比 POSIX Locking(即互斥锁 pthread_mutex_t)能获得更好的可扩展性。但是需要注意不同临界区(时间)长度对于读写锁的扩展性问题,上图给出了读写锁在不同临界区的扩展性衰减程度,即使是高达 10000 us 长度的临界区,依然有接近 10% 的性能衰减(别看近似一条水平直线,纵坐标是按对数尺度画出来的)。
要真正提供高扩展性,有多种思路:
- 如果数据绝不更新,那根本不需要持有任何类型的锁。
- 如果数据低频更新,可以设置检查点,在更新数据前终止线程,更新后从检查点重新启动线程。
- 或者减小锁粒度:每个线程中维护自己的互斥锁,读操作获取自己的锁,写操作则获取所有的锁。
- 对于极小的临界区,可以参考后续延迟处理章节。
NOTE: 这里忽略了不少实验细节,感兴趣翻原文。
原子操作和屏障
使用原子操作和屏障,这对于足够小的临界区来说也是比使用锁更好的方案。
GCC (Classic) 提供了原子操作和屏障的原语:
- 原子操作:
__sync_fetch_and_*() 和 __sync_*_compare_and_swap() 等函数。
- 内存屏障:
__sync_synchronize()。
在特殊场合下,可能需要更多(GCC 没提供的)原语:
- 防止编译器重排序(编译器屏障):
barrier()。
- 防止编译器访问优化:
READ_ONCE() 和 WRITE_ONCE()。
// barrier() 和 *_ONCE() 这些函数可以使用下面的代码来实现
// 这也是 Linux 内核中的简化实现
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define READ_ONCE(x) \
({ typeof(x) ___x = ACCESS_ONCE(x); ___x; })
#define WRITE_ONCE(x, val) \
do { ACCESS_ONCE(x) = (val); } while (0)
#define barrier() __asm__ __volatile__("": : :"memory")
C11 标准和 Modern GCC 也提供了类似的原子操作和屏障的原语,前者引入了 C11 内存模型(也就是 memory order 标记),后者还将原语扩展到了非原子类型。比如 __atomic_store_n(&x, v, __ATOMIC_RELAXED) 和 WRITE_ONCE() 是非常相似的原语。
- A READ_ONCE(), WRITE_ONCE(), and the now-obsolete ACCESS_ONCE() accesses may be modeled as a
volatile memory_order_relaxed access.
- Note that the
volatile is absolutely required: Non-volatile memory_order_relaxed is not sufficient.
P0124R8: Variable Access
共享变量的恶意
尽管使用 GCC 的 synchronize 原语可以做到 full barrier 的保证,但这并不代表共享变量的访问是安全的。即使是标量类型的变量执行 plain store/load 操作,编译器都有权假定该变量不被其它线程所访问和修改,这意味着有大量的编译器优化隐含在里面破坏你的并发代码。
NOTES:
- 使用 lock 原语可以保证访问共享变量的安全。
- plain store/load 指的是不使用 C11 atomic、内联汇编以及 volatile 访问。
- 永远记得并发编程要考虑单线程的场合,你不能忽略内核态中断和用户态
signal()。
- 极端的场合甚至要考虑 on-stack 和 per-CPU 变量的并发访问风险,不过这是仅限于内核。
共享变量的访问模式中,常见被破坏的现象有:
- load tearing:一次 load 操作被编译器优化为多个 load 操作。
- store tearing:一次 store 操作被编译器优化为多个 store 操作。
- load fusing:使用单次 load 获得的值替代重复 load 操作。
- store fusing:使用最后的 store 操作替代连续的 store 操作。
- code reordering:即 program order 重排序。
- invented loads:将 load 时使用的临时(局部)变量直接替换为最终使用的变量。
- invented stores:将 store 操作临时存放于暂时未被使用或不再使用到的变量。
- store-to-load transformations:一次 store 操作被转换为先 load(用于分支判断)再 store。
- dead-code elimination:操作被消除。
NOTES:
// 清单 4.19 给出的问题代码
void shut_it_down(void)
{
status = SHUTTING_DOWN; /* BUGGY!!! */
start_shutdown();
while (!other_task_ready) /* BUGGY!!! */
continue;
finish_shutdown();
status = SHUT_DOWN; /* BUGGY!!! */
do_something_else();
}
void work_until_shut_down(void)
{
while (status != SHUTTING_DOWN) /* BUGGY!!! */
do_more_work();
other_task_ready = 1; /* BUGGY!!! */
}
清单 4.19 给出了一段非常短但是能让开发者献祭无数遍的代码,假设这两个函数是并行的:
- 考虑 store fusing。假设
start_shutdown() 和 finish_shutdown() 不会访问到 status(通过内联等方式得知),编译器有权认为首个 status 赋值是多余的,移除并只保留最后一次赋值;因此 work_until_shut_down() 无法结束 while 循环,从而导致 other_task_ready 无法置位;所以 shut_it_down() 中的 while 循环也无法结束。
- 考虑 code reordering。假设
do_more_work() 不会访问到 other_task_ready,编译器也有权调换代码顺序,使得 other_task 值位先于 while 循环执行;从而破坏了 shut_it_down() 的状态,使得 finish_shutdown() 先于 do_more_work() 执行。
- 考虑 invented stores。假设
do_more_work() 是内联于 work_until_shut_down() 当中,编译器也有权在 while 执行时,将 do_more_work() 内使用到的临时变量存放到函数外部的 other_task_ready;由于 other_task_ready 可以(提前)置为任意 do_more_work() 用到的数值,同样破坏了 shut_it_down() 的状态。
- 最后还是要考虑硬件相关的 CPU reordering。
还有很多代码示例,推荐翻书或者看上面的 LWN 专题。后面小节也会有修复方案。
解决方案的选择
我们需要解决掉编译器带来的众多问题,解决方案可以有多种:
- 使用 volatile 修饰符。尽管 volatile 具有明显的争议(实现定义)和不清晰的语言标准描述。但是 Linux 内核的内存模型指定了 volatile 的实现,在合适的对齐和大小的前提下禁止了上述的编译器优化行为。另外在使用上并不直接声明 volatile,而是
READ_ONCE() 和 WRITE_ONCE()。
- 使用 barrier 编译器屏障。作者在 Code Reordering 小段中指出,现代 CPU 在特定场合下可以不考虑 CPU 重排序,比如中断例程已有「看到此前所有指令,且看不到后续任何指令」的屏障效果。而在必要的限制硬件乱序时,使用
smp_mb() 替代 barrier()。
- 使用原子类型和 memory order。
- 使用锁或者限制特定 CPU / 线程访问变量以避免数据竞争。
注意虽然作者没有明说,但是前两种解决方案是建立在 Linux 内核的基础上。如果我们是开发用户程序而非内核,第一选择应该是直接使用语言标准提供的内存模型,即原子类型和 memory order 标记。
| 问题代码
| 修复方案
|
// 清单 4.19 给出的问题代码
void shut_it_down(void)
{
status = SHUTTING_DOWN; /* BUGGY!!! */
start_shutdown();
while (!other_task_ready) /* BUGGY!!! */
continue;
finish_shutdown();
status = SHUT_DOWN; /* BUGGY!!! */
do_something_else();
}
void work_until_shut_down(void)
{
while (status != SHUTTING_DOWN) /* BUGGY!!! */
do_more_work();
other_task_ready = 1; /* BUGGY!!! */
}
| // 清单 4.29 给出的 4.19 修复方案
void shut_it_down(void)
{
// 使用 READ_ONCE() 和 WRITE_ONCE() 避免编译器优化
WRITE_ONCE(status, SHUTTING_DOWN);
// 同时使用 smp_mb() 避免 CPU 乱序执行
smp_mb();
start_shutdown();
while (!READ_ONCE(other_task_ready))
continue;
smp_mb();
finish_shutdown();
smp_mb();
WRITE_ONCE(status, SHUT_DOWN);
do_something_else();
}
void work_until_shut_down(void)
{
while (READ_ONCE(status) != SHUTTING_DOWN) {
smp_mb();
do_more_work();
}
smp_mb();
WRITE_ONCE(other_task_ready, 1);
}
|
另外,作者还补充了 READ_ONCE() 和 WRITE_ONCE() 的使用原则。在大多数情况下,共享变量必须使用 READ_ONCE() 和 WRITE_ONCE(),但是也有一些范式(感觉分得太细了,先 mark):
- A shared variable is only modified by a given owning CPU or thread, but is read by other CPUs or threads. All stores must use WRITE_ONCE(). The owning CPU or thread may use plain loads. Everything else must use READ_ONCE() for loads.
- A shared variable is only modified while holding a given lock, but is read by code not holding that lock. All stores must use WRITE_ONCE(). CPUs or threads holding the lock may use plain loads. Everything else must use READ_ONCE() for loads.
- A shared variable is only modified while holding a given lock by a given owning CPU or thread, but is read by other CPUs or threads or by code not holding that lock. All stores must use WRITE_ONCE(). The owning CPU or thread may use plain loads, as may any CPU or thread holding the lock. Everything else must use READ_ONCE() for loads.
- A shared variable is only accessed by a given CPU or thread and by a signal or interrupt handler running in that CPU’s or thread’s context. The handler can use plain loads and stores, as can any code that has prevented the handler from being invoked, that is, code that has blocked signals and/or interrupts. All other code must use READ_ONCE() and WRITE_ONCE().
- A shared variable is only accessed by a given CPU or thread and by a signal or interrupt handler running in that CPU’s or thread’s context, and the handler always restores the values of any variables that it has written before return. The handler can use plain loads and stores, as can any code that has prevented the handler from being invoked, that is, code that has blocked signals and/or interrupts. All other code can use plain loads, but must use WRITE_ONCE() to prevent store tearing, store fusing, and invented stores.
内存模型的介绍
个人补充一点关于 LKMM(Linux 内核的内存模型)的简单介绍。主要是作者还没有说明 memory order 这一部分,后面第十五章才有讨论。
除了内核文档以外,也可以参考 P0124 提案和 liburing 封装:
- smp_mb:接近 C/C++ 内存模型的 seq-cst 全序双向栅栏,但是还有额外的语义(略)。
- smp_rmb:接近 C/C++ 内存模型的 acq-rel 双向栅栏,但是只保证栅栏前后 load-load 不乱序。
- smp_wmb:接近 C/C++ 内存模型的 acq-rel 双向栅栏,但是只保证栅栏前后 store-store 不乱序。
- ACQUIRE 语义:保证栅栏后的 pol-(load&store) 都不越界,pol-store 对所有 CPU 可见。
- RELEASE 语义:保证栅栏前的 poe-(load&store) 都不越界,poe-store 对所有 CPU 可见。
- 说明:po = program order, l = later, e = earlier。
可以看出 smp_mb 以及 ACQUIRE/RELEASE 基本和 C/C++ 语言标准用到的内存模型保持一致,但是 smp_rmb 和 smp_wmb 是非常宽松的(acq-rel 在重排序方面强势多了)。这里仍建议对比 P0124 的前后修订版本,关注一下 smp_rmb 和 smp_wmb 描述的变动。liburing 的实现也值得参考,它没有考虑 smp_rmb 和 smp_wmb,而其他的语义都照着语言标准做了一层封装。
计数器的设计
第五章讨论的是不同场合下的计数器实现。
 引起洪荒的原子操作
引起洪荒的原子操作
至少有两个不好的做法:
- 直接使用非原子自增(
*_ONCE() 版本的 counter 自增),大量的数据会被丢失。
- 全部使用原子自增(
atomic_inc(&counter)),多核的扩展性会很差。
总之要学会看场景去优化。
统计计数器
统计计数器的特点在于写多读少,比如统计网络包的数据量。

设计思路就是使用 per-thread/CPU 的计数器。当更新时只需更新线程本地的计数器,读取时再把所有线程的计数器聚合起来。
基于数组的实现源码
DEFINE_PER_THREAD(unsigned long, counter);
static __inline__ void inc_count(void)
{
unsigned long *p_counter = &__get_thread_var(counter);
WRITE_ONCE(*p_counter, *p_counter + 1);
}
static __inline__ unsigned long read_count(void)
{
int t;
unsigned long sum = 0;
for_each_thread(t)
sum += READ_ONCE(per_thread(counter, t));
return sum;
}
一种实现方式是基于数组。也就是分配一个数组,然后每个线程使用唯一的下标去访问元素。再经过 per-thread 原语(类似 uRCU 用到的实现,同样是作者写的代码)封装后的例子如上。
基于 thread local 的实现源码
// thread local 计数器
unsigned long _Thread_local counter = 0;
// 将 thread local 暴露给读者
unsigned long *counterp[NR_THREADS] = {NULL};
// 线程退出时的累计计数
unsigned long finalcount = 0;
// 控制线程注册
DEFINE_SPINLOCK(final_mutex);
static inline void inc_count(void)
{
WRITE_ONCE(counter, counter + 1);
}
static inline unsigned long read_count(void)
{
int t;
unsigned long sum;
spin_lock(&final_mutex);
sum = finalcount;
for_each_thread(t)
if (counterp[t] != NULL)
sum += READ_ONCE(*counterp[t]);
spin_unlock(&final_mutex);
return sum;
}
void count_register_thread(unsigned long *p)
{
// smp_thread_id() 原语返回一个与发出请求的线程相对应的线程索引
// 这个索引保证小于程序启动以来存在的线程最大数量
// 因此它对于位掩码、数组索引等用途非常有用
int idx = smp_thread_id();
spin_lock(&final_mutex);
counterp[idx] = &counter;
spin_unlock(&final_mutex);
}
void count_unregister_thread(int nthreadsexpected)
{
int idx = smp_thread_id();
spin_lock(&final_mutex);
finalcount += counter;
counterp[idx] = NULL;
spin_unlock(&final_mutex);
}
另一种实现方式是基于编译器提供的 thread local 变量,它避开了数组大小对线程数的限制。
利用最终一致性的实现源码
// 写侧计数器
DEFINE_PER_THREAD(unsigned long, counter);
// 读侧计数器
unsigned long global_count;
// 用于协作中断
int stopflag;
static __inline__ void inc_count(void)
{
unsigned long *p_counter = &__get_thread_var(counter);
WRITE_ONCE(*p_counter, *p_counter + 1);
}
static __inline__ unsigned long read_count(void)
{
return READ_ONCE(global_count);
}
void *eventual(void *arg)
{
int t;
unsigned long sum;
// 只有调用 count_cleanup() 才会推动 stopflag
while (READ_ONCE(stopflag) < 3) {
sum = 0;
for_each_thread(t)
sum += READ_ONCE(per_thread(counter, t));
// 从写侧下推计数结果到读侧
WRITE_ONCE(global_count, sum);
// 定时下推,间隔 1 ms
poll(NULL, 0, 1);
if (READ_ONCE(stopflag))
smp_store_release(&stopflag, stopflag + 1);
}
return NULL;
}
void count_init(void)
{
int en;
pthread_t tid;
// 独立的下推线程
en = pthread_create(&tid, NULL, eventual, NULL);
if (en != 0) {
fprintf(stderr, "pthread_create: %s\n", strerror(en));
exit(EXIT_FAILURE);
}
}
void count_cleanup(void)
{
WRITE_ONCE(stopflag, 1);
while (smp_load_acquire(&stopflag) < 3)
poll(NULL, 0, 1);
}
还有一种实现方式是利用最终一致性来提高读侧性能。之前的实现版本是保证了返回值肯定是在 read_count() 执行前后的理想范围内,而最终一致性弱化了保证:在没有调用 inc_count() 的情况下,(随着时间的推移)read_count() 最终会返回一个准确的计数值。具体看代码注释,这需要一个独立的线程协助完成下推工作。
近似限制计数器
计数器的某些场合可以只要求近似处理。比如一个结构体分配器的已占用次数达到限制阈值后,将不再处理新的分配请求,而这个阈值是允许为粗略近似的。
一种设计思路可以是分区,但是可能不太通用。以结构体分配器为例,假设有 10 个线程,限制阈值是 10000,那么每个线程只需管理自身的 1000 个结构体占用计数。这种设计思路的问题在于难以处理分配和释放线程不一致的问题,计数要么是算入到释放线程,但是很快就会严重失衡;要么是算回到分配线程,但是需要用昂贵的原子手段。
另一种设计思路是部分分区。每线程维护 counter 计数和 counter max 阈值。通常每一次使用是增加线程私有的计数器;当线程的已占用计数到达阈值时,将把一半的计数算入到 global count 全局计数器中。这两种操作看起来前面就是快路径,后面就是慢路径。慢路径是要持有全局锁的,因为还需要做全局的重平衡操作。另外还有优化,作者引入了 global reserve 作为一个动态调整 counter max 的重平衡参数。总之要使得实现满足三个不变式:
\[\begin{align*}
global\_count + global\_reserve &\le global\_count\_max \\
\sum_{i}^{nthreads}counter\_max_i &\le global\_reserve \\
counter_i &\le counter\_max_i
\end{align*}\]
近似限制的实现源码
unsigned long __thread counter = 0;
unsigned long __thread countermax = 0;
unsigned long globalcountmax = 10000;
unsigned long globalcount = 0;
unsigned long globalreserve = 0;
unsigned long *counterp[NR_THREADS] = { NULL };
DEFINE_SPINLOCK(gblcnt_mutex);
#define MAX_COUNTERMAX 1000
static __inline__ int add_count(unsigned long delta)
{
if (counter_max - counter >= delta) {
WRITE_ONCE(counter, counter + delta);
return 1;
}
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcount_max - globalcount - global_reserve < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
globalcount += delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
static __inline__ int sub_count(unsigned long delta)
{
if (counter >= delta) {
WRITE_ONCE(counter, counter - delta);
return 1;
}
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcount < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
globalcount -= delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
static __inline__ unsigned long read_count(void)
{
int t;
unsigned long sum;
spin_lock(&gblcnt_mutex);
sum = globalcount;
for_each_thread(t) {
if (counterp[t] != NULL)
sum += READ_ONCE(*counterp[t]);
}
spin_unlock(&gblcnt_mutex);
return sum;
}
static __inline__ void globalize_count(void)
{
globalcount += counter;
counter = 0;
globalreserve -= countermax;
countermax = 0;
}
static __inline__ void balance_count(void)
{
countermax = globalcountmax -
globalcount - globalreserve;
countermax /= num_online_threads();
if (countermax > MAX_COUNTERMAX)
countermax = MAX_COUNTERMAX;
globalreserve += countermax;
counter = countermax / 2;
if (counter > globalcount)
counter = globalcount;
globalcount -= counter;
}
void count_register_thread(void)
{
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
counterp[idx] = &counter;
spin_unlock(&gblcnt_mutex);
}
void count_unregister_thread(int nthreads_expected)
{
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
globalize_count();
counterp[idx] = NULL;
spin_unlock(&gblcnt_mutex);
}
NOTES:
- counter 到达 counter max 时并非必须移入一半的 counter 数目,这是精度和扩展性的权衡。
- counter max 简单来说是等于 global reserve 除以线程数。在程序早期,配额比较充足时,可以得到更高的 counter max 数值以减少进入慢路径的可能,以提高扩展性;而在后期配额较少时,会更加高频地进入慢路径执行重平衡,以提高精度。
- 实现上的 counter 先置零再从 global count 拿回是为了简化 corner case。
精确限制计数器
作者给了两套做法:
- 原子实现,将计数和阈值高低位拆分压入到一个原子类型中。
- signal-theft,使用
signal()/kill() 免除原子操作,需要维护状态机。
原子实现源码
atomic_t __thread counterandmax = ATOMIC_INIT(0);
unsigned long globalcountmax = 1 << 25;
unsigned long globalcount = 0;
unsigned long globalreserve = 0;
atomic_t *counterp[NR_THREADS] = { NULL };
DEFINE_SPINLOCK(gblcnt_mutex);
#define CM_BITS (sizeof(atomic_t) * 4)
#define MAX_COUNTERMAX ((1 << CM_BITS) - 1)
static __inline__ void split_counterandmax_int(int cami, int *c, int *cm) {
*c = (cami >> CM_BITS) & MAX_COUNTERMAX;
*cm = cami & MAX_COUNTERMAX;
}
static __inline__ void split_counterandmax(atomic_t *cam, int *old, int *c, int *cm) {
unsigned int cami = atomic_read(cam);
*old = cami;
split_counterandmax_int(cami, c, cm);
}
static __inline__ int merge_counterandmax(int c, int cm) {
unsigned int cami = (c << CM_BITS) | cm;
return ((int)cami);
}
int add_count(unsigned long delta) {
int c, cm, old, new;
do {
split_counterandmax(&counterandmax, &old, &c, &cm);
if (delta > MAX_COUNTERMAX || c + delta > cm)
goto slowpath;
new = merge_counterandmax(c + delta, cm);
} while (atomic_cmpxchg(&counterandmax, old, new) != old);
return 1;
slowpath:
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcountmax - globalcount - globalreserve < delta) {
flush_local_count();
if (globalcountmax - globalcount - globalreserve < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
}
globalcount += delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
int sub_count(unsigned long delta) {
int c, cm, old, new;
do {
split_counterandmax(&counterandmax, &old, &c, &cm);
if (delta > c)
goto slowpath;
new = merge_counterandmax(c - delta, cm);
} while (atomic_cmpxchg(&counterandmax, old, new) != old);
return 1;
slowpath:
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcount < delta) {
flush_local_count();
if (globalcount < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
}
globalcount -= delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
unsigned long read_count(void) {
int c, cm, old, t;
unsigned long sum;
spin_lock(&gblcnt_mutex);
sum = globalcount;
for_each_thread(t) {
if (counterp[t] != NULL) {
split_counterandmax(counterp[t], &old, &c, &cm);
sum += c;
}
}
spin_unlock(&gblcnt_mutex);
return sum;
}
static void globalize_count(void) {
int c, cm, old;
split_counterandmax(&counterandmax, &old, &c, &cm);
globalcount += c;
globalreserve -= cm;
old = merge_counterandmax(0, 0);
atomic_set(&counterandmax, old);
}
static void flush_local_count(void) {
int c, cm, old, t, zero;
if (globalreserve == 0)
return;
zero = merge_counterandmax(0, 0);
for_each_thread(t)
if (counterp[t] != NULL) {
old = atomic_xchg(counterp[t], zero);
split_counterandmax_int(old, &c, &cm);
globalcount += c;
globalreserve -= cm;
}
}
static void balance_count(void) {
int c, cm, old;
unsigned long limit;
limit = globalcountmax - globalcount - globalreserve;
limit /= num_online_threads();
cm = (limit > MAX_COUNTERMAX) ? MAX_COUNTERMAX : limit;
globalreserve += cm;
c = cm / 2;
if (c > globalcount)
c = globalcount;
globalcount -= c;
old = merge_counterandmax(c, cm);
atomic_set(&counterandmax, old);
}
void count_register_thread(void) {
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
counterp[idx] = &counterandmax;
spin_unlock(&gblcnt_mutex);
}
void count_unregister_thread(int nthreadsexpected) {
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
globalize_count();
counterp[idx] = NULL;
spin_unlock(&gblcnt_mutex);
}
原子实现类似上面的近似计数器,主要是并行的 flush 和 per-thread 流程需要保证数据的原子性,以避免 counter 和 counter max 仅修改一边却被另一个线程再次改动的问题,不多讨论了。

signal-theft 实现源码
/********** 数据结构部分 **********/
#define THEFT_IDLE 0
#define THEFT_REQ 1
#define THEFT_ACK 2
#define THEFT_READY 3
// 初始状态为 IDLE
int __thread theft = THEFT_IDLE;
// 是否处于 fast path 路径当中
int __thread counting = 0;
unsigned long __thread counter = 0;
unsigned long __thread countermax = 0;
unsigned long globalcountmax = 10000;
unsigned long globalcount = 0;
unsigned long globalreserve = 0;
unsigned long *counterp[NR_THREADS] = { NULL };
unsigned long *countermaxp[NR_THREADS] = { NULL };
int *theftp[NR_THREADS] = { NULL };
DEFINE_SPINLOCK(gblcnt_mutex);
#define MAX_COUNTERMAX 100
/********** 数值迁移部分 **********/
static void globalize_count(void) {
globalcount += counter;
counter = 0;
globalreserve -= countermax;
countermax = 0;
}
// 信号例程,注册流程见 count_init()
static void flush_local_count_sig(int unused) {
// 非 REQ 状态会屏蔽信号
if (READ_ONCE(theft) != THEFT_REQ)
return;
// REQ 可以转移为 ACK 或者 READY
// 取决与 counting 位(是否在 fast path)
WRITE_ONCE(theft, THEFT_ACK);
if (!counting)
smp_store_release(&theft, THEFT_READY);
}
static void flush_local_count(void) {
int t;
thread_id_t tid;
for_each_tid(t, tid) {
if (theftp[t] != NULL) {
// 针对 no count 的特例,不需发出信号
if (*countermaxp[t] == 0) {
WRITE_ONCE(*theftp[t], THEFT_READY);
continue;
}
// 只有 REQ 状态才会处理信号,处理完成回切换到 READY 或者 ACK
// 可用于判断信号丢失或者信号延迟
WRITE_ONCE(*theftp[t], THEFT_REQ);
// 发出信号
pthread_kill(tid, SIGUSR1);
}
}
for_each_tid(t, tid) {
if (theftp[t] == NULL)
continue;
while (smp_load_acquire(theftp[t]) != THEFT_READY) {
poll(NULL, 0, 1);
// 处理可能的信号丢失
if (READ_ONCE(*theftp[t]) == THEFT_REQ)
pthread_kill(tid, SIGUSR1);
}
globalcount += *counterp[t];
*counterp[t] = 0;
globalreserve -= *countermaxp[t];
*countermaxp[t] = 0;
// 盗窃完成则回到 IDLE
smp_store_release(theftp[t], THEFT_IDLE);
}
}
// 见前面的近似计数器小节
static void balance_count(void) {
countermax = globalcountmax - globalcount - globalreserve;
countermax /= num_online_threads();
if (countermax > MAX_COUNTERMAX)
countermax = MAX_COUNTERMAX;
globalreserve += countermax;
counter = countermax / 2;
if (counter > globalcount)
counter = globalcount;
globalcount -= counter;
}
/********** 计数部分 **********/
int add_count(unsigned long delta) {
int fastpath = 0;
WRITE_ONCE(counting, 1);
// 确保信号例程的并发
barrier();
// 尚未执行信号例程(IDLE 或者 REQ 状态)才可走 fast path
if (smp_load_acquire(&theft) <= THEFT_REQ && countermax - counter >= delta) {
WRITE_ONCE(counter, counter + delta);
fastpath = 1;
}
barrier();
WRITE_ONCE(counting, 0);
barrier();
// ACK 由信号例程设置,见 flush_local_count_sig()
if (READ_ONCE(theft) == THEFT_ACK)
smp_store_release(&theft, THEFT_READY);
if (fastpath)
return 1;
// slow path 流程
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcountmax - globalcount - globalreserve < delta) {
// 发出信号且等待完成
flush_local_count();
// 如果盗窃完成了仍然超出阈值
if (globalcountmax - globalcount - globalreserve < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
}
globalcount += delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
int sub_count(unsigned long delta) {
int fastpath = 0;
WRITE_ONCE(counting, 1);
barrier();
if (smp_load_acquire(&theft) <= THEFT_REQ && counter >= delta) {
WRITE_ONCE(counter, counter - delta);
fastpath = 1;
}
barrier();
WRITE_ONCE(counting, 0);
barrier();
if (READ_ONCE(theft) == THEFT_ACK)
smp_store_release(&theft, THEFT_READY);
if (fastpath)
return 1;
spin_lock(&gblcnt_mutex);
globalize_count();
if (globalcount < delta) {
flush_local_count();
if (globalcount < delta) {
spin_unlock(&gblcnt_mutex);
return 0;
}
}
globalcount -= delta;
balance_count();
spin_unlock(&gblcnt_mutex);
return 1;
}
unsigned long read_count(void) {
int t;
unsigned long sum;
spin_lock(&gblcnt_mutex);
sum = globalcount;
for_each_thread(t) {
if (counterp[t] != NULL)
sum += READ_ONCE(*counterp[t]);
}
spin_unlock(&gblcnt_mutex);
return sum;
}
/********** 初始化部分 **********/
void count_init(void) {
struct sigaction sa;
// 信号例程注册为 flush_local_count_sig
sa.sa_handler = flush_local_count_sig;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
// 通过 SIGUSR1 信号派发,见 flush_local_count() 调用
if (sigaction(SIGUSR1, &sa, NULL) != 0) {
perror("sigaction");
exit(EXIT_FAILURE);
}
}
void count_register_thread(void) {
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
counterp[idx] = &counter;
countermaxp[idx] = &countermax;
theftp[idx] = &theft;
spin_unlock(&gblcnt_mutex);
}
void count_unregister_thread(int nthreadsexpected) {
int idx = smp_thread_id();
spin_lock(&gblcnt_mutex);
globalize_count();
counterp[idx] = NULL;
countermaxp[idx] = NULL;
theftp[idx] = NULL;
spin_unlock(&gblcnt_mutex);
}
signal-theft 版本的诀窍就是信号处理的上下文处于指定的线程本地,因此是通过信号去驱动 flush 操作。具体见代码注释和状态转移图。
Quick Quiz 8.5: What mechanisms other than POSIX signals may be used for function shipping?
Answer: There is a very large number of such mechanisms, including:
- System V message queues.
- Shared-memory dequeue.
- Shared-memory mailboxes.
- UNIX-domain sockets.
- TCP/IP or UDP, possibly augmented by any number of higher-level protocols, including RPC, HTTP, XML, SOAP, and so on.
使用其他的消息机制来替代信号也是可以的。不过个人觉得信号才是恰到好处的异步消息,因为它不需要第三方的介入。io_uring 的异步操作和协作式调度也是基于优化的信号回调机制。
分区和同步
第六章是讲得比较宽泛的介绍环节,简单过一遍。
分区示例

作者抛出一个经典的哲学家进餐问题,一种解决饥饿的办法是给叉子排号然后按规定的大小顺序取,这样总有一位可以有进展。但是从分区的角度去思考,如果我们可以将 N 个哲学家分区成 N/2 对,每一对只竞争中间的一双叉子(如上图),那么每一对里总有一个人不会饥饿,也就是 N/2 位有进展。并且不管你的哲学家规模有多大,其同步开销几乎是不变的(因为没有数据依赖),这就是分区的威力。
复合队列的实现源码
/* First do the underlying single-locked deq implementation. */
// 简单的不持锁 deque 实现
// 后面复合队列再进一步封装
struct deq {
// 双向的侵入式链表
struct cds_list_head chain;
} ____cacheline_internodealigned_in_smp;
void init_deq(struct deq *p)
{
CDS_INIT_LIST_HEAD(&p->chain);
}
struct cds_list_head *deq_pop_l(struct deq *p)
{
struct cds_list_head *e;
if (cds_list_empty(&p->chain))
e = NULL;
else {
e = p->chain.prev;
cds_list_del(e);
CDS_INIT_LIST_HEAD(e);
}
return e;
}
void deq_push_l(struct cds_list_head *e, struct deq *p)
{
cds_list_add_tail(e, &p->chain);
}
struct cds_list_head *deq_pop_r(struct deq *p)
{
struct cds_list_head *e;
if (cds_list_empty(&p->chain))
e = NULL;
else {
e = p->chain.next;
cds_list_del(e);
CDS_INIT_LIST_HEAD(e);
}
return e;
}
void deq_push_r(struct cds_list_head *e, struct deq *p)
{
cds_list_add(e, &p->chain);
}
/*
* And now the concurrent implementation, which simply has a pair
* of deq structures in tandem, feeding each other as needed.
* This of course requires some way of moving elements from one
* to the other. This implementation uses a trivial approach:
* if a pop finds one empty, pull all elements from the
* other one.
*
* Each individual deq has its own lock, with the left lock acquired
* first if both locks are required.
*/
// 复合队列的实现,前面注释也提了重平衡和防止死锁的注意点
struct pdeq {
spinlock_t llock;
struct deq ldeq;
/* char pad1[CACHE_LINE_SIZE - sizeof(spinlock_t) - sizeof(int)]; */
spinlock_t rlock ____cacheline_internodealigned_in_smp;
struct deq rdeq;
};
void init_pdeq(struct pdeq *d)
{
spin_lock_init(&d->llock);
init_deq(&d->ldeq);
spin_lock_init(&d->rlock);
init_deq(&d->rdeq);
}
struct cds_list_head *pdeq_pop_l(struct pdeq *d)
{
struct cds_list_head *e;
spin_lock(&d->llock);
e = deq_pop_l(&d->ldeq);
if (e == NULL) {
spin_lock(&d->rlock);
e = deq_pop_l(&d->rdeq);
cds_list_splice(&d->rdeq.chain, &d->ldeq.chain);
CDS_INIT_LIST_HEAD(&d->rdeq.chain);
spin_unlock(&d->rlock);
}
spin_unlock(&d->llock);
return e;
}
struct cds_list_head *pdeq_pop_r(struct pdeq *d)
{
struct cds_list_head *e;
spin_lock(&d->rlock);
e = deq_pop_r(&d->rdeq);
if (e == NULL) {
// 防止死锁的做法,固定先拿 llock 再拿 rlock
spin_unlock(&d->rlock);
spin_lock(&d->llock);
spin_lock(&d->rlock);
e = deq_pop_r(&d->rdeq);
if (e == NULL) {
e = deq_pop_r(&d->ldeq);
// 重平衡,全部拉走,这是比较直接的做法
cds_list_splice(&d->ldeq.chain, &d->rdeq.chain);
CDS_INIT_LIST_HEAD(&d->ldeq.chain);
}
spin_unlock(&d->llock);
}
spin_unlock(&d->rlock);
return e;
}
void pdeq_push_l(struct cds_list_head *e, struct pdeq *d)
{
spin_lock(&d->llock);
deq_push_l(e, &d->ldeq);
spin_unlock(&d->llock);
}
void pdeq_push_r(struct cds_list_head *e, struct pdeq *d)
{
spin_lock(&d->rlock);
deq_push_r(e, &d->rdeq);
spin_unlock(&d->rlock);
}
哈希分区的实现源码
/* First do the underlying single-locked deq implementation. */
// 与复合队列使用的 struct deq 不同,这是需要锁的
struct deq {
spinlock_t lock;
struct cds_list_head chain;
} ____cacheline_internodealigned_in_smp;
void init_deq(struct deq *p)
{
spin_lock_init(&p->lock);
CDS_INIT_LIST_HEAD(&p->chain);
}
struct cds_list_head *deq_pop_l(struct deq *p)
{
struct cds_list_head *e;
spin_lock(&p->lock);
if (cds_list_empty(&p->chain))
e = NULL;
else {
e = p->chain.prev;
cds_list_del(e);
CDS_INIT_LIST_HEAD(e);
}
spin_unlock(&p->lock);
return e;
}
void deq_push_l(struct cds_list_head *e, struct deq *p)
{
spin_lock(&p->lock);
cds_list_add_tail(e, &p->chain);
spin_unlock(&p->lock);
}
struct cds_list_head *deq_pop_r(struct deq *p)
{
struct cds_list_head *e;
spin_lock(&p->lock);
if (cds_list_empty(&p->chain))
e = NULL;
else {
e = p->chain.next;
cds_list_del(e);
CDS_INIT_LIST_HEAD(e);
}
spin_unlock(&p->lock);
return e;
}
void deq_push_r(struct cds_list_head *e, struct deq *p)
{
spin_lock(&p->lock);
cds_list_add(e, &p->chain);
spin_unlock(&p->lock);
}
/*
* And now the concurrent implementation.
*
* Pdeq structure, empty list:
*
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* | | | | | | | | | | | | | | | |
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* ^ ^
* | |
* lidx ridx
*
*
* List after three pdeq_push_l() invocations of "a", "b", and "c":
*
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* | | | | | c | b | a | | | | | | | | |
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* ^ ^
* | |
* lidx ridx
*
* List after one pdeq_pop_r() invocations (removing "a"):
*
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* | | | | | c | b | | | | | | | | | |
* +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
* ^ ^
* | |
* lidx ridx
*
* This is pretty standard. The trick is that only the low-order bits
* of lidx and ridx are used to index into a power-of-two sized hash
* table. Each bucket of the hash table is a circular doubly linked
* list (AKA liburcu cds_list_head structure). Left-hand operations
* manipulate the tail of the selected list, while right-hand operations
* manipulate the head of the selected list. Each bucket has its own
* lock, minimizing lock contention. Each of the two indexes also has
* its own lock.
*/
/*
* This must be a power of two. If you want something else, also adjust
* the moveleft() and moveright() functions.
*/
#define PDEQ_N_BKTS 4
struct pdeq {
spinlock_t llock;
int lidx;
/* char pad1[CACHE_LINE_SIZE - sizeof(spinlock_t) - sizeof(int)]; */
spinlock_t rlock;
int ridx;
/* char pad2[CACHE_LINE_SIZE - sizeof(spinlock_t) - sizeof(int)]; */
// 哈希数组,每个桶都是一个基础队列
// 操作见注释图示
struct deq bkt[PDEQ_N_BKTS];
};
static int moveleft(int idx)
{
return (idx - 1) & (PDEQ_N_BKTS - 1);
}
static int moveright(int idx)
{
return (idx + 1) & (PDEQ_N_BKTS - 1);
}
void init_pdeq(struct pdeq *d)
{
int i;
d->lidx = 0;
spin_lock_init(&d->llock);
d->ridx = 1;
spin_lock_init(&d->rlock);
for (i = 0; i < PDEQ_N_BKTS; i++)
init_deq(&d->bkt[i]);
}
struct cds_list_head *pdeq_pop_l(struct pdeq *d)
{
struct cds_list_head *e;
int i;
spin_lock(&d->llock);
i = moveright(d->lidx);
// 分区意义下的 deq 锁竞争是低概率事件
e = deq_pop_l(&d->bkt[i]);
if (e != NULL)
d->lidx = i;
spin_unlock(&d->llock);
return e;
}
struct cds_list_head *pdeq_pop_r(struct pdeq *d)
{
struct cds_list_head *e;
int i;
spin_lock(&d->rlock);
i = moveleft(d->ridx);
e = deq_pop_r(&d->bkt[i]);
if (e != NULL)
d->ridx = i;
spin_unlock(&d->rlock);
return e;
}
void pdeq_push_l(struct cds_list_head *e, struct pdeq *d)
{
int i;
spin_lock(&d->llock);
i = d->lidx;
deq_push_l(e, &d->bkt[i]);
d->lidx = moveleft(d->lidx);
spin_unlock(&d->llock);
}
void pdeq_push_r(struct cds_list_head *e, struct pdeq *d)
{
int i;
spin_lock(&d->rlock);
i = d->ridx;
deq_push_r(e, &d->bkt[i]);
d->ridx = moveright(d->ridx);
spin_unlock(&d->rlock);
}
另一个示例是锁实现的双端队列。除了使用一个队列持两把锁,以及两个队列各持一把锁组成复合队列的实现方式以外,还可以通过哈希分区的实现方式去完成这件事情。第一种单队列实现是不推荐的,因为存在临界区重叠问题;第二种复合队列实现能避免重叠问题,但是方法并不通用,并且需要处理队列中的元素迁移(rebalance);第三种哈希分区则是一个简单通用的实现方式,不需处理重平衡和死锁问题。
One of the simplest and most effective ways to deterministically partition a data structure is to hash it.
NOTE: 虽然哈希分区的方式比较通用,但是论性能的话还是复合队列要更胜一筹:因为后者通常每次操作只需持锁一次,而前者必须持锁两次。
锁的粒度
介绍了一些基本的按锁分区范式:
- code lock:按代码持锁,时间分区,高同步开销。
- data lock:按数据结构持锁,时间和数据分区,高到低的同步开销。
- data ownership:数据绑定线程或者 CPU,数据分区,没有同步开销。
NOTES:
- 只看代码上锁仍适用于低频操作,因为设计简单。它可用于快速路径难以处理的场合。
- 所有权虽然没有同步开销,但是转移所有权是个问题。后面第八章对所有权做出了总结。
- 只读的所有权也是「共享」所有权,因为可以做副本。前面第三章提过这种 cache 特性。
- 数据倾斜问题(单 key/CPU 热点)不能靠这些范式解决,需要设计具体的算法。
不要小看这里的讨论,个人补充一点见解。我们常见的 code lock 其实还是使用 data lock 来完成,只不过可能会隐藏在某个单一的、全局互斥的锁。但是 RCU 机制是不需要持有任何外部数据结构就能完成 code lock 的作用,即提供临界区。也就是说一个「无状态」的 rcu_read_lock() 就能替代 code_lock(data->lock),后面的章节还会告诉你这个临界区其实是 lockless 的形式,既不需要花费内存占用来提供锁结构体,也不需要花费 CPU 开销来真的「持锁」,因为它可以做到空实现。那么代价是什么?且听下回分解。
快速路径
快速路径是个简化设计并且保证高扩展的好思路,比较常见的快速路径有:
- 读写锁。经典的非对称设计,前面有讨论过它的临界区问题,后面还会讨论抗饥饿和读写改进。
- RCU。高性能场景下的读写锁替代品。
- 层级锁。将一把又大又长(粒度和占用时间)的锁替换成多把(逐层变细并降低持大锁时间)。
- 分配器缓存。
分配器缓存实现源码
/* Allocator-Cache Data Structures */
#define TARGET_POOL_SIZE 3
#define GLOBAL_POOL_SIZE 40
struct globalmempool {
spinlock_t mutex;
int cur;
struct memblock *pool[GLOBAL_POOL_SIZE];
} globalmem;
struct perthreadmempool {
int cur;
// 常数 2 是批处理阈值,具体看 free 操作
struct memblock *pool[2 * TARGET_POOL_SIZE];
};
DEFINE_PER_THREAD(struct perthreadmempool, perthreadmem);
/* Allocator-Cache Allocator Function */
struct memblock *memblock_alloc(void)
{
int i;
struct memblock *p;
struct perthreadmempool *pcpp;
pcpp = &__get_thread_var(perthreadmem);
if (pcpp->cur < 0) {
spin_lock(&globalmem.mutex);
for (i = 0; i < TARGET_POOL_SIZE && globalmem.cur >= 0; i++) {
pcpp->pool[i] = globalmem.pool[globalmem.cur];
globalmem.pool[globalmem.cur--] = NULL;
}
pcpp->cur = i - 1;
spin_unlock(&globalmem.mutex);
}
if (pcpp->cur >= 0) {
p = pcpp->pool[pcpp->cur];
pcpp->pool[pcpp->cur--] = NULL;
return p;
}
return NULL;
}
/* Allocator-Cache Free Function */
void memblock_free(struct memblock *p)
{
int i;
struct perthreadmempool *pcpp;
pcpp = &__get_thread_var(perthreadmem);
if (pcpp->cur >= 2 * TARGET_POOL_SIZE - 1) {
spin_lock(&globalmem.mutex);
for (i = pcpp->cur; i >= TARGET_POOL_SIZE; i--) {
globalmem.pool[++globalmem.cur] = pcpp->pool[i];
pcpp->pool[i] = NULL;
}
pcpp->cur = i;
spin_unlock(&globalmem.mutex);
}
pcpp->pool[++pcpp->cur] = p;
}
(内存)分配器缓存是常见的分配器设计技巧。一个直接思路是分区,也就是用所有权把内存均等隔离到每个 CPU 上。但是问题在于生产者-消费者模型(一些 CPU 只负责分配,另一些 CPU 只负责释放)会使得分配器不可用。因此一个改进思路是慢速路径做批处理加上全局大锁的组合设计,实现从全局内存池的推拉工作(也就是到达一定阈值后需要转移所有权)。但是快速路径仍然保留了所有权的思路,使得常规分配和释放足够快。
锁
第七章介绍了锁的潜在问题和优化实现。
死锁问题
极端示例:死锁可发生在单线程单锁的情况下,比如自己锁自己的锁再锁自己的锁。
非侵入式的死锁检测算法就是判断关系图是否违反了有向无环图,Lock 和 Thread 作为顶点,Lock-to-Thread 的边表示已持锁,Thread-to-Lock 的边表示等待锁,形成任意环就意味着存在死锁,记得 facebook.folly 使用这个原理实现过一个 gdb 脚本;侵入式的死锁检测算法可以了解 Linux 内核的 lockdep 机制,可惜文档没把具体的实现说清楚,只提到检查状态和依赖。
死锁避免的方式非常多:
- 锁的层级。给每个锁编号,持锁方在持有一定的锁时,下一把锁必须按照顺序取。比如持有了 2 号锁和 4 号锁,就不得再尝试持有 3 号锁。对于不同类型的锁,需要按实际用途考虑清楚编号顺序;而对于相同类型的锁,一个简单策略是直接按照地址顺序排序。在大型系统中依赖人工并不可靠,需要引入工具,比如 lockdep 是强制实行这种层级策略。
- 锁的本地层级。一个问题是外部库和锁的管理,因为库实现不知道用户持有了什么锁(反过来也一样)。一种做法是库实现不调用用户定义的函数(回调)。另一种做法是调用用户定义函数前先释放所有的锁。
- 锁的分级层级。给上面的问题再加补丁,因为直接释放锁不现实,改成获取新的锁(再释放旧的冲突锁)。作者提到这种做法可以任意扩展分级,但是属于破坏原有设计。
- 锁的临时层级。也就是延迟获取锁的时机,思路可参考 RCU 的宽限期。
- 避免指向锁的指针。通常暴露锁的指针是一种错误设计,除了一些用于扩展临界区以避免无谓唤醒的特例(让我想起了 C++ 的 unique_lock 封装,可以移动它并暴露到外部以避免过早的 RAII;作者提了一个 pthread_cond_wait 也必须要传递指针)。所以见到锁的指针都要特别注意。
- 条件锁。在不适用层级的设计中(很复杂的拓扑关系?),可以用 trylock 的设计替代 lock。
- 先获取所有锁。把双方交织持锁的现象给禁止了。这种做法如果暂时无法满足,就释放锁并重试。
- 单锁设计。字面意思,没有嵌套的可能性。这里不仅指全局大锁,还可以指分区良好的细锁。
- 避免信号和中断。注意信号也可能会持锁,因此用户可以在持锁前先屏蔽信号,中断同理。
注意条件锁可能会引起活锁问题,可以用一些(睡眠等待的)退避算法来打补丁。
锁的种类
这一小节简单讨论互斥锁、读写锁(多角色锁)和作用域锁的一些日常话题。
即使是互斥锁,也需要考虑不同策略:
- Strict FIFO
- Approximate FIFO
- FIFO within priority level
- Random
- Unfair
越是强序的保证越是高成本,那么该怎么选?有些硬性要求是要满足的,比如实时系统总得提供同优先级下的 FIFO 顺序。其它的看选择,如果要想避开争用,完全不考虑公平性(忍受较长时间的饥饿)也是可选的。后面章节提到的(Linux 使用过的)ticket lock 是选择了 strict FIFO,因为设计背景就是为了在高争用时保持公平性。
还有读写锁的再次讨论。虽然这本书已经鞭尸过读写锁很多遍了,但是还是提到了饥饿问题,到底要读者饥饿还是写者饥饿,总得要选择。这里的技术选型也可参考 IO 调度器的设计,比如结合批处理让读者写者按比例轮流饥饿(这不就是 deadline 调度?),总之没有唯一的答案。顺便还介绍了类似读写锁思路的 VAX/VMS 分布式锁,可以更加精细地控制并发读和并发写的行为(也就是权限管理)。不过协议开销估计会……?客气点的说法是分布式不谈单机开销。另外,Linux 提供了读写锁的改进实现:顺序锁(sequence lock),它允许单写多读的并行,这一部分会留到延迟处理章节再做介绍。
最后提到作用域锁,也就是 C++ 的 RAII 锁封装。作者提到 lock_guard 这种作用域结束就解锁的做法(strict RAII)在日用时可以避免小错误,但是可能与层级锁的需求是冲突的,甚至对于基本的迭代器遍历上锁都是不友好的。除非使用改良的 unique_lock,但是(个人觉得)内部实现使用的控制位在这种场合又可能是多余的。总之半自动挡是不讨好的。
锁的实现
TAS lock 实现源码
typedef int xchglock_t;
#define DEFINE_XCHG_LOCK(n) xchglock_t n = 0
void xchg_lock(xchglock_t *xp)
{
while (xchg(xp, 1) == 1) {
// 避免多次 full barrier 造成 cacheline bouncing
while (READ_ONCE(*xp) == 1)
continue;
}
}
void xchg_unlock(xchglock_t *xp)
{
// 暗示 full barrier,避免临界区的执行越过该函数
// 也可使用 smp_mb() + WRITE_ONCE() 替代
(void)xchg(xp, 0);
}
上面是一个简单的通过原子操作完成的 TAS (test-and-set) lock 实现,即使是工业级的自旋锁也是类似的操作。这种实现在低争用时表现良好,并且有内存体积小的优势。代码注释也标记了需要考虑的点:乱序执行和乒乓效应。
其它基于原子操作实现的锁有很多,主要是看场合。
ticket lock 实现源码
/* 从 Linux 内核 v3.4 截获的代码,有部分精简 */
// spinlock 拆分为 head 和 tail 两部分
typedef struct arch_spinlock {
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
} arch_spinlock_t;
/*
* Ticket locks are conceptually two parts, one indicating the current head of
* the queue, and the other indicating the current tail. The lock is acquired
* by atomically noting the tail and incrementing it by one (thus adding
* ourself to the queue and noting our position), then waiting until the head
* becomes equal to the the initial value of the tail.
*
* We use an xadd covering *both* parts of the lock, to increment the tail and
* also load the position of the head, which takes care of memory ordering
* issues and should be optimal for the uncontended case. Note the tail must be
* in the high part, because a wide xadd increment of the low part would carry
* up and contaminate the high part.
*/
void __ticket_spin_lock(arch_spinlock_t *lock)
{
register struct __raw_tickets inc = { .tail = 1 };
// 「总号数」(tail)原子自增一,并得到自己的「号」(head)
// 这里 xadd 同时处理了 tail 更新 和 head 获取
inc = xadd(&lock->tickets, inc);
// 在 head 处自旋,直到「叫号」
for (;;) {
if (inc.head == inc.tail)
break;
cpu_relax();
inc.head = ACCESS_ONCE(lock->tickets.head);
}
barrier();
}
void __ticket_spin_unlock(arch_spinlock_t *lock)
{
// head 原子自增一,表示可以下一位
__add(&lock->tickets.head, 1, UNLOCK_LOCK_PREFIX);
}
比如上面的做法在高争用时(因不考虑公平性)会造成饥饿,所以内核提供了 ticket lock 实现解决这个问题(类似排号系统)。但是这种锁也有问题,它为了公平甚至能把锁交给当前不能用(被抢占或中断)的线程,不过作者说也不用太纠结这种问题。(现在用不了过一会就能用?不太确定表意)
MCS lock 实现源码
/* 从 Linux 内核 v6.4 截获的代码,有部分精简 */
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
};
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *prev;
node->locked = 0;
node->next = NULL;
// 原子更新 *lock = node
// 这里也暗示了 full barrier,避免前面的初始化操作乱序
prev = xchg(lock, node);
if (likely(prev == NULL)) {
// 快速路径,甚至连 locked = 1 都不需要设置
// 具体见 unlock 操作
return;
}
// node 实际被连接到最后面,因此也可以满足 FIFO 的要求
WRITE_ONCE(prev->next, node);
// 在本地的 node->locked 字段上自旋,直到设为 1
arch_mcs_spin_lock_contended(&node->locked);
}
void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *next = READ_ONCE(node->next);
// 快速路径,表示当前无争用
if (likely(!next)) {
// 设置 *lock 为 NULL 即可表示释放锁
if (likely(cmpxchg_release(lock, node, NULL) == node))
return;
// 如果上面的操作失败,那就说明在 if 和 cmpxchg 之间有新的 lock() 请求
// (这种情况因为 *lock 的变动而被检测出来,具体见上面的 lock 操作)
// 也就是说 node 后续有新的节点产生,需要更新 next 以复用下面的自旋操作
while (!(next = READ_ONCE(node->next)))
cpu_relax();
}
// 给 next->locked 设为 1
// 所谓的解锁甚至不需考虑当前 node->locked 字段
arch_mcs_spin_unlock_contended(&next->locked);
}
另一个角度是性能,不管是 TAS lock 还是 ticket lock,它们的共同点都是在单个内存地址上做更新(自旋)。低争用时,这种更新依然可通过硬件回写实现的,所以 cacheline 还能停留在本地注;而高争用时 cacheline 大概率是被清掉了,这就是争用上来就掉性能的原因。所以这又怎么了?这提示了 Linux 内核的 MCS lock 的实现。MCS lock 的诀窍是只在本地 CPU 变量上自旋,而自旋结构体会通过链表的方式连接起来(这点非常巧妙,只有链表中相邻的 CPU 才能彼此竞争),所以在极端情况也只有 2 个 CPU 在竞争同一个地址。具体看代码注释。
NOTE:「cacheline 还能停留在本地」原文是 The corresponding cache line is very likely still local to and writeable by the thread holding the lock。个人猜测作者进一步的意思是当没别人争用这个 cacheline 时可以靠异步回写操作慢慢来(MESI 协议的 writeback message,主存是必须写进去的,但是对端 cacheline 也允许广播写入,这是个可选项),但是有人争用(需要最新消息!)就得立刻同步刷新了(read invalidate message 或者 read message,前者是写操作或者 RMW 发出的,不仅刷新对方还要刷走自己)。凭印象写的,还没对照资料,要是写错了请羞辱我。
进一步的改进点可以是内存占用。MCS lock 的结构体大小比 ticket lock 大了两倍不止,因此还在 MCS lock 的基础上做了 qspinlock 改进。实现原理类似,但是把存储地址改为了存储 CPU 编号,从而压缩至四字节。
最后作者提到:使用非原子操作也可以实现锁!不过目前这种技巧在生产上的实践比较少。
数据的所有权
第八章可以跳过了,因为内容说得比较少,相关的技巧可以从前面的章节中总结得出:
- 数据完全私有。也就是不需要同步,例子可参考分区和同步一章。
- 数据部分共享。例子见 per-thread 计数器:跨线程的数据只读不写。
- 数据间接共享。例子见 signal-theft 计数器:通过信号或其他消息机制来协助收割数据。
- 数据只能被指定的线程访问。解释比较麻烦,总之最终一致性计数器的下推线程是一个例子。
- 数据从共享转为私有。作者提的例子有点抽象,个人觉得以分配器的批处理为例更好理解一些。
延迟处理
早期 BSD 路由表的实现
struct route_entry {
struct cds_list_head re_next;
unsigned long addr;
unsigned long iface;
};
CDS_LIST_HEAD(route_list);
unsigned long route_lookup(unsigned long addr)
{
struct route_entry *rep;
unsigned long ret;
cds_list_for_each_entry(rep, &route_list, re_next) {
if (rep->addr == addr) {
ret = rep->iface;
return ret;
}
}
return ULONG_MAX;
}
int route_add(unsigned long addr, unsigned long interface)
{
struct route_entry *rep;
rep = malloc(sizeof(*rep));
if (!rep)
return -ENOMEM;
rep->addr = addr;
rep->iface = interface;
cds_list_add(&rep->re_next, &route_list);
return 0;
}
int route_del(unsigned long addr)
{
struct route_entry *rep;
cds_list_for_each_entry(rep, &route_list, re_next) {
if (rep->addr == addr) {
cds_list_del(&rep->re_next);
free(rep);
return 0;
}
}
return -ENOENT;
}
第九章比较硬核,介绍延迟处理技术:引用计数、风险指针、顺序锁和 RCU。并且使用这些技术给 BSD 路由表提供并行支持。路由表的实现非常简单,就是添加、删除和按照地址查找接口。
另外由于 RCU 的细节比较多,还是单独从延迟处理一章中分离出来。
引用计数
基于引用计数的路由表实现(有问题)
struct route_entry {
// 多了一个引用计数字段
atomic_t re_refcnt;
struct route_entry *re_next;
unsigned long addr;
unsigned long iface;
// 检测 use-after-free 标记
int re_freed;
};
struct route_entry route_list;
DEFINE_SPINLOCK(routelock);
static void re_free(struct route_entry *rep)
{
// 这是用来检测是否执行过 free 的标记
WRITE_ONCE(rep->re_freed, 1);
// 不应该真的 free(),因为 rep->re_freed 不能被释放
// 在这里只是作为一个实现参考,具体可以翻邮件列表的讨论
// 不过那里的话题已经聊到大气层去了,不贴地址了
free(rep);
}
unsigned long route_lookup(unsigned long addr)
{
int old;
int new_val;
struct route_entry *rep;
struct route_entry **repp;
unsigned long ret;
retry:
repp = &route_list.re_next;
rep = NULL;
do {
// 减少前一位路由项的引用计数
// 如果引用计数减为 0,则释放 rep
if (rep && atomic_dec_and_test(&rep->re_refcnt)) {
re_free(rep);
}
rep = READ_ONCE(*repp);
if (rep == NULL) {
return ULONG_MAX;
}
do {
// 检查这个程序是否有问题(确实有问题)
if (READ_ONCE(rep->re_freed)) {
abort();
}
old = atomic_read(&rep->re_refcnt);
if (old <= 0) {
goto retry;
}
new_val = old + 1;
// 引用计数增加
} while (atomic_cmpxchg(&rep->re_refcnt, old, new_val) != old);
// 前进一位,这里有引用计数,按理说不应该解引用会失败
// 前进后,回到上面的 do-while 头部,减去引用计数
repp = &rep->re_next;
} while (rep->addr != addr);
ret = rep->iface;
if (atomic_dec_and_test(&rep->re_refcnt)) {
re_free(rep);
}
return ret;
}
int route_add(unsigned long addr, unsigned long interface)
{
struct route_entry *rep;
rep = malloc(sizeof(*rep));
if (!rep)
return -ENOMEM;
// 添加时引用计数初始化为 1
atomic_set(&rep->re_refcnt, 1);
rep->addr = addr;
rep->iface = interface;
spin_lock(&routelock);
rep->re_next = route_list.re_next;
rep->re_freed = 0;
route_list.re_next = rep;
spin_unlock(&routelock);
return 0;
}
int route_del(unsigned long addr)
{
struct route_entry *rep;
struct route_entry **repp;
spin_lock(&routelock);
repp = &route_list.re_next;
for (;;) {
rep = *repp;
if (rep == NULL)
break;
if (rep->addr == addr) {
*repp = rep->re_next;
spin_unlock(&routelock);
if (atomic_dec_and_test(&rep->re_refcnt)) {
re_free(rep);
}
return 0;
}
repp = &rep->re_next;
}
spin_unlock(&routelock);
return -ENOENT;
}
引用计数的思路和实现都比较简单,直接看代码就好。总之想表达的意思是:只要我在确保执行下一步前通过 CAS 获得新的引用计数,那就能确保路由表查询过程中不会解引用失败。
但是只要多线程执行 lookup 和 delete 就会曝出 use-after-free 问题,因为获取指针和增加引用两个操作并非原子。例子:线程 A 在 lookup 获取了 rep,然后被调度器拉走;线程 B 在 del 处理同一地址的 rep(引用计数为 1,减到 0 被回收);线程 A 被调度器唤起,访问 rep->...,解引用失败。
 注意地板藏着一条直线(没想到吧)
注意地板藏着一条直线(没想到吧)
另外作者还指出了引用计数的性能问题(垫底😓),原因就在于原子操作,已经提过很多次了。
场景的选择:想要安全的回收,可以考虑风险指针;想要更合理的性能,可以考虑顺序锁;想全部都要,可以考虑 RCU。不过我个人还是留有疑问,既然引用计数被贬低到这种程度,那为什么 Linux 的文件操作还是基于引用计数?
UPDATE: 破案了,fget/fput 不仅基于引用计数,还使用 RCU。
风险指针
风险指针的实现源码
/********** record 和 clear **********/
// record:将 *p 记录到风险指针
static inline void *_h_t_r_impl(void **p, hazard_pointer *hp)
{
void *tmp;
tmp = READ_ONCE(*p);
if (!tmp || tmp == (void *)HAZPTR_POISON)
return tmp;
WRITE_ONCE(hp->p, tmp);
smp_mb();
// 保证 *p 和 hp->p 的一致性,当前无法保证就返回 HAZPTR_POISON
// 这是非原子的情况下保证一致性的一种手段(重试解决一切问题)
if (tmp == READ_ONCE(*p))
return tmp;
// 表示未达成一致或者已删除
return (void *)HAZPTR_POISON;
}
#define hp_try_record(p, hp) _h_t_r_impl((void **)(p), hp)
// record 的忙循环版本
static inline void *hp_record(void **p, hazard_pointer *hp)
{
void *tmp;
do {
tmp = hp_try_record(p, hp);
} while (tmp == (void *)HAZPTR_POISON);
return tmp;
}
// clear:清理风险指针
static inline void hp_clear(hazard_pointer *hp)
{
smp_mb();
WRITE_ONCE(hp->p, NULL);
}
/********** scan 和 free **********/
// 用于二分查找加速 scan 阶段,你也可以不使用二分
int compare(const void *a, const void *b)
{
return (*(hazptr_head_t **)a - *(hazptr_head_t **)b);
}
void hazptr_scan()
{
hazptr_head_t *cur;
int i;
hazptr_head_t *tmplist;
hazptr_head_t **plist = gplist;
unsigned long psize;
// 动态 plist 初始化
if (plist == NULL) {
// 这里的大写字母应该是从论文拿过来的命名
// K:per-thread 需要的风险指针个数
psize = sizeof(hazptr_head_t *) * K * NR_THREADS;
// pointer list:存放风险指针的链表
plist = (hazptr_head_t **)malloc(psize);
BUG_ON(!plist);
gplist = plist;
}
smp_mb();
psize = 0;
// H:全局的风险指针个数
// 扫描所有线程的风险指针
for (i = 0; i < H; i++) {
// 书里缺少 HP[] 初始化了,应该是所有线程的所有风险指针都连到 HP 上(只读所有权)
uintptr_t hp = (uintptr_t)READ_ONCE(HP[i].p);
if (!hp)
continue;
plist[psize++] = (hazptr_head_t *)(hp & ~0x1UL);
}
// 确保初始化不会乱序
smp_mb();
// 按地址排序,用于后续二分查找
qsort(plist, psize, sizeof(hazptr_head_t *), compare);
// rlist:表示 retire list,要(延迟)回收的指针存放在此
tmplist = rlist;
rlist = NULL;
rcount = 0;
while (tmplist != NULL) {
cur = tmplist;
tmplist = tmplist->next;
// 如果当前指针存放于任意风险指针当中,则放回到 retire list,下次再处理
if (bsearch(&cur, plist, psize, sizeof(hazptr_head_t *), compare)) {
cur->next = rlist;
rlist = cur;
rcount++;
// 没有风险指针在指涉,you are free to free()
} else {
// 书里没给出实现,但至少在 free() 前还要处理 container_of
hazptr_free(cur);
}
}
}
// 回收请求,会缓存退役结点,确保在合适安全的时机再真正回收
void hazptr_free_later(hazptr_head_t *n)
{
// 侵入式结点 n 放入到 retire list 中
n->next = rlist;
rlist = n;
rcount++;
// 批处理,攒满后执行 scan 操作
if (rcount >= R) {
hazptr_scan();
}
}
风险指针(hazard pointer)是一种 SMR(安全内存回收)技术,可以直接解决上面引用计数的回收问题。其实我个人觉得风险指针就是一个不计数的引用计数。
实现有点复杂,但是思路很简单:
- 只要我确保自己访问数据没有风险,那肯定可以安全回收。
- 怎样才算没有风险?那自然是没别人在使用它(没有风险指针指涉它)。
- 怎样才知道没有使用?扫描所有线程的风险指针,没问题就真的回收。
- 什么时候扫描?当你发出回收请求时,这可能是批处理过程而不会立刻处理。
- 回收检测到风险怎么办?缓存退役结点并延迟回收,下次扫描再处理。
基于风险指针的路由表实现
struct route_entry {
struct hazptr_head hh;
struct route_entry *re_next;
unsigned long addr;
unsigned long iface;
int re_freed;
};
struct route_entry route_list;
DEFINE_SPINLOCK(routelock);
// per-thread 的风险指针(数组,但是这里实现固定为单个元素)
hazard_pointer __thread *my_hazptr;
unsigned long route_lookup(unsigned long addr)
{
// 这里 offset 固定为 0,就是 record 用到的风险指针数组下标
int offset = 0;
struct route_entry *rep;
struct route_entry **repp;
retry:
repp = &route_list.re_next;
do {
// (try) record 请求存放到风险指针提供保护
// 重复的 record 会覆盖掉当前线程、相同 offset 的上一次保护
// 所以后面没有用到 clear
//
// 作者提醒的关键点:
// * 不要使用 record,隐藏的忙循环会死得很惨
// * 应该使用 try record,并且失败时要完全重新遍历
rep = hp_try_record(repp, &my_hazptr[offset]);
if (!rep)
return ULONG_MAX;
if ((uintptr_t)rep == HAZPTR_POISON)
goto retry;
// cool,这下访问没问题了
repp = &rep->re_next;
} while (rep->addr != addr);
if (READ_ONCE(rep->re_freed))
abort();
return rep->iface;
}
int route_add(unsigned long addr, unsigned long interface)
{
struct route_entry *rep;
rep = malloc(sizeof(*rep));
if (!rep)
return -ENOMEM;
rep->addr = addr;
rep->iface = interface;
rep->re_freed = 0;
spin_lock(&routelock);
rep->re_next = route_list.re_next;
route_list.re_next = rep;
spin_unlock(&routelock);
return 0;
}
int route_del(unsigned long addr)
{
struct route_entry *rep;
struct route_entry **repp;
spin_lock(&routelock);
repp = &route_list.re_next;
for (;;) {
rep = *repp;
if (rep == NULL)
break;
if (rep->addr == addr) {
*repp = rep->re_next;
rep->re_next = (struct route_entry *)HAZPTR_POISON;
spin_unlock(&routelock);
// 回收请求
hazptr_free_later(&rep->hh);
return 0;
}
repp = &rep->re_next;
}
spin_unlock(&routelock);
return -ENOENT;
}
所以要在临界区的前面施放 record 以确保不会被回收,后面完全不需要风险指针保护再施放 clear。
需要注意作者提到的一个惯用法:使用 try record 而非 record 版本,并且当失败时,直接从头遍历。这涉及到正确性。假如上面的路由表实现 lookup 内部从 try record 改为了 record,当线程 A 访问了 rep 时,线程 B 删除了 rep->re_next 并重设为 HAZPTR_POISON(这里 rep 已有风险指针保护,但是 rep->re_next 没有风险指针保护,立刻回收也是安全合理的),因此线程 A 在遍历下一个元素 rep = rep->re_next = HAZPTR_POISON 时再使用 record(HAZPTR_POISON) 会导致无限循环。结论是:风险指针只保护了数据的回收,但是不关心数据的修改。觉得复杂就记住上面的惯用法。
NOTE: 在 facebook.folly 的风险指针实现中,用到的术语会有所不同:record = protect,clear = reset_hazard(nullptr),free_later = retire。folly 的实现版本由风险指针的发明者维护。
顺序锁
顺序锁(sequence lock)类似读写锁,但是可以保证单个写者和多个读者并行处理。
顺序锁的实现源码
typedef struct {
unsigned long seq;
spinlock_t lock;
} seqlock_t;
static inline void seqlock_init(seqlock_t *slp)
{
slp->seq = 0;
spin_lock_init(&slp->lock);
}
static inline unsigned long read_seqbegin(seqlock_t *slp)
{
unsigned long s;
s = READ_ONCE(slp->seq);
smp_mb();
// 做了点小优化,后续 seqretry 不需每次区分奇偶判断
return s & ~0x1UL;
}
static inline int read_seqretry(seqlock_t *slp, unsigned long oldseq)
{
unsigned long s;
smp_mb();
s = READ_ONCE(slp->seq);
return s != oldseq;
}
static inline void write_seqlock(seqlock_t *slp)
{
spin_lock(&slp->lock);
++slp->seq;
smp_mb();
}
static inline void write_sequnlock(seqlock_t *slp)
{
smp_mb();
++slp->seq;
spin_unlock(&slp->lock);
}
思路很简单,初给定一个偶数序列号,更新过程中 +1 设为奇数,更新完成再 +1 设回不同的偶数。读者在读操作时获取序列号快照并对比,如果存在任意奇数或者两个不同的偶数,那说明当前处于读不一致的状态(并发更新中),需要丢弃读结果和再次重试。
NOTES:
- 顺序锁需要 spinlock 用于支持多写者的互斥。
- 个人觉得 sequence lock 应该翻译为序列锁而不是顺序锁,因为序列指的是它的实现,跟顺序又没啥关系。但是民间翻译早就形成习惯了。
虽然读写锁写时需要排斥读,但是顺序锁也是读了就得抛弃,那为什么这么做?个人认为:
- 写者至少不会饥饿。尤其这种锁的场合本身是数量上严重倾斜到读者,必须处理写饥饿。
- 读者可以偷鸡(投机)。写会造成 cache miss 没错,但是不一定所有的数据都会 cache miss。假设前一次偷鸡成功,只有 20% cache miss,那下一次重试就能劲省 80% 的访存同步成本。
基于顺序锁的路由表实现(有问题)
struct route_entry {
struct route_entry *re_next;
unsigned long addr;
unsigned long iface;
int re_freed;
};
struct route_entry route_list;
DEFINE_SEQ_LOCK(sl);
unsigned long route_lookup(unsigned long addr)
{
struct route_entry *rep;
struct route_entry **repp;
unsigned long ret;
unsigned long s;
retry:
s = read_seqbegin(&sl);
repp = &route_list.re_next;
do {
rep = READ_ONCE(*repp);
if (rep == NULL) {
if (read_seqretry(&sl, s))
goto retry;
return ULONG_MAX;
}
// 还是老问题,没有原子地判断非空且访问字段
repp = &rep->re_next;
} while (rep->addr != addr);
if (READ_ONCE(rep->re_freed))
abort();
ret = rep->iface;
if (read_seqretry(&sl, s))
goto retry;
return ret;
}
int route_add(unsigned long addr, unsigned long interface)
{
struct route_entry *rep;
rep = malloc(sizeof(*rep));
if (!rep)
return -ENOMEM;
rep->addr = addr;
rep->iface = interface;
rep->re_freed = 0;
write_seqlock(&sl);
rep->re_next = route_list.re_next;
route_list.re_next = rep;
write_sequnlock(&sl);
return 0;
}
int route_del(unsigned long addr)
{
struct route_entry *rep;
struct route_entry **repp;
write_seqlock(&sl);
repp = &route_list.re_next;
for (;;) {
rep = *repp;
if (rep == NULL)
break;
if (rep->addr == addr) {
*repp = rep->re_next;
write_sequnlock(&sl);
smp_mb();
rep->re_freed = 1;
free(rep);
return 0;
}
repp = &rep->re_next;
}
write_sequnlock(&sl);
return -ENOENT;
}
需要注意的是,偷鸡要先确保鸡是存在的,如果写者并行地把鸡给 free 掉,那就会偷鸡不成蚀把米,造成解引用失败。也就是说,顺序锁依然是非安全的内存回收,上面的路由表实现存在着和引用计数相同的问题。
如果不考虑安全内存回收,顺序锁的扩展性优于风险指针,风险指针的扩展性优于引用计数。
RCU
由于 paul 大神就是 RCU 的发明者,所以……这一节的篇幅特别长,只节选我还能看得懂的部分。
RCU(Read-Copy Update)不仅能提供安全内存回收的能力,还能做到读写并行。对比风险指针,RCU 在实现安全内存回收的同时,避免了读侧额外的写入操作和条件分支;对比顺序锁,RCU 改用了类似多版本号的机制,以提供无需失败重试的读写并行。
发布订阅
| 插入操作
| 删除操作
|

|

|
RCU 的多版本号机制通过数据拷贝和间接寻址完成。数据拷贝保证了读侧不一致时旧版本仍可安全访问(存在担保);间接寻址可为大于机器字长的数据结构提供原子性的更新操作(切换指针)。多版本号也可理解为对版本的发布和订阅,写侧通过 rcu_assign_pointer() 发布新的指针版本,读侧通过 rcu_dereference() 订阅某一指针版本。
NOTES:
- 关于发布:
rcu_assign_pointer() 的一种实现方式是 smp_store_release(),如上图所示。如果数据结构不需要分配和初始化(比如 NULL),那么可以使用 WRITE_ONCE()。
- 关于订阅:
rcu_dereference() 通常是 READ_ONCE()。作者在 What is RCU? 内核文档中提到(compiles to a volatile load),书中表格 9.3 也有总结,这取决于体系结构的乱序程度。
- 关于读写并行:RCU 的多写并行需要自行处理同步,但是如果把「写」操作细化为更新(发布)和回收,那么唯独更新并行需要自行处理同步。
QSBR

RCU 的安全内存回收可以使用 QSBR 算法(Quiescent-State-Based Reclamation)。RCU-QSBR 引入了静默状态(quiescent state)和宽限期(grace period)两个概念,静默状态表示 CPU 不再访问数据,宽限期表示内存延迟回收的周期。同时,读者具有临界区:其范围由 rcu_read_lock() 到 rcu_read_unlock() 界定,并且内部是禁止抢占的。从临界区的角度来看,上下文切换是一种静默状态,因为能执行切换必然是执行过 unlock;而所有读者都经历过静默状态就是一个最短的宽限期,这决定了写者的同步(synchronize_rcu())所需的等待时间,也表示可以安全地回收旧版本。除此以外,写者也可以使用异步的宽限期完成回调(call_rcu())。
简单实现
RCU 实现源码(发布和订阅)
// 如果数据无需分配和初始化,发布可以改为 WRITE_ONCE()
// 如果 CPU 是 DEC Alpha 架构,订阅需要改为 smp_load_acquire()
//
// 更多细节见书中 9.5.2.1 和 Table 9.3
// Safely update an RCU-protected pointer.
#define rcu_assign_pointer(p, v) \
({ \
smp_store_release(&(p), (v)); \
})
// Safely load an RCU-protected pointer.
#define rcu_dereference(p) \
({ \
READ_ONCE(p); \
})
RCU 实现源码(QSBR 算法)
// 简单?丐版!
void rcu_read_lock(void) {
// 非内核抢占配置不需要生成实际代码
preempt_disable();
}
void rcu_read_unlock(void) {
// 非内核抢占配置不需要生成实际代码
preempt_enable();
}
void synchronize_rcu(void) {
int cpu;
// 强制 `current` 线程在每一个 CPU 上执行自身
// 也就是在每一个 CPU 上都经历一次上下文切换
for_each_online_cpu(cpu) {
sched_setaffinity(current->pid, cpumask_of(cpu));
}
}
// 没有给出 call_rcu() 实现
// 推测是将函数指针挂入到某个链表中(需要调度器、时钟中断配合?)
RCU 风格的链表操作封装
// 参考 userspace-rcu/include/urcu/rculist.h 源码
// 都是基于发布和订阅接口做的封装
/*
* caa_container_of - Get the address of an object containing a field.
*
* @ptr: pointer to the field.
* @type: type of the object.
* @member: name of the field within the object.
*/
#define caa_container_of(ptr, type, member) \
__extension__ ({ \
const __typeof__(((type *) NULL)->member) *__ptr = (ptr); \
(type *)((char *)__ptr - offsetof(type, member)); \
})
/* Get typed element from list at a given position. */
#define cds_list_entry(ptr, type, member) caa_container_of(ptr, type, member)
/* Add new element at the head of the list. */
static inline
void cds_list_add_rcu(struct cds_list_head *newp, struct cds_list_head *head)
{
newp->next = head->next;
newp->prev = head;
head->next->prev = newp;
rcu_assign_pointer(head->next, newp);
}
/* Iterate through elements of the list. */
#define cds_list_for_each_entry_rcu(pos, head, member) \
for (pos = cds_list_entry(rcu_dereference((head)->next), __typeof__(*(pos)), member); \
&(pos)->member != (head); \
pos = cds_list_entry(rcu_dereference((pos)->member.next), __typeof__(*(pos)), member))
基于 RCU 的路由表实现
struct route_entry {
struct rcu_head rh;
struct cds_list_head re_next;
unsigned long addr;
unsigned long iface;
int re_freed;
};
CDS_LIST_HEAD(route_list);
DEFINE_SPINLOCK(routelock);
unsigned long route_lookup(unsigned long addr) {
struct route_entry *rep;
unsigned long ret;
rcu_read_lock();
cds_list_for_each_entry_rcu(rep, &route_list, re_next) {
if (rep->addr == addr) {
ret = rep->iface;
if (READ_ONCE(rep->re_freed)) {
abort();
}
rcu_read_unlock();
return ret;
}
}
rcu_read_unlock();
return ULONG_MAX;
}
int route_add(unsigned long addr, unsigned long interface) {
struct route_entry *rep;
rep = malloc(sizeof(*rep));
if (!rep)
return -ENOMEM;
rep->addr = addr;
rep->iface = interface;
rep->re_freed = 0;
spin_lock(&routelock);
cds_list_add_rcu(&rep->re_next, &route_list);
spin_unlock(&routelock);
return 0;
}
static void route_cb(struct rcu_head *rhp) {
struct route_entry *rep;
rep = container_of(rhp, struct route_entry, rh);
WRITE_ONCE(rep->re_freed, 1);
free(rep);
}
int route_del(unsigned long addr) {
struct route_entry *rep;
spin_lock(&routelock);
cds_list_for_each_entry(rep, &route_list, re_next) {
if (rep->addr == addr) {
cds_list_del_rcu(&rep->re_next);
spin_unlock(&routelock);
call_rcu(&rep->rh, route_cb);
return 0;
}
}
spin_unlock(&routelock);
return -ENOENT;
}

上图展示 RCU-QSBR 的只读负载,总之就是不讲道理的快。由于现代 CPU 和编译器的优化,甚至能做到比理论值还要快。另外图中的 RCU 是指 RCU-SIGNAL 实现,作者说 RCU-QSBR 对于用户程序可能有部分约束不好应用,RCU-SIGNAL 更符合现实意义。
NOTES:
- RCU 具有多种实现参考,也就是说 QSBR 不是唯一选择。附录 B 一口气给了 9 种实现。
- RCU read lock 并不需要真正的锁,作者提到一个简单的做法是
preempt_disable()。
- synchronize RCU 原则上只等待此前已存在的读者,特例见上方 9.8 图中的 CPU 3。
- synchronize RCU 对于多个写操作来说是可共享的,也就是能做批处理。
- (无关八卦)最近 uRCU 已经弃用 RCU-SIGNAL,不过也有平替实现。
下面是一些比较零碎的话题,主要是关于 RCU 的特性和用途,仅供消遣。
等待完成
RCU 能提供一定的 program order 支持,因为宽限期的等待完成能保证以下顺序(单个读者):
- 只要有一部分临界区比宽限期开始要早,所有临界区都比宽限期结束要早。
- 只要有一部分临界区比宽限期结束要晚,所有临界区都比宽限期开始要晚。
所以,除了安全内存回收以外,用户可以反过来利用等待完成的顺序担保来设计并行算法。

分阶段状态维护的示例源码
bool be_careful;
// 表示 common-case operations
void cco(void) {
rcu_read_lock();
if (READ_ONCE(be_careful)) {
// 对比 quickly 操作,carefully 操作可能需要额外加锁
cco_carefully();
} else {
cco_quickly();
}
rcu_read_unlock();
}
void maint(void) {
// 表示 prepare 阶段
WRITE_ONCE(be_careful, true);
synchronize_rcu();
// 表示 maintenance 阶段
do_maint();
// 表示 cleanup 阶段
synchronize_rcu();
WRITE_ONCE(be_careful, false);
}
上面的分阶段状态维护是一个例子:假如有一个通用操作(cco),但是需要支持并行且不频繁的维护操作(maint),该如何处理?一种朴素做法是为 cco 加锁,这样开销太高了。另一种做法是将 maint 阶段拆分成三部分:prepare,maintenance,cleanup。此时 maintenance 表示必然需要加锁,而另外两个阶段表示可能需要加锁。prepare 和 cleanup 阶段可以使用 synchronize RCU 和 WRITE ONCE 表示。由于规则一,此前已存在的(可能同时看到 true/false 的)cco 会在 prepare 阶段完成操作,并在后续进入 maint 阶段前都能达成一致设为 true;跳出 do_maint 后再次使用规则一,所有此前存在的 cco 会保证在 cleanup 结束前全部完成,后续会回归到 true/false 不一致的场景。
注意上面只是使用了 RCU 的等待完成特性,并不需要发布订阅。(太难了,跟不上大神的思路 orz)
一致性问题
 读者订阅与写者发布并行的遍历过程
读者订阅与写者发布并行的遍历过程
另外需要注意「幻觉」问题,比如读者在遍历过程中「看到」了未曾存在过的链表版本。作者认为这是合理的,用户使用的算法应该具有容错的能力(路由表本身就是网络容错的),如果确实无法容忍较弱的一致性,可以使用顺序锁,从而保证单个读者的临界区内有一致的视图。
简单实现(续)
这一部分快速过目附录 B 的 9 种 RCU 玩具实现,很粗略地看一遍,了解思路足够了。
RCU Based on Lock
static void rcu_read_lock(void)
{
// 虽然是读互斥的……
spin_lock(&rcu_gp_lock);
}
static void rcu_read_unlock(void)
{
spin_unlock(&rcu_gp_lock);
}
void synchronize_rcu(void)
{
// 最简单又好有道理的同步实现
spin_lock(&rcu_gp_lock);
spin_unlock(&rcu_gp_lock);
}
RCU Based on Per-Thread Lock
static void rcu_read_lock(void)
{
// 更加好的局部性
spin_lock(&__get_thread_var(rcu_gp_lock));
}
static void rcu_read_unlock(void)
{
spin_unlock(&__get_thread_var(rcu_gp_lock));
}
void synchronize_rcu(void)
{
int t;
// 读多写少,写侧可以做更加重的工作
for_each_running_thread(t) {
spin_lock(&per_thread(rcu_gp_lock, t));
spin_unlock(&per_thread(rcu_gp_lock, t));
}
}
RCU Based on Simple Counter
atomic_t rcu_refcnt;
static void rcu_read_lock(void)
{
atomic_inc(&rcu_refcnt);
// 保证临界区在原子自增后
smp_mb();
}
static void rcu_read_unlock(void)
{
// 同理,保证临界区夹在 lock 和 unlock 中间
smp_mb();
atomic_dec(&rcu_refcnt);
}
void synchronize_rcu(void)
{
smp_mb();
// 夹在 smp_mb 中间防止乱序
while (atomic_read(&rcu_refcnt) != 0) {
// 原子要靠轮询
poll(NULL, 0, 10);
}
smp_mb();
}
RCU Based on Starvation-Free Counter
DEFINE_SPINLOCK(rcu_gp_lock);
// 一对的引用计数
atomic_t rcu_refcnt[2];
// 从一对中挑选出的计数器下标
atomic_t rcu_idx;
// 每线程可嵌套
DEFINE_PER_THREAD(int, rcu_nesting);
// 私有的 rcu_idx 快照
DEFINE_PER_THREAD(int, rcu_read_idx);
static void rcu_read_lock(void)
{
int i;
int n;
// 提供嵌套临界区支持
n = __get_thread_var(rcu_nesting);
if (n == 0) {
// 见同步等待过程,下标区分 0 和 1
i = atomic_read(&rcu_idx);
// 保存快照,unlock 时使用
__get_thread_var(rcu_read_idx) = i;
// 对应下标增加引用计数一位
atomic_inc(&rcu_refcnt[i]);
}
__get_thread_var(rcu_nesting) = n + 1;
smp_mb();
}
static void rcu_read_unlock(void)
{
int i;
int n;
smp_mb();
n = __get_thread_var(rcu_nesting);
if (n == 1) {
i = __get_thread_var(rcu_read_idx);
atomic_dec(&rcu_refcnt[i]);
}
__get_thread_var(rcu_nesting) = n - 1;
}
void synchronize_rcu(void)
{
int i;
smp_mb();
// 处理多写同步
spin_lock(&rcu_gp_lock);
i = atomic_read(&rcu_idx);
// 后续读者使用的下标
atomic_set(&rcu_idx, !i);
smp_mb();
// 等待此前已存在的读者全部 unlock
// 由于不需等待新的读者(!i),且 refcnt[i] 必然是单调递减
// 所以避免同步饥饿
while (atomic_read(&rcu_refcnt[i]) != 0) {
poll(NULL, 0, 10);
}
smp_mb();
atomic_set(&rcu_idx, i);
smp_mb();
// 但是单侧等待是不足的,另一侧也需等待
// 具体见 Quick Quiz B.10,下标和自增非原子所致
// 读者得到 0 下标,但是未获取计数,写者等待 0 却没有计数,读者增加下标……
// 同理,此时仍保证单调递减
while (atomic_read(&rcu_refcnt[!i]) != 0) {
poll(NULL, 0, 10);
}
spin_unlock(&rcu_gp_lock);
smp_mb();
}
RCU Based on Scalable Counter
DEFINE_SPINLOCK(rcu_gp_lock);
// 和上例唯一的区别,引用计数是私有的
DEFINE_PER_THREAD(int [2], rcu_refcnt);
atomic_t rcu_idx;
DEFINE_PER_THREAD(int, rcu_nesting);
DEFINE_PER_THREAD(int, rcu_read_idx);
static void rcu_read_lock(void)
{
int i;
int n;
n = __get_thread_var(rcu_nesting);
if (n == 0) {
i = atomic_read(&rcu_idx);
__get_thread_var(rcu_read_idx) = i;
__get_thread_var(rcu_refcnt)[i]++;
}
__get_thread_var(rcu_nesting) = n + 1;
smp_mb();
}
static void rcu_read_unlock(void)
{
int i;
int n;
smp_mb();
n = __get_thread_var(rcu_nesting);
if (n == 1) {
i = __get_thread_var(rcu_read_idx);
__get_thread_var(rcu_refcnt)[i]--;
}
__get_thread_var(rcu_nesting) = n - 1;
}
static void flip_counter_and_wait(int i)
{
int t;
atomic_set(&rcu_idx, !i);
smp_mb();
// 缝合 Per-Thread Lock 的做法……
for_each_thread(t) {
while (per_thread(rcu_refcnt, t)[i] != 0) {
poll(NULL, 0, 10);
}
}
smp_mb();
}
void synchronize_rcu(void)
{
int i;
smp_mb();
spin_lock(&rcu_gp_lock);
i = atomic_read(&rcu_idx);
// 缝合 Starvation-Free Counter 的做法……
flip_counter_and_wait(i);
flip_counter_and_wait(!i);
spin_unlock(&rcu_gp_lock);
smp_mb();
}
RCU Based on Scalable Counter (Shared Grace Periods)
DEFINE_SPINLOCK(rcu_gp_lock);
DEFINE_PER_THREAD(int [2], rcu_refcnt);
// 单调递增,足够长的下标
// 读侧只分奇偶
long rcu_idx;
DEFINE_PER_THREAD(int, rcu_nesting);
DEFINE_PER_THREAD(int, rcu_read_idx);
static void rcu_read_lock(void)
{
int i;
int n;
n = __get_thread_var(rcu_nesting);
if (n == 0) {
// 下标只用最低 1 位
i = READ_ONCE(rcu_idx) & 0x1;
__get_thread_var(rcu_read_idx) = i;
__get_thread_var(rcu_refcnt)[i]++;
}
__get_thread_var(rcu_nesting) = n + 1;
smp_mb();
}
static void rcu_read_unlock(void)
{
int i;
int n;
smp_mb();
n = __get_thread_var(rcu_nesting);
if (n == 1) {
i = __get_thread_var(rcu_read_idx);
__get_thread_var(rcu_refcnt)[i]--;
}
__get_thread_var(rcu_nesting) = n - 1;
}
static void flip_counter_and_wait(int ctr)
{
int i;
int t;
WRITE_ONCE(rcu_idx, ctr + 1);
i = ctr & 0x1;
smp_mb();
for_each_thread(t) {
while (per_thread(rcu_refcnt, t)[i] != 0) {
poll(NULL, 0, 10);
}
}
smp_mb();
}
void synchronize_rcu(void)
{
int ctr;
int oldctr;
smp_mb();
// 并发获取
oldctr = READ_ONCE(rcu_idx);
smp_mb();
// 虽然任意多个线程会竞争锁
// 但是最多只有 2 个 线程(翻 2 遍 + 翻 1 遍)在实质执行同步等待
spin_lock(&rcu_gp_lock);
// 互斥获取
ctr = READ_ONCE(rcu_idx);
// 如果其他线程已经至少翻转过 3 遍
// 则直接退出
if (ctr - oldctr >= 3) {
spin_unlock(&rcu_gp_lock);
smp_mb();
return;
}
// 单个线程最多翻转 2 遍
flip_counter_and_wait(ctr);
if (ctr - oldctr < 2)
flip_counter_and_wait(ctr + 1);
spin_unlock(&rcu_gp_lock);
smp_mb();
}
RCU Based on Free-Running Counter
DEFINE_SPINLOCK(rcu_gp_lock);
long rcu_gp_ctr = 0;
DEFINE_PER_THREAD(long, rcu_reader_gp);
DEFINE_PER_THREAD(long, rcu_reader_gp_snap);
static inline void rcu_read_lock(void)
{
// seqlock 的思路
// (私有)存入单调递增的奇数
__get_thread_var(rcu_reader_gp) = READ_ONCE(rcu_gp_ctr) + 1;
smp_mb();
}
static inline void rcu_read_unlock(void)
{
smp_mb();
__get_thread_var(rcu_reader_gp) = READ_ONCE(rcu_gp_ctr);
}
void synchronize_rcu(void)
{
int t;
smp_mb();
spin_lock(&rcu_gp_lock);
// 存入单调递增的偶数
WRITE_ONCE(rcu_gp_ctr, rcu_gp_ctr + 2);
smp_mb();
for_each_thread(t) {
// 还是奇数,表示仍在临界区内
// 小于 0,表示是此前存在的读者
while ((per_thread(rcu_reader_gp, t) & 0x1) &&
((per_thread(rcu_reader_gp, t) - rcu_gp_ctr) < 0)) {
poll(NULL, 0, 10);
}
}
spin_unlock(&rcu_gp_lock);
smp_mb();
}
RCU Based on Free-Running Counter (Nestable)
DEFINE_SPINLOCK(rcu_gp_lock);
#define RCU_GP_CTR_SHIFT 7
#define RCU_GP_CTR_BOTTOM_BIT (1 << RCU_GP_CTR_SHIFT)
#define RCU_GP_CTR_NEST_MASK (RCU_GP_CTR_BOTTOM_BIT - 1)
#define MAX_GP_ADV_DISTANCE (RCU_GP_CTR_NEST_MASK << 8)
unsigned long rcu_gp_ctr = 0;
DEFINE_PER_THREAD(unsigned long, rcu_reader_gp);
static void rcu_read_lock(void)
{
unsigned long tmp;
unsigned long *rrgp;
// 压位嵌套
rrgp = &__get_thread_var(rcu_reader_gp);
tmp = *rrgp;
if ((tmp & RCU_GP_CTR_NEST_MASK) == 0)
tmp = READ_ONCE(rcu_gp_ctr);
tmp++;
WRITE_ONCE(*rrgp, tmp);
smp_mb();
}
static void rcu_read_unlock(void)
{
smp_mb();
__get_thread_var(rcu_reader_gp)--;
}
void synchronize_rcu(void)
{
int t;
smp_mb();
spin_lock(&rcu_gp_lock);
WRITE_ONCE(rcu_gp_ctr, rcu_gp_ctr + RCU_GP_CTR_BOTTOM_BIT);
smp_mb();
for_each_thread(t) {
// rcu_gp_ongoing 是一个检查 RCU_GP_CTR_NEST_MASK 的实现,略
while (rcu_gp_ongoing(t) &&
((READ_ONCE(per_thread(rcu_reader_gp, t)) - rcu_gp_ctr) < 0)) {
poll(NULL, 0, 10);
}
}
spin_unlock(&rcu_gp_lock);
smp_mb();
}
RCU Based on Quiescent State
DEFINE_SPINLOCK(rcu_gp_lock);
long rcu_gp_ctr = 0;
DEFINE_PER_THREAD(long, rcu_reader_qs_gp);
// 假定是 Linux server(非抢占)
static void rcu_read_lock(void)
{
}
static void rcu_read_unlock(void)
{
}
static void rcu_quiescent_state(void)
{
smp_mb();
// 做法类似上例
// 但是不在临界区标记,而是在静默状态标记
__get_thread_var(rcu_reader_qs_gp) = READ_ONCE(rcu_gp_ctr) + 1;
smp_mb();
}
static void rcu_thread_offline(void)
{
smp_mb();
__get_thread_var(rcu_reader_qs_gp) = READ_ONCE(rcu_gp_ctr);
smp_mb();
}
// 进入静默状态时调用 online,离开时调用 offline
static void rcu_thread_online(void)
{
rcu_quiescent_state();
}
void synchronize_rcu(void)
{
int t;
smp_mb();
spin_lock(&rcu_gp_lock);
WRITE_ONCE(rcu_gp_ctr, rcu_gp_ctr + 2);
smp_mb();
for_each_thread(t) {
while (rcu_gp_ongoing(t) &&
((per_thread(rcu_reader_qs_gp, t) - rcu_gp_ctr) < 0)) {
poll(NULL, 0, 10);
}
}
spin_unlock(&rcu_gp_lock);
smp_mb();
}
类型安全
这一部分作者说得很少,就简单写一下个人见解。
RCU 不仅能提供存在担保(existence guarantee),还能提供相对更弱的类型安全担保(type-safety guarantee)。存在担保在前面也说过,能保证受保护的数据在临界区内不会被回收,这也是 RCU 为什么存在宽限期的原因。而类型安全指的是临界区内的数据可能会被回收且重用,即同一内存地址下存储的会是另一个「对象」(类似 slab),但是能保证该「对象」是同一类型,因此你的解引用同样不会失败,并且解引用得到的字段依然具有实际意义(比如对象的版本号)而不是垃圾值。
那么为什么需要类型安全呢?因为这样可以为分配器实现提供快速复用的可能性,而不必等到宽限期结束才有机会复用内存,并且因为临界区是只读的性质,也不会修改被复用的数据内存,至少感性上能快速证明它是高效且安全的。
这算是非常细致的优化应用了,感兴趣的选手可以具体调研一下 Linux 的 SLAB_TYPESAFE_BY_RCU 标记(搭配 kmem_cache_create() 使用)。
并行数据结构
第十章讨论并行的数据结构。讨论要先有动机,假设你是《加帕里公园》的老大,为了贩卖野生动物要做增删改查,动物是大量且短周期的,客人也随时会查询并且极其倾斜于热门动物,你该怎么办。
可分区的数据结构
续上第六章的分区讨论,作者认为在选择并行数据结构时,可分区性必须是首选项。而前面示例中用到的哈希表则是满足需求的数据结构。注意这里说的是使用链式实现的哈希表(chained hash table),因为这样才是完全分区。此外也有 split-ordered list 等哈希表变种支持完全分区,只是更加复杂。
哈希表的实现源码
/********** 数据结构 **********/
struct ht_elem {
struct cds_list_head hte_next;
unsigned long hte_hash;
};
// 每个桶都持锁
struct ht_bucket {
struct cds_list_head htb_head;
spinlock_t htb_lock;
};
struct hashtab {
unsigned long ht_nbuckets;
int (*ht_cmp)(struct ht_elem *htep, void *key);
struct ht_bucket ht_bkt[0];
};
/********** 哈希映射和锁操作 **********/
#define HASH2BKT(htp, h) \
(&(htp)->ht_bkt[(h) % (htp)->ht_nbuckets])
// 下面的读写操作没有 lock 和 unlock,需要调用者自行处理
static void hashtab_lock(struct hashtab *htp,
unsigned long hash)
{
spin_lock(&HASH2BKT(htp, hash)->htb_lock);
}
static void hashtab_unlock(struct hashtab *htp,
unsigned long hash)
{
spin_unlock(&HASH2BKT(htp, hash)->htb_lock);
}
/********** 读操作 **********/
struct ht_elem* hashtab_lookup(struct hashtab *htp, unsigned long hash,
void *key)
{
struct ht_bucket *htb;
struct ht_elem *htep;
htb = HASH2BKT(htp, hash);
cds_list_for_each_entry(htep, &htb->htb_head, hte_next) {
if (htep->hte_hash != hash)
continue;
if (htp->ht_cmp(htep, key))
return htep;
}
return NULL;
}
/********** 写操作 **********/
void hashtab_add(struct hashtab *htp, unsigned long hash,
struct ht_elem *htep)
{
htep->hte_hash = hash;
cds_list_add(&htep->hte_next, &HASH2BKT(htp, hash)->htb_head);
}
void hashtab_del(struct ht_elem *htep)
{
cds_list_del_init(&htep->hte_next);
}
/********** 内存分配操作 **********/
struct hashtab* hashtab_alloc(unsigned long nbuckets,
int (*cmp)(struct ht_elem *htep, void *key))
{
struct hashtab *htp;
int i;
htp = malloc(sizeof(*htp) + nbuckets * sizeof(struct ht_bucket));
if (htp == NULL)
return NULL;
htp->ht_nbuckets = nbuckets;
htp->ht_cmp = cmp;
for (i = 0; i < nbuckets; i++) {
CDS_INIT_LIST_HEAD(&htp->ht_bkt[i].htb_head);
spin_lock_init(&htp->ht_bkt[i].htb_lock);
}
return htp;
}
void hashtab_free(struct hashtab *htp)
{
free(htp);
}
非常直接的 per-bucket lock 实现,性能当然是……很不怎样(图略)。具体来说,在仅有 28 核心,20 万个桶的场合下已经严重偏离理想值。部分的原因是锁操作导致多核间的 cache miss。虽然在使用 28 核时仍能满足线性的扩展性(但是性能本身是不行的),更多核心的扩展性是会衰退的(因为只要产生跨 socket 传播,延迟惩罚就会加重,这种 NUMA 效应 已经多次提过了)。
作者尝试增加桶的数目以挽救冲突导致的性能问题,结果是没有变化,至少表明了哈希算法和桶的负载都没有问题。
NOTE: 也可以测试桶的缓存对齐有没有效果,常见思路尽可能多试试。
后面就是转换思路了,总之从前面的结论来看,对于多 socket 系统,除了需要完全分区,还需要良好的引用局部性。下一节就是尝试从多数只读的角度来挖掘局部性。
NOTE: 也可以直接考虑类似分布式的 sharding 做法,也就是每个 socket 各绑一部分的数据。但是作者认为这在多 socket 系统中是不值得的,这种做法更适用于多台廉价机器。
多数只读的数据结构
很显然,使用前面讨论的 RCU 来替代 per-bucket lock 是一种可行策略,风险指针也是可选项。
基于 RCU 的哈希表
/********** RCU read lock 操作 **********/
static void hashtab_lock_lookup(struct hashtab *htp,
unsigned long hash)
{
rcu_read_lock();
}
static void hashtab_unlock_lookup(struct hashtab *htp,
unsigned long hash)
{
rcu_read_unlock();
}
/********** 读操作 **********/
struct ht_elem* hashtab_lookup(struct hashtab *htp,
unsigned long hash,
void *key)
{
struct ht_bucket *htb;
struct ht_elem *htep;
htb = HASH2BKT(htp, hash);
cds_list_for_each_entry_rcu(htep, &htb->htb_head, hte_next) {
if (htep->hte_hash != hash)
continue;
if (htp->ht_cmp(htep, key))
return htep;
}
return NULL;
}
/********** 写操作 **********/
void hashtab_add(struct hashtab *htp,
unsigned long hash,
struct ht_elem *htep)
{
htep->hte_hash = hash;
cds_list_add_rcu(&htep->hte_next, &HASH2BKT(htp, hash)->htb_head);
}
void hashtab_del(struct ht_elem *htep)
{
cds_list_del_rcu(&htep->hte_next);
}
重新实现后的查找性能总算是好转……了一点(图略)。作者先后尝试了 per-thread counter 和 QSBR 两种 RCU 实现,都能做到全系统 400+ 核心的线性扩展,但是只达到理论性能的 1/5。
这样的结果违反了前面得到的经验:
- 在路由表(并行链表)负载测试中,RCU 表现极好。
- 虽然哈希表和链表存在差异,但是上一节已经表明不影响结果。
这个时候有必要质疑真实瓶颈在哪里。先是 CPU 瓶颈的调研,一种排查方式是使用完全静态(不需任何同步)的只读压测,结果表明确实只有 1/5 的理论性能,即 CPU 并非瓶颈。再换到内存瓶颈的调研,整理结构体大小和系统的缓存层级发现,测试场合占用的内存已经溢出 L2 三十倍,并且在 L3 溢出的边缘。如果能减少内存占用,那就能得到路由表的极好表现。
最后还有热点问题的讨论,结论是 RCU 和风险指针都能直接应付。作者也针对这个问题继续讨论了不同读写比例带来的影响,即使是大量写者的场合,RCU 也比锁实现表现要好(虽然写侧性能持平,但是读侧能吃到 RCU 红利)。
并行扩展的数据结构
前面实现的是固定大小的哈希表,这里接着用 RCU 来构建可扩展的哈希表。
 初始存在两个桶,后续扩容到四个桶
初始存在两个桶,后续扩容到四个桶
基于 RCU 的可扩展哈希表
/* Hash-table element to be included in structures in a hash table. */
struct ht_elem {
// 用户外部调用 call_rcu(rh, ...) 时使用
struct rcu_head rh;
// 每个 bucket element 使用 2 个侵入式链表
// 使用 (struct ht *)->ht_idx 定位链表
// ht_idx 数值只有 0 和 1 交替更新
struct cds_list_head hte_next[2];
};
/* Hash-table bucket element. */
struct ht_bucket {
// bucket 的链表头部
struct cds_list_head htb_head;
// per-bucket 锁,用于 (per-bucket) mod 和 resize 操作互斥
// 读侧仍然不需要持锁,只需确保处于 RCU 读临界区
spinlock_t htb_lock;
};
/* Hash-table instance, duplicated at resize time. */
// 内部的哈希表
struct ht {
// 当前表内 bucket 的数目
long ht_nbuckets;
// 渐进更新记录的进展,数值为当前已迁移的 bucket 下标
// 如果没有更新则为 -1
long ht_resize_cur;
// 尚未发布的(正在渐进更新的)内部哈希表
struct ht *ht_new;
// 决定 bucket 遍历的链表下标
// 交替更新:ht_new->idx = !ht_old->ht_idx
int ht_idx;
int (*ht_cmp)(struct ht_elem *htep, void *key);
unsigned long (*ht_gethash)(void *key);
void *(*ht_getkey)(struct ht_elem *htep);
// 当前内部哈希表的 bucket 容器
struct ht_bucket ht_bkt[0];
};
// 用于进展补标,因为 resize 阶段的迁移存在滞后
struct ht_lock_state {
// 同一 key 的新旧 bucket 地址
struct ht_bucket *hbp[2];
// 指定 bucket->hte_next[] 的 下标
int hls_idx[2];
};
/* Top-level hash-table data structure, including buckets. */
// 供外部使用的顶层哈希表
// 整个哈希表的层级是:hashtable -> ht -> ht_bucket -> ht_elem
struct hashtab {
// 当前订阅的内部哈希表版本
struct ht *ht_cur;
// 确保 resize 操作的互斥
spinlock_t ht_lock;
};
/* Allocate a hash-table instance. */
struct ht *
ht_alloc(unsigned long nbuckets,
int (*cmp)(struct ht_elem *htep, void *key),
unsigned long (*gethash)(void *key),
void *(*getkey)(struct ht_elem *htep))
{
struct ht *htp;
int i;
htp = malloc(sizeof(*htp) + nbuckets * sizeof(struct ht_bucket));
if (htp == NULL)
return NULL;
htp->ht_nbuckets = nbuckets;
htp->ht_resize_cur = -1;
htp->ht_new = NULL;
htp->ht_idx = 0;
htp->ht_cmp = cmp;
htp->ht_gethash = gethash;
htp->ht_getkey = getkey;
for (i = 0; i < nbuckets; i++) {
CDS_INIT_LIST_HEAD(&htp->ht_bkt[i].htb_head);
spin_lock_init(&htp->ht_bkt[i].htb_lock);
}
return htp;
}
/* Allocate a full hash table, master plus instance. */
struct hashtab *
hashtab_alloc(unsigned long nbuckets,
int (*cmp)(struct ht_elem *htep, void *key),
unsigned long (*gethash)(void *key),
void *(*getkey)(struct ht_elem *htep))
{
struct hashtab *htp_master;
htp_master = malloc(sizeof(*htp_master));
if (htp_master == NULL)
return NULL;
htp_master->ht_cur =
ht_alloc(nbuckets, cmp, gethash, getkey);
if (htp_master->ht_cur == NULL) {
free(htp_master);
return NULL;
}
spin_lock_init(&htp_master->ht_lock);
return htp_master;
}
/* Free a full hash table, master plus instance. */
void hashtab_free(struct hashtab *htp_master)
{
free(htp_master->ht_cur);
free(htp_master);
}
/* Get hash bucket corresponding to key, ignoring the possibility of resize. */
// b: 表示 bucket index,作为出参
// h: 表示 hash value,作为可选的出参
// 返回定位到的 bucket 地址
static struct ht_bucket *
ht_get_bucket(struct ht *htp, void *key,
long *b, unsigned long *h)
{
unsigned long hash = htp->ht_gethash(key);
*b = hash % htp->ht_nbuckets;
if (h)
*h = hash;
return &htp->ht_bkt[*b];
}
/* Search the bucket for the specfied key in the specified ht structure. */
// 定位 bucket 且遍历 element
static struct ht_elem *
ht_search_bucket(struct ht *htp, void *key)
{
long b;
struct ht_elem *htep;
struct ht_bucket *htbp;
htbp = ht_get_bucket(htp, key, &b, NULL);
cds_list_for_each_entry_rcu(htep,
&htbp->htb_head,
// 通过 ht_idx 指定遍历的链表
hte_next[htp->ht_idx]) {
if (htp->ht_cmp(htep, key))
return htep;
}
return NULL;
}
/* Read-side lock/unlock functions. */
static void hashtab_lock_lookup(struct hashtab *htp_master, void *key)
{
rcu_read_lock();
}
static void hashtab_unlock_lookup(struct hashtab *htp_master, void *key)
{
rcu_read_unlock();
}
/* Update-side lock/unlock functions. */
static void
hashtab_lock_mod(struct hashtab *htp_master, void *key,
struct ht_lock_state *lsp)
{
long b;
unsigned long h;
struct ht *htp;
struct ht_bucket *htbp;
rcu_read_lock();
// 当前订阅的哈希表
// 注:htp_master->ht_cur 和 htp->ht_new 会在 resize 阶段发布
htp = rcu_dereference(htp_master->ht_cur);
// key 对应的 bucket 地址
htbp = ht_get_bucket(htp, key, &b, &h);
// 锁定旧的 bucket,并且记录遍历用的链表下标
spin_lock(&htbp->htb_lock);
lsp->hbp[0] = htbp;
lsp->hls_idx[0] = htp->ht_idx;
// 如果定位到的 bucket index 超过了当前 resize 的进展
// 那么可以不用管,后续 resize 会将 bucket 迁移过去
// 也就是说 [1] 只会在 resize 迁移相同 bucket index 进展过后才需记录
// 注:这里说的迁移,实际是拷贝
if (b > READ_ONCE(htp->ht_resize_cur)) {
lsp->hbp[1] = NULL;
return;
}
// 正在迁移的新的哈希表
htp = rcu_dereference(htp->ht_new);
// 以及新的 rehashed bucket 地址
htbp = ht_get_bucket(htp, key, &b, &h);
// 锁定新的 bucket
spin_lock(&htbp->htb_lock);
lsp->hbp[1] = htbp;
lsp->hls_idx[1] = htp->ht_idx;
}
static void
hashtab_unlock_mod(struct ht_lock_state *lsp)
{
spin_unlock(&lsp->hbp[0]->htb_lock);
if (lsp->hbp[1])
spin_unlock(&lsp->hbp[1]->htb_lock);
rcu_read_unlock();
}
/*
* Look up a key. Caller must have acquired either a read-side or update-side
* lock via either hashtab_lock_lookup() or hashtab_lock_mod(). Note that
* the return is a pointer to the ht_elem: Use offset_of() or equivalent
* to get a pointer to the full data structure.
*/
// 非常直接的 lookup 实现
struct ht_elem *
hashtab_lookup(struct hashtab *htp_master, void *key)
{
struct ht *htp;
struct ht_elem *htep;
htp = rcu_dereference(htp_master->ht_cur);
htep = ht_search_bucket(htp, key);
return htep;
}
/*
* Add an element to the hash table. Caller must have acquired the
* update-side lock via hashtab_lock_mod().
*/
void hashtab_add(struct ht_elem *htep,
struct ht_lock_state *lsp)
{
struct ht_bucket *htbp = lsp->hbp[0];
int i = lsp->hls_idx[0];
cds_list_add_rcu(&htep->hte_next[i], &htbp->htb_head);
// 进展补标,resize 过程迁移对应 bucket 后,此时又增加一位新的 element
if ((htbp = lsp->hbp[1])) {
cds_list_add_rcu(&htep->hte_next[!i], &htbp->htb_head);
}
}
/*
* Remove the specified element from the hash table. Caller must have
* acquired the update-side lock via hashtab_lock_mod().
*/
// 这里只是将 element 移除出 bucket 的遍历链表
void hashtab_del(struct ht_elem *htep,
struct ht_lock_state *lsp)
{
int i = lsp->hls_idx[0];
cds_list_del_rcu(&htep->hte_next[i]);
if (lsp->hbp[1])
cds_list_del_rcu(&htep->hte_next[!i]);
}
/* Resize a hash table. */
int hashtab_resize(struct hashtab *htp_master,
unsigned long nbuckets,
int (*cmp)(struct ht_elem *htep, void *key),
unsigned long (*gethash)(void *key),
void *(*getkey)(struct ht_elem *htep))
{
struct ht *htp;
struct ht *htp_new;
int i;
int idx;
struct ht_elem *htep;
struct ht_bucket *htbp;
struct ht_bucket *htbp_new;
long b;
// 尝试获取全局锁,只会在并行 resize 时互斥
if (!spin_trylock(&htp_master->ht_lock))
return -EBUSY;
htp = htp_master->ht_cur;
htp_new = ht_alloc(nbuckets,
cmp ? cmp : htp->ht_cmp,
gethash ? gethash : htp->ht_gethash,
getkey ? getkey : htp->ht_getkey);
if (htp_new == NULL) {
spin_unlock(&htp_master->ht_lock);
return -ENOMEM;
}
idx = htp->ht_idx;
htp_new->ht_idx = !idx;
// 发布(内部)版本,并通过 syncrhonize RCU 达成一致
rcu_assign_pointer(htp->ht_new, htp_new);
synchronize_rcu();
for (i = 0; i < htp->ht_nbuckets; i++) {
htbp = &htp->ht_bkt[i];
// 每次迁移只移动一个 bucket 内的 element
// 这样保证 resize 和(除当前 bucket 外的)mod 操作并行
spin_lock(&htbp->htb_lock);
// 重新 rehash 的过程
cds_list_for_each_entry(htep, &htbp->htb_head, hte_next[idx]) {
htbp_new = ht_get_bucket(htp_new, htp_new->ht_getkey(htep), &b, NULL);
spin_lock(&htbp_new->htb_lock);
cds_list_add_rcu(&htep->hte_next[!idx], &htbp_new->htb_head);
spin_unlock(&htbp_new->htb_lock);
}
// 记录当前的 resize 进展,以 bucket 下标作为标记
WRITE_ONCE(htp->ht_resize_cur, i);
spin_unlock(&htbp->htb_lock);
}
// 整体迁移完成,发布新版本
rcu_assign_pointer(htp_master->ht_cur, htp_new);
synchronize_rcu();
spin_unlock(&htp_master->ht_lock);
// 老东西已经超过了宽限期,可以直接毕业
// 由于 bucket 是与哈希表连续分配的,也一并收拾了
free(htp);
return 0;
}
这是 Linux 早期使用的实现版本,如上图所示,思路很直接:
- 实际存在两个交替版本的哈希表,渐进 rehash/resize 后发布新版本,超过宽限期后回收旧版本。
- 桶内的每个元素都使用两个侵入式链表(Links 0/1),下标 0 和 下标 1 使用对应不同的链表。
其实代码是比较繁琐的(看注释!),不过这已经是一个可用的并行数据结构。它保证读侧仍然是 lockless 设计,并且 resize 只与单个 bucket 的写操作互斥。
形式化验证
不懂。我把要说的都放在另一篇文章了:使用 GenMC 检验 C/C++ 内存模型。
高级同步
Prior Operation Subsequent Operation
--------------- ---------------------------
C Self R W RMW Self R W DR DW RMW SV
-- ---- - - --- ---- - - -- -- --- --
Relaxed store Y Y
Relaxed load Y Y Y Y
Relaxed RMW operation Y Y Y Y
rcu_dereference() Y Y Y Y
Successful *_acquire() R Y Y Y Y Y Y
Successful *_release() C Y Y Y W Y
smp_rmb() Y R Y Y R
smp_wmb() Y W Y Y W
smp_mb() & synchronize_rcu() CP Y Y Y Y Y Y Y Y
Successful full non-void RMW CP Y Y Y Y Y Y Y Y Y Y Y
smp_mb__before_atomic() CP Y Y Y a a a a Y
smp_mb__after_atomic() CP a a Y Y Y Y Y Y
Key: Relaxed: A relaxed operation is either READ_ONCE(), WRITE_ONCE(),
a *_relaxed() RMW operation, an unsuccessful RMW
operation, a non-value-returning RMW operation such
as atomic_inc(), or one of the atomic*_read() and
atomic*_set() family of operations.
C: Ordering is cumulative
P: Ordering propagates
R: Read, for example, READ_ONCE(), or read portion of RMW
W: Write, for example, WRITE_ONCE(), or write portion of RMW
Y: Provides ordering
a: Provides ordering given intervening RMW atomic operation
DR: Dependent read (address dependency)
DW: Dependent write (address, data, or control dependency)
RMW: Atomic read-modify-write operation
SELF: Orders self, as opposed to accesses before and/or after
SV: Orders later accesses to the same variable
第十五章就是讨论 memory model,我在前面也写了简单的 LKMM 介绍。作者直接丢一张密密麻麻的速查表过来,怕是要把人吓跑了(被自己菜哭)。速查表来源见 Table 15.3 或者这里。后面会介绍一些比较特殊的性质,比如各种依赖(D),还有 C (cumulativity) 和 P (propagation)。
NOTE: 第十四章的标题也是「高级同步」,不过话题是实时计算(特指 RTOS),不懂略。
litmus test
C C-SB+o-o+o-o // [内存模型] [litmus 文件名]
"这一行可以用于注释"
{} // 初始化,不写就是 0
P0(int *x0, int *x1) // P0 表示一个线程,括号范围内表示传参
{ // 注意参数名是有意义的,P0 和 P1 共享 x0 x1 变量
int r2;
WRITE_ONCE(*x0, 2);
r2 = READ_ONCE(*x1);
}
P1(int *x0, int *x1) // P1 表示另一个线程,以此类推
{
int r2;
WRITE_ONCE(*x1, 2);
r2 = READ_ONCE(*x0);
}
exists (0:r2=0 /\ 1:r2=0) // 确认以下断言是否存在:
// P0 的 r2 和 P1 的 r2 是否为 0
// 逻辑运算 /\ 表示与,\/ 表示或
//
// 由于该内存模型允许重排序的存在
// 因此运行得出,该断言是存在的
这一章需要了解一些形式化验证用到的 litmus test 语法,用于判断指定的内存模型会产生什么样的结果。这里的语法和前面一章给的工具笔记(私人偏好)有些不同,上面的 litmus 示例程序和注释可以简单了解一下。推荐参考 tools/memory-model 文档和安装 herd7 工具来运行 .litmus 文件。
后面会重度使用 litmus test 验证内存模型,并且解释一些现象。
内存访问乱序
虽然 x86 TSO 内存模型只允许不同位置的 store-load 操作产生乱序,但是更加弱序的硬件可能允许 load-load、load-store 和 store-store 乱序,后面有具体 litmus test 示例。
C C-MP+o-wmb-o+o-o
{}
P0(int* x0, int* x1) {
WRITE_ONCE(*x0, 2);
smp_wmb();
WRITE_ONCE(*x1, 2);
}
P1(int* x0, int* x1) {
int r2;
int r3;
r2 = READ_ONCE(*x1); // 乱序
// smp_rmb(); // 加上这一行,可以避免乱序
r3 = READ_ONCE(*x0); // 乱序
}
// 会触发
exists (1:r2=2 /\ 1:r3=0)
不同位置的 load-load 允许乱序。这是因为当早期的 load x1 操作遇到 cache miss 时,CPU 有权让(已存在于 cache 的)后期的 load x2 操作提前执行。这种对用户可见的弱序看起来有点像投机执行,但是前者不需要为执行失败而回滚。作者也提到了(频繁的)投机执行并不适用于能耗敏感的设备。
C C-LB+o-o+o-o
{}
P0(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x1);
WRITE_ONCE(*x0, 2); // 需替换为 smp_store_release(x0, 2);
}
P1(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x0); // 需替换为 r2 = smp_load_acquire(x0);
WRITE_ONCE(*x1, 2);
}
// 会触发
exists (1:r2=2 /\ 0:r2=2)
作者提到 load-store 乱序是很少见的。该现象存在的场合是:load 操作遇到 cache miss,同时 store buffer 近乎已满,store 操作对应的 cacheline 又刚好就绪,CPU 就有权进行重排序。
C C-MP+o-o+o-rmb-o
{}
P0(int* x0, int* x1) {
WRITE_ONCE(*x0, 2); // 乱序
// smp_wmb(); // 加上这一行,可以避免乱序
WRITE_ONCE(*x1, 2); // 乱序
}
P1(int* x0, int* x1) {
int r2;
int r3;
r2 = READ_ONCE(*x1);
smp_rmb();
r3 = READ_ONCE(*x0);
}
// 会触发
exists (1:r2=2 /\ 1:r3=0)
store-store 乱序也是允许的。原因是 store buffer 满了要刷入 cache,但是早期的 store 操作对应的 cacheline 还没准备好,那么后期的可以先上。
依赖乱序
这一节是作者继续使用形式化验证来确信地告知你的依赖花活是否可靠。
C C-MP+o-wmb-o+o-ad-o
{
y = 1;
x1 = y; // x1 初始化时指向 y
}
P0(int* x0, int** x1) {
WRITE_ONCE(*x0, 2);
smp_wmb();
WRITE_ONCE(*x1, x0); // 更新 x1 指针,指向 x0
}
P1(int** x1) {
int *r2;
int r3;
r2 = READ_ONCE(*x1); // 早期 Linux 可使用 r2 = lockless_dereference(*x1); 保证有序
r3 = READ_ONCE(*r2); // 这两行构成了地址依赖
}
// Linux v4.15 前会触发
exists (1:r2=x0 /\ 1:r3=1)
地址依赖(address dependency)指的是一个 load 操作得到的值被(下一个内存访问操作)用于计算地址。作者提到这种现象通常是有序的,唯独 DEC Alpha 架构使用一个投机得到的值去处理地址依赖,从而导致乱序。幸好 Linux v4.15 后的内存模型能保证 ONCE 语义不会触发地址依赖乱序。
NOTES:
- 上面这种算是 dependent load 操作。而目前市面上所有的架构都不会有 dependent store 操作产生乱序。假设上面示例的
READ_ONCE(*r2) 改为 WRITE_ONCE(*r2, 3),即使是离谱的 DEC Alpha 架构也不会产生乱序。
- 作者为什么会提这些看着没用的依赖技巧?一个原因可以看作者的演讲稿(左下角第 101 页)。省流版本:这些依赖是无开销的,甚至不需要编译器屏障。
C C-LB+o-r+o-data-o
{}
// 可以对比 C-LB+o-o+o-o 的解决方案
// 这里 P1 不需要 smp_load_acquire
P0(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x1);
smp_store_release(x0, 2);
}
P1(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x0);
WRITE_ONCE(*x1, r2); // 这两行构成了数据依赖
}
// **不会**触发
exists (1:r2=2 /\ 0:r2=2)
In short, you can rely on data dependencies only if you prevent the compiler from breaking them.
数据依赖(data dependency)指的是一个 load 操作得到的值被用于计算数据,然后存放于下一个 store 操作。尽管结论是数据依赖不会产生乱序,但是作者仍不建议使用这种无保护的做法,因为复杂场合下的编译器优化很擅长破坏数据依赖的关系(地址依赖也是)。个人认为作者的表意是:除非你的场合长得和上例一模一样,或者很确信数据依赖不会 break,否则还是别使用数据依赖带来的保证。
C C-LB+o-r+o-ctrl-o
{}
P0(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x1);
smp_store_release(x0, 2);
}
P1(int *x0, int *x1)
{
int r2;
r2 = READ_ONCE(*x0);
if (r2 >= 0)
WRITE_ONCE(*x1, 2);
}
// **不会**触发
exists (1:r2=2 /\ 0:r2=2)
In summary, control dependencies can be useful, but they are high-maintenance items. You should therefore use them only when performance considerations permit no other solution.
控制依赖(control dependency)指的是一个 load 操作得到的值被用于测试分支(conditional branch/move),以确认下一个操作是否需要执行。结论是所有的硬件平台都能保证控制依赖的 load-to-store 有序,但是需要注意多数平台并不遵循 load-to-load 有序。
缓存一致性
具有缓存一致性(cache coherence)的硬件平台,可以保证所有的 CPU 都会对单个变量的 store 操作顺序达成一致。
C C-CCIRIW+o+o+o-o+o-o
{}
// 只针对一个变量(位置)
P0(int *x)
{
WRITE_ONCE(*x, 1);
}
P1(int *x)
{
WRITE_ONCE(*x, 2);
}
// 测试 P2 和 P3 是否读到不一致的顺序
// (1, 2)
P2(int *x)
{
int r1;
int r2;
r1 = READ_ONCE(*x);
r2 = READ_ONCE(*x);
}
// (2, 1)
P3(int *x)
{
int r3;
int r4;
r3 = READ_ONCE(*x);
r4 = READ_ONCE(*x);
}
// **不会**触发
exists(2:r1=1 /\ 2:r2=2 /\ 3:r3=2 /\ 3:r4=1)
目前绝大部分平台都能满足缓存一致性(死去的 IA64 除外),这里的 exists 子句并不会触发。
NOTE: perfbook 15.2.6 提到会触发 exists 子句,但是实测并不允许这种状态存在。
多拷贝原子性
前面的缓存一致性是针对单个变量(位置)而言的,因此有一种别名是单拷贝原子性(single-copy atomicity)。
而多拷贝原子性(multicopy atomicity)表示对多个变量的 store 操作的顺序仍可达成一致。构建一个多拷贝原子性的系统就像把内存和所有 CPU 都挂在单个总线上直接通信,不论任何 CPU 和任何位置执行的 store 还是观察到的 load 都会达成一致,但是效率是低下的。因此多数厂商会提供更弱的 other-multicopy atomicity(没找到中文翻译),这种模式会把执行 store 操作的 CPU 排除出达成一致的要求(其它的 CPU 达成一致)。因此执行 store 操作的 CPU 能更快的看到(load)自身的结果。
As of early 2021, Armv8 and x86 provide other-multicopy atomicity, IBM mainframe provides full multicopy atomicity, and PPC provides no multicopy atomicity at all.
C C-WRC+o+o-data-o+o-rmb-o
{}
// 假设 P0 的 store 操作,随着时间推移:
// 很快地传播到 P1
// 但是很久才传播到 P2
P0(int *x)
{
WRITE_ONCE(*x, 1);
}
// 假设 P1 的 store 操作也很快地传播到 P2
P1(int *x, int *y)
{
int r1;
r1 = READ_ONCE(*x); // 这两行保证有序
WRITE_ONCE(*y, r1); // 因为使用了数据依赖
}
// 因此 P2 可能读到:
// r2: {}->P1->P2->P3 == 1
// r3: {} == 0
P2(int *x, int *y)
{
int r2;
int r3;
r2 = READ_ONCE(*y);
smp_rmb();
r3 = READ_ONCE(*x);
}
// 会触发
exists (1:r1=1 /\ 2:r2=1 /\ 2:r3=0)
 只有黑线是确定顺序的,绿线可根据 (1:r1=1 /\ 2:r2=1) 推断出来
只有黑线是确定顺序的,绿线可根据 (1:r1=1 /\ 2:r2=1) 推断出来
上面的示例用于测试多拷贝原子性。可以看出非(完全)多拷贝原子性的平台即使使用了依赖以保证顺序,也可能得到不一致的结果。在这里 CPU 1 与 CPU 0 的位置 x 达成一致,并不代表 CPU 2 与 CPU 0 达成一致。白板上画了张示意图,随便看看。
Cumulativity
C C-WRC+o+o-r+a-o
{}
P0(int *x)
{
WRITE_ONCE(*x, 1);
}
P1(int *x, int *y)
{
int r1;
r1 = READ_ONCE(*x);
smp_store_release(y, r1); // 提供累积性,使得对位置 x 达成共识
}
P2(int *x, int *y)
{
int r2;
int r3;
r2 = smp_load_acquire(y); // acquire 得到 (y, r1) 时,保证 r1 load 先于 r3 load
r3 = READ_ONCE(*x);
}
// **不会**触发
exists (1:r1=1 /\ 2:r2=1 /\ 2:r3=0)
 蓝色的屏障挡住 CPU 0 到 CPU 2 的 store x 乱序
蓝色的屏障挡住 CPU 0 到 CPU 2 的 store x 乱序
A cumulative memory-ordering operation orders not just any given access preceding it, but also earlier accesses by any thread to that same variable.
Note also that cumulativity is not limited to a single step back in time. If there was another load from x or store to x from any thread that came before the store on line 7, that prior load or store would also be ordered before the load on line 24, though only if both r1 and r2 both end up containing the value 1.
多拷贝原子性示例之所以会失败,是因为缺少 cumulativity(累积性?),这里使用具有累积性的 release 操作去修复。如图所示,当 acquire 读到 release 对应值(exisits: r2=1)时,使得 Load r1=x 早于 Load r3=x 执行。而 release 具有累积性,已知 CPU 1 与 CPU 0 的位置 x 在 release 前达成一致,且累积性对于所有线程(的位置 x)有效,CPU 2 也会在 acquire 前与 CPU 0 达成一致。
新增 C-WRC+o+o-r+a-o+o-rmb-o 测试
C C-WRC+o+o-r+a-o+o-rmb-o // 这不是书里的示例
{}
P0(int *x)
{
WRITE_ONCE(*x, 1);
}
P1(int *x, int *y)
{
int r1;
r1 = READ_ONCE(*x);
smp_store_release(y, r1); // 提供累积性,使得对位置 x 达成共识
}
P2(int *x, int *y)
{
int r2;
int r3;
r2 = smp_load_acquire(y);
r3 = READ_ONCE(*x); // 从前面的示例得知 r1=1, r2=1 时必满足 r3=1
}
P3(int *x, int *y)
{
int r4;
int r5;
r4 = READ_ONCE(*y); // 这里需要假定 r4=1,
smp_rmb(); // smp_rmb 不具有累积性,也不影响正确性(这里只有 load-load 操作)
r5 = READ_ONCE(*x); // 判断 r5=0 是否有可能,类似上例的 r3=0
}
// **不会**触发
exists (1:r1=1 /\ 2:r2=1 /\ 2:r3=1 /\ 3:r4=1 /\ 3:r5=0)
NOTES:
- 之前我对累积性的描述有些拿不准,不确定是所有 CPU 达成一致还是仅对于使用 release-acquire 的一对 CPU 达成一致,因此多加了一个
C-WRC+o+o-r+a-o+o-rmb-o 测试(这不是书里的内容)。可以看出累积性是对于所有的 CPU 达成一致。
- 所以,前面的
C-WRC+o+o-r+a-o 示例的 P2 并非必须使用 acquire 操作搭配 release 操作。由于示例只有 load-load 操作,改为 READ_ONCE(*y) 加上 smp_rmb,同样不会触发 exists 子句。
Propagation
C C-W+RWC+o-r+a-o+o-mb-o // !!! FIXME: 这里的分析没有完整考虑 smp_mb !!!
{}
P0(int *x, int *y)
{
WRITE_ONCE(*x, 1);
smp_store_release(y, 1); // 使用累积性
}
P1(int *y, int *z)
{
int r1;
int r2;
r1 = smp_load_acquire(y); // 这里假定 r1=1,即 x/r3=1 达成共识(但是,仅限 P2 执行在此之后)
r2 = READ_ONCE(*z); // 这里假定 r2=0,看着像是保证了 P2 所有代码甚至在此之后才执行
}
P2(int *z, int *x)
{
int r3;
WRITE_ONCE(*z, 1); // 但是,这一行其实可能早于 P1 任意代码执行,传播延迟导致 r2=0
smp_mb(); // 此时使用任何屏障确保 program order 都无法保证正确性
r3 = READ_ONCE(*x); // 所以仍有可能 r3=0
}
// 会触发
exists(1:r1=1 /\ 1:r2=0 /\ 2:r3=0)
 from-read 可以做到「时间倒流」
from-read 可以做到「时间倒流」
这里需要注意传播(propagation)的问题,load 操作能看到旧值并不意味着执行时机一定早于 store 操作,见上图的 from-read 关系。其实从前面的累积性示例也可以看出 store 操作的传播需要时间,也就是所有 CPU 之间的 cache coherence 只是最终达成一致(从而达成「时间倒流」的效果),但是在那一例中我们一直在以「读到新值」的前提去讨论,所以没有暴露问题。总之,仅依靠 release 操作的累积性是没法解决上面的问题。
不过我还是留有疑问,前面是在考虑 smp_mb() 仅具备 program order 屏障效果的前提下得出的结论,但是 smp_mb() 作为一个累积性屏障(不只是保证 program order,见速查表,也具有 C 性质)为什么不足以保证 r3=1?只提供一点线索,我后面再琢磨:作者在 Quick Quiz 15.26 表示 P2: smp_mb() 只会确保其中一个 load-store 链路传播有序(示例共有 2 条路径:一条是 z 的读写,从 17 行到 24 行;另一条是 x 的读写,从 26 行到 7 行),所以还需要 Listing 15.19 在 P0 再设 smp_mb。
UPDATE: 我想了想,这都时间错乱了,就算是保证 program order 都不能假定任何事情,所以还指望通过「假设 A 做了什么操作,然后 B 怎样怎样」的方式去理解问题是不对的。还是从工具入手吧。
 herd7 的可视化结果
herd7 的可视化结果
上图是 herd7 使用 -show prop -showinitrf true 选项的可视化结果。先补充一些名词:
- po:表示 program order,即线程内的指令顺序。release 操作和 smp_mb 屏障 的 C 性质(cumulativity)由 po 和 rf 关系共同构成,并且后续 P 性质进一步用于限制 fr 关系的构成。
- rf:表示 read-from 关系,同一个变量的写操作指向读操作,操作之间具有先后关系,也就是读到指定的写提供的数值。简单点可理解为 exists 子句所指定的范围(没指定就由程序枚举状态)。
- fr:表示 from-read 关系,同一变量的读操作指向(将覆盖当前数值的)写操作,由于作为汇点的写操作传播过晚,并不影响到作为源点的读操作结果,也就是说这种关系允许「时间倒流」,因为执行顺序和得到的结果是反向的,见上方的 15.12 图。
NOTES:
- 实际上还存在 co 关系:表示写操作之间对数值达成一致的顺序(即 write-write coherence)。
- fr 关系和 co 关系的联系:\(fr = (rf^{-1} ; co)\)。
- 这里由于只有初始状态到首次写操作才具有 co 关系,所以图里是隐藏看不见的。也可以使用
-showinitwrites true 显示出来。
- co 关系也可以做到「时间倒流」。因为 store 操作的执行是面向 store buffer,而这与传播到 cache 的先后顺序并没有关系,cache 达成一致的顺序要取决于 store buffer 的刷新传播。
根据一些文档的解释,这里的问题是存在 from-read 环:从顶点 a 出发,顺着有向边一直走到顶点 f,然后再回到顶点 a。而只有破坏(禁止)掉这种环才可以满足一致性的要求。可以类比到 cache coherence 规则:它使用 rf、co、fr 和 po-loc 关系来描述四种 coherence 性质并且不允许形成环,因为环的存在就是对一致性的自相矛盾。但是图里还多了 po 关系而不是 po-loc 关系(后者用于间接描述 read-read coherence,loc 指的是同一位置),它的存在使得这种 from-read 环成为可能。并且可以看出,Quick Quiz 15.26 指的两条 load-store 链路就是 fr 关系(构成的环),而 smp_mb() 的 P 性质能禁止所在的链路构成环,因此(以同一位置的 store 操作为源点,load 操作为汇点)e->f->a->d 和 a->f 两个环都需要 smp_mb() 屏障,合适的位置可能是 store-z 操作后(e->f 之间)和 store-x 操作后(a->b 之间)。
修复后的 C-W+RWC+o-mb-o+a-o+o-mb-o 示例
C C-W+RWC+o-mb-o+a-o+o-mb-o
{}
P0(int *x, int *y)
{
WRITE_ONCE(*x, 1);
smp_mb(); // 使用 P 性质禁止传播构成环
WRITE_ONCE(*y, 1);
}
P1(int *y, int *z)
{
int r1;
int r2;
r1 = smp_load_acquire(y);
r2 = READ_ONCE(*z);
}
P2(int *z, int *x)
{
int r3;
WRITE_ONCE(*z, 1);
smp_mb();
r3 = READ_ONCE(*x);
}
// **不会**触发
exists(1:r1=1 /\ 1:r2=0 /\ 2:r3=0)
所以速查表的 P 性质到底是什么意思?
其实我也不太懂。字面含义是保证传播有序,而「有序」在这里是指代不存在环的场景,所以这种性质仍是用于禁止特定关系(传播)所构成的环。传播可以由 co 和 rf 关系定义,但是实际定义的 propagates-before 关系远没有这样简单,因此作者在 Quick Quiz 15.26 也只是很粗略地用 rule of thumb(给人用的规则)去解释。不管怎么说,它的承诺就是传播不构成环。
这个解释巨长的例子说明什么?至少对我来说是「parallel programming is still hard」。但是更需要知道的是面对这种问题「我能做点什么」:翻文档、用工具,还有不要这样写。
TBC
补充完 RCU 以后,更新速度会放缓,有新的内容也会直接在本文更新。
最后更新于:2024/09/05
END
感觉目前内容补充得差不多了。perfbook 算是我看过最掉头发的书本之一,留有疑问的地方我后续可能会花点时间去修订。
总之先这样吧。
最后更新于:2024/09/11

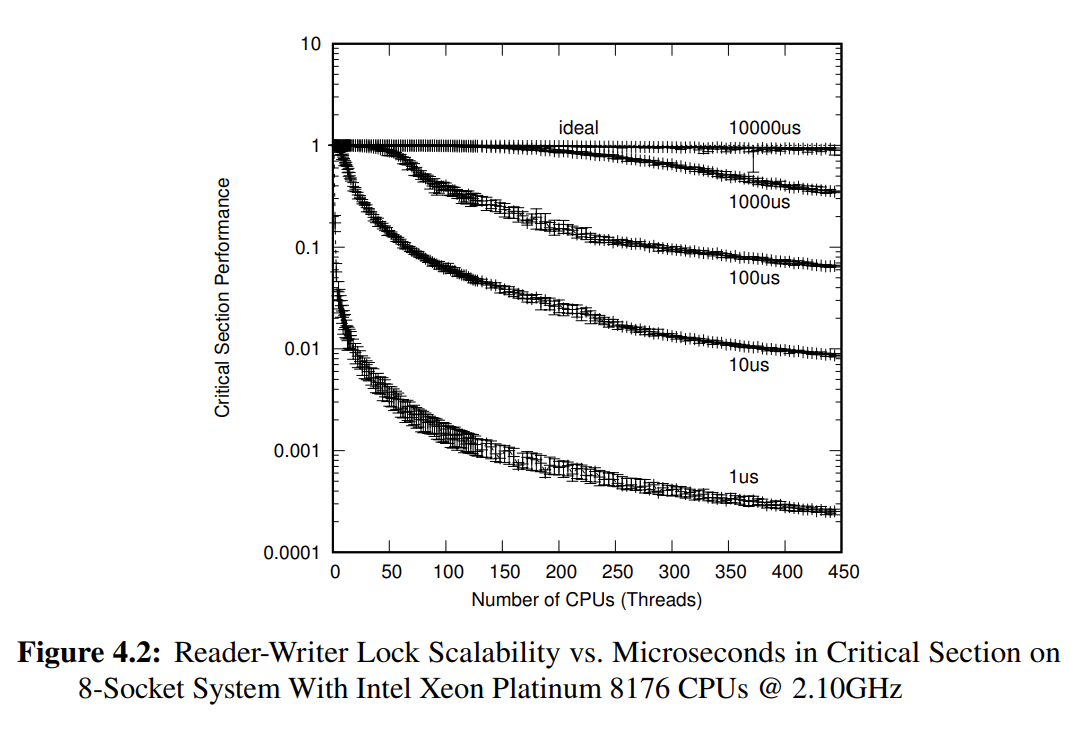
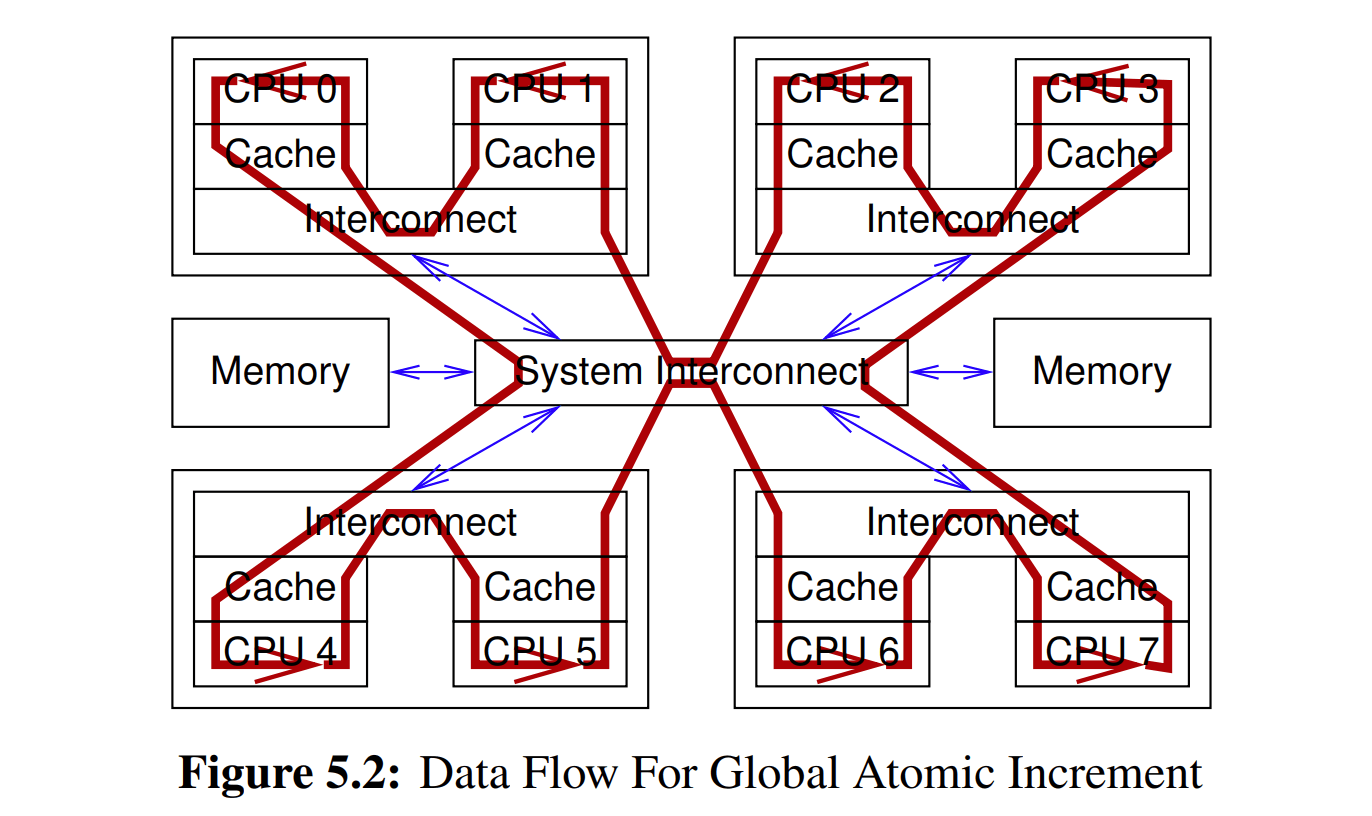 引起洪荒的原子操作
引起洪荒的原子操作
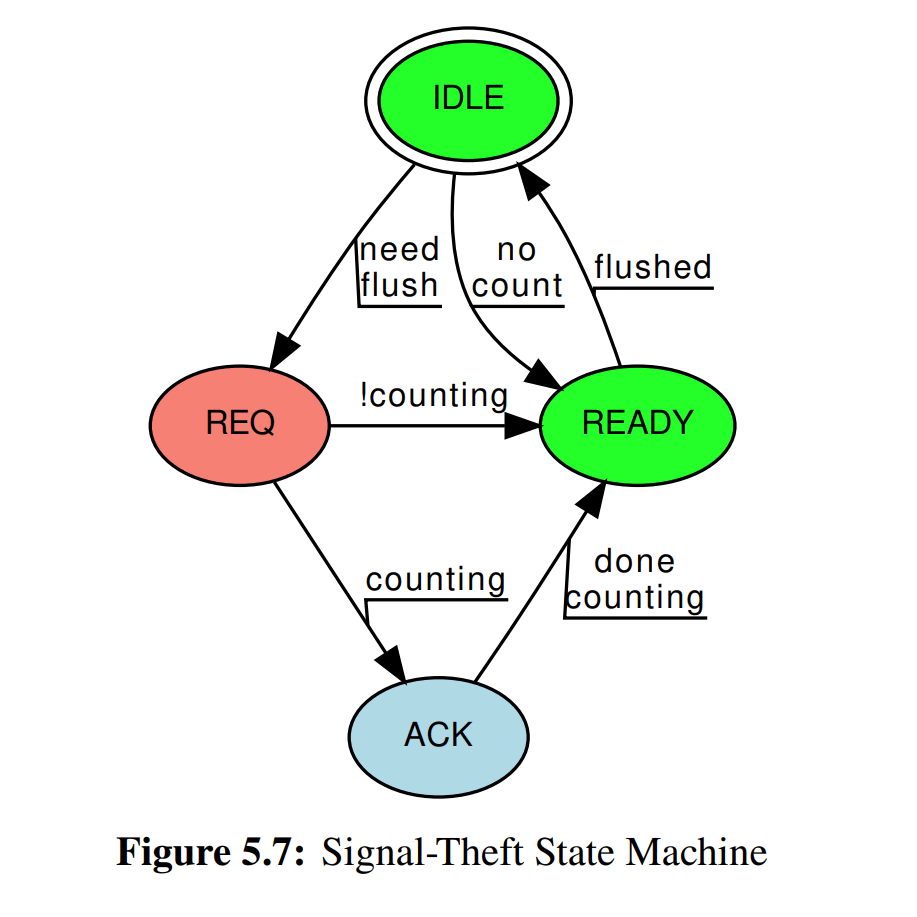
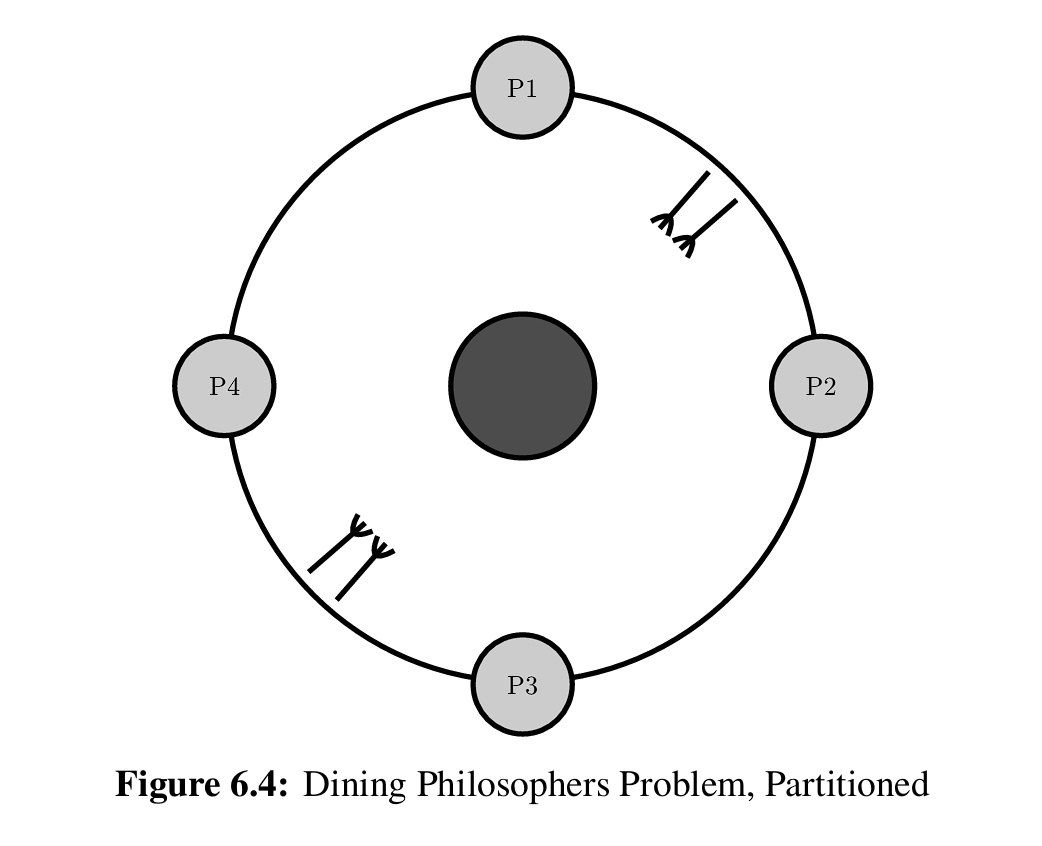
 注意地板藏着一条直线(没想到吧)
注意地板藏着一条直线(没想到吧)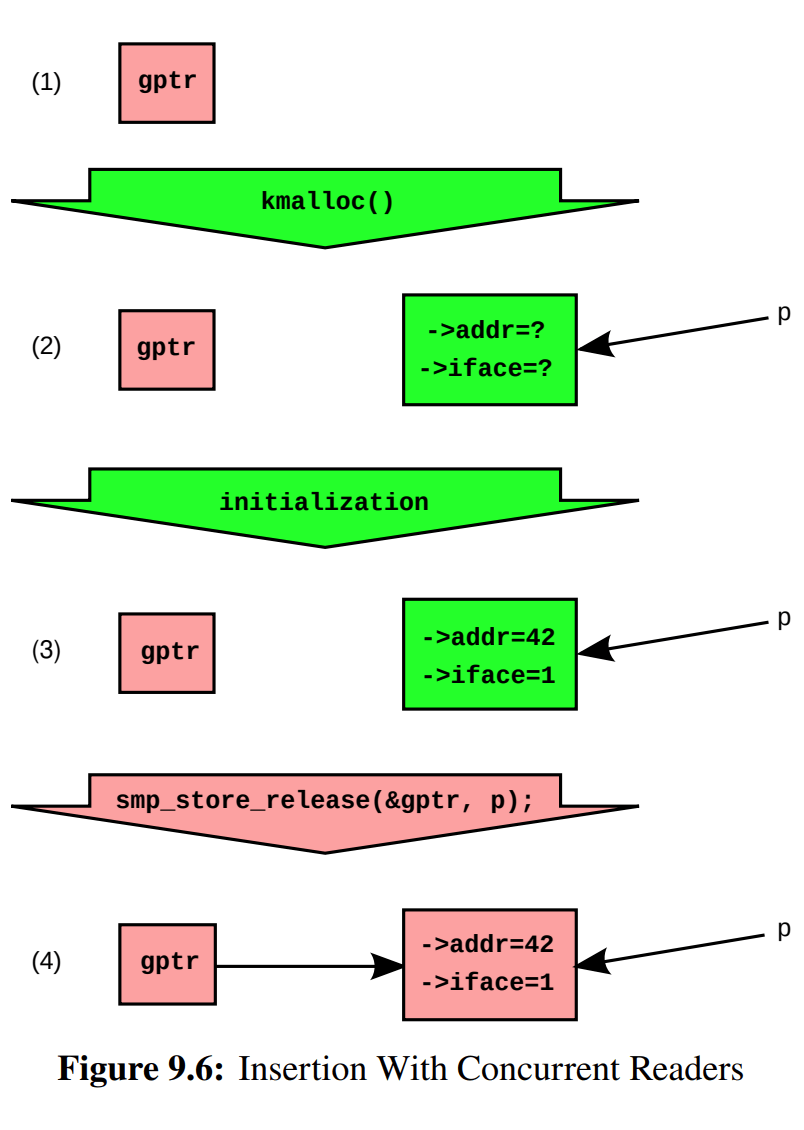
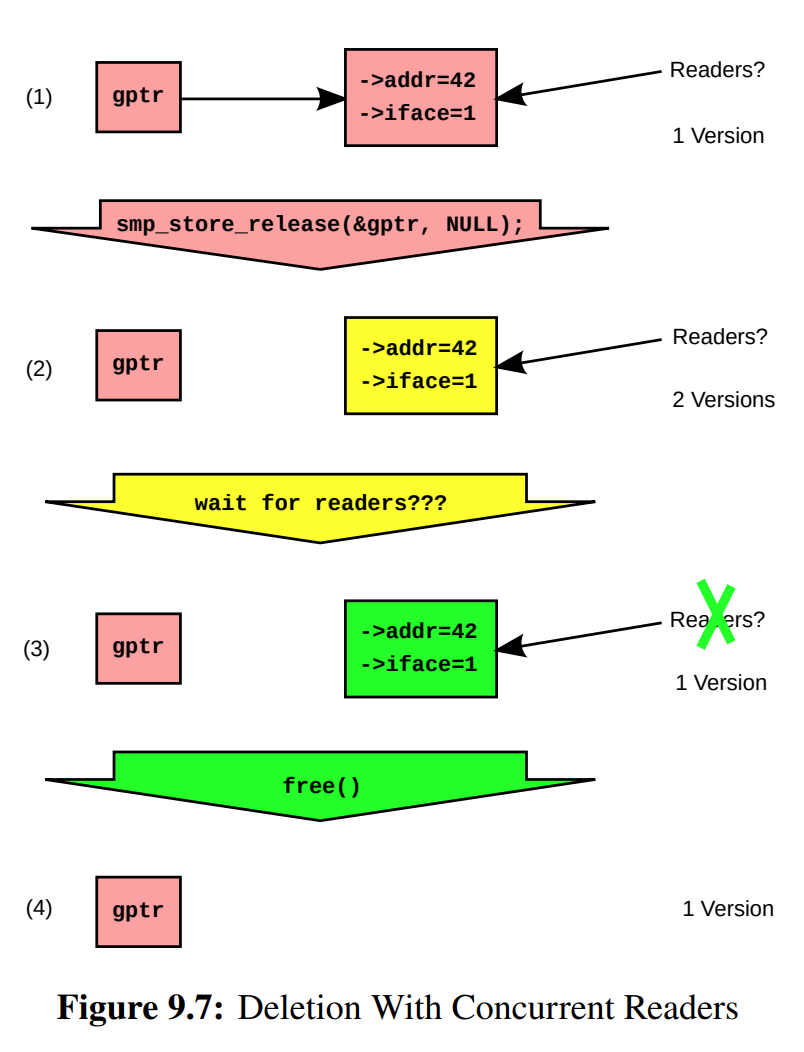
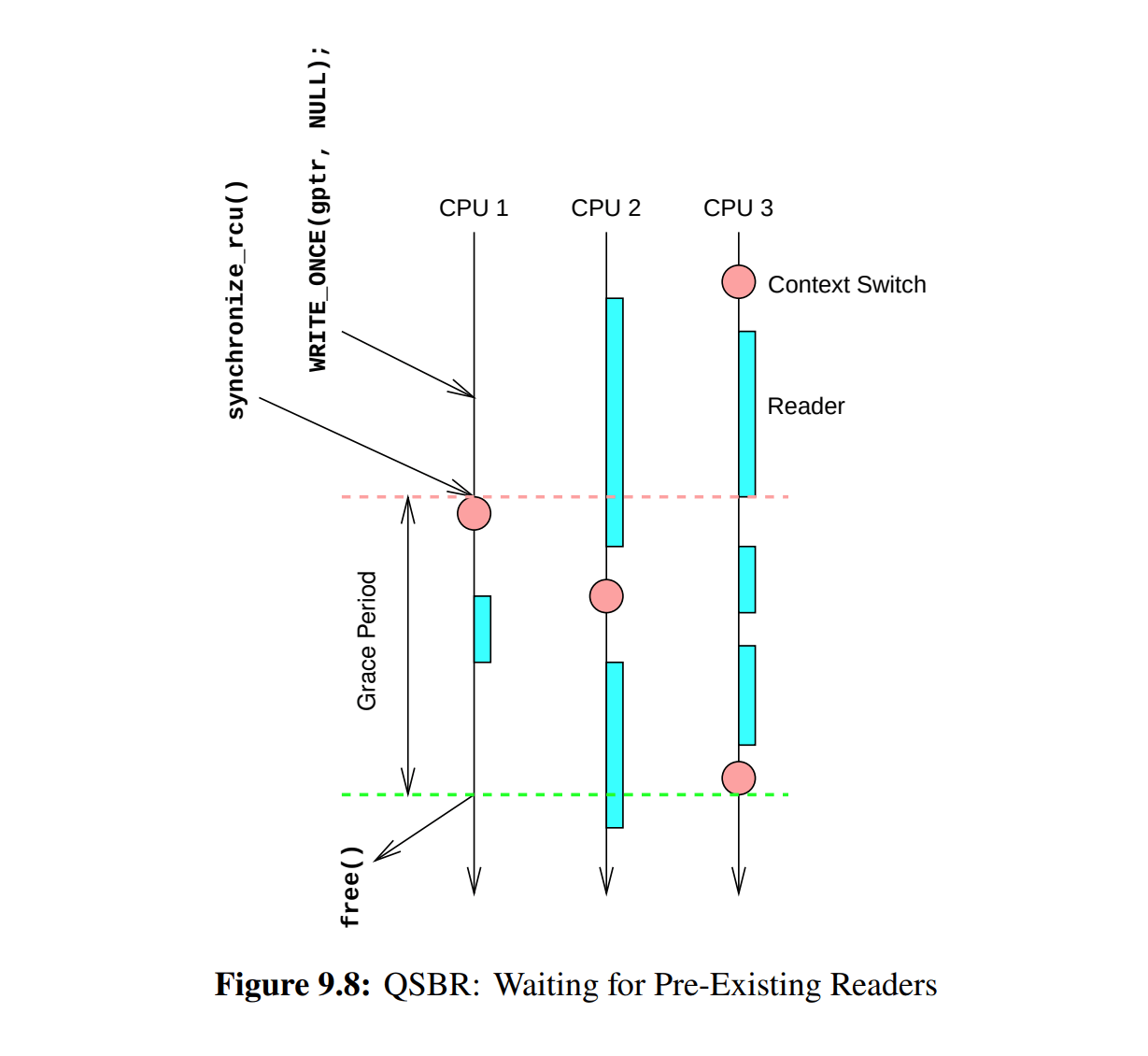
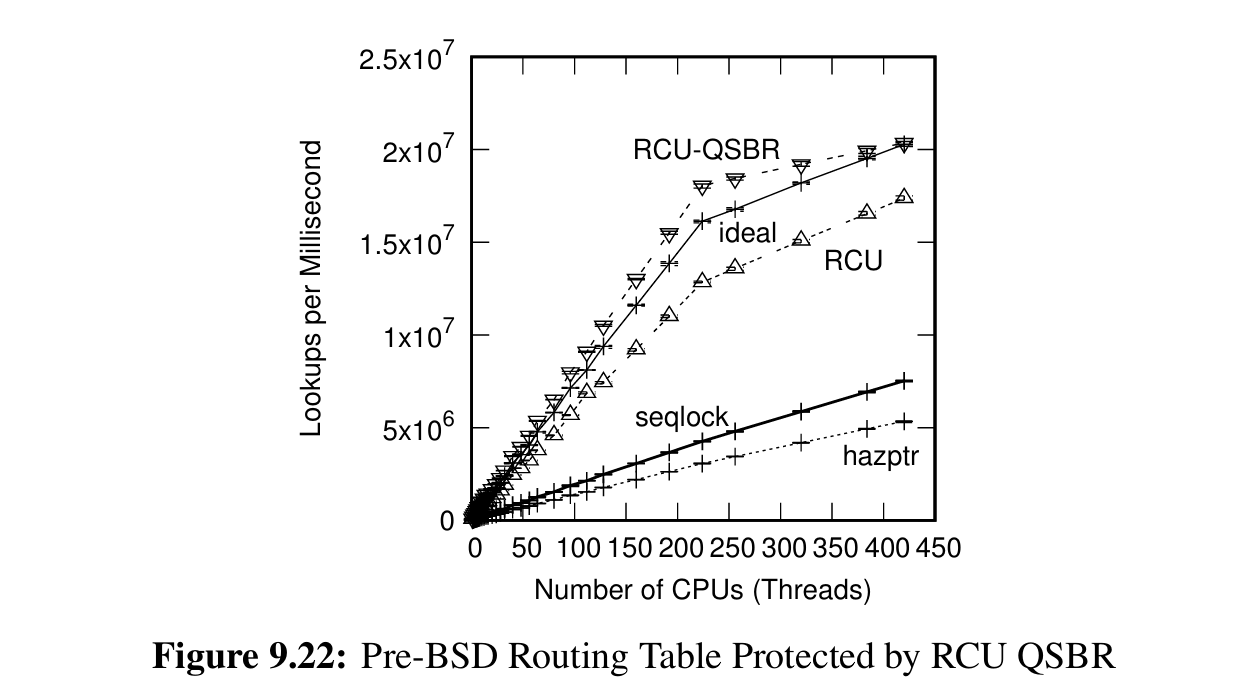

 读者订阅与写者发布并行的遍历过程
读者订阅与写者发布并行的遍历过程 初始存在两个桶,后续扩容到四个桶
初始存在两个桶,后续扩容到四个桶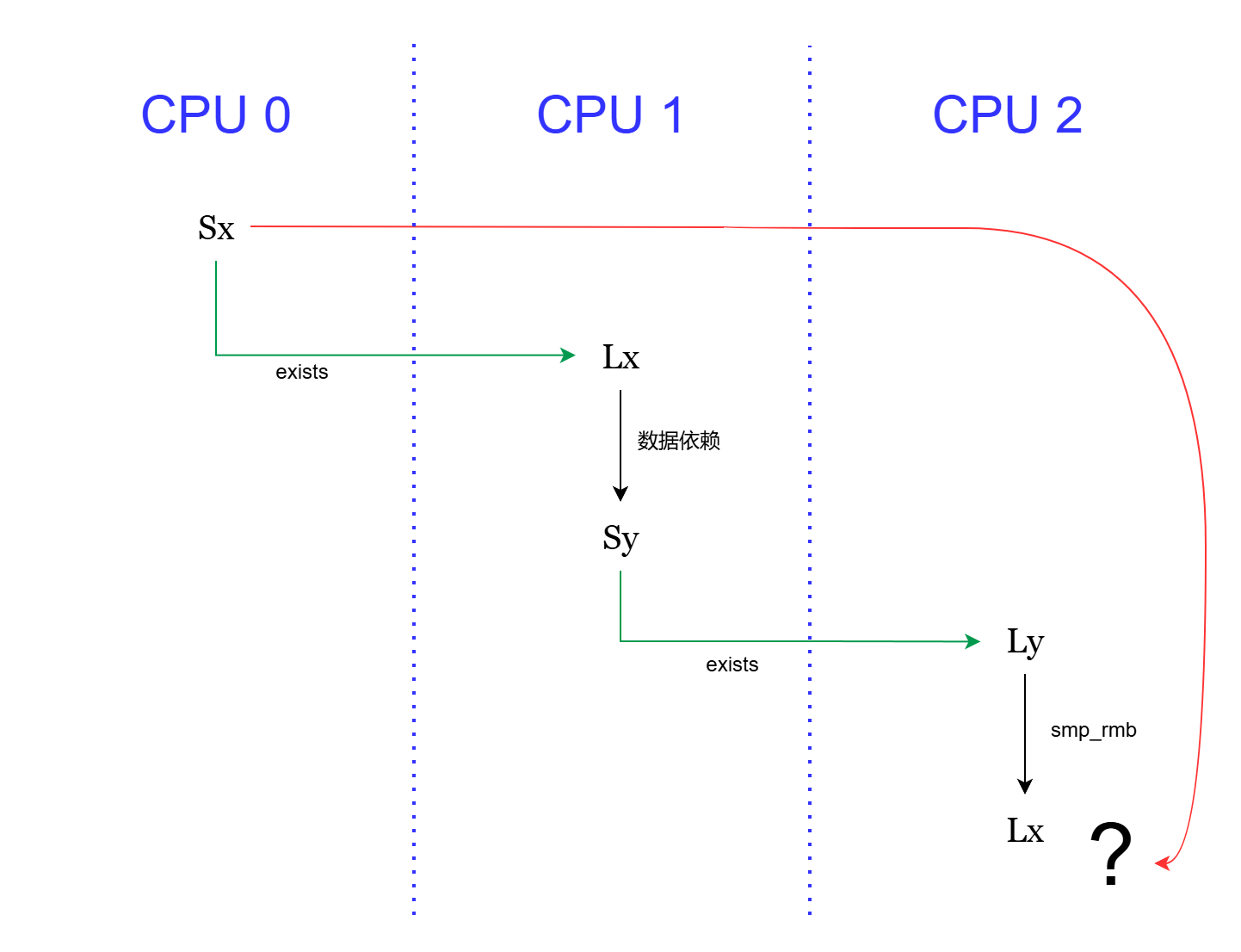 只有黑线是确定顺序的,绿线可根据 (1:r1=1 /\ 2:r2=1) 推断出来
只有黑线是确定顺序的,绿线可根据 (1:r1=1 /\ 2:r2=1) 推断出来 蓝色的屏障挡住 CPU 0 到 CPU 2 的 store x 乱序
蓝色的屏障挡住 CPU 0 到 CPU 2 的 store x 乱序 from-read 可以做到「时间倒流」
from-read 可以做到「时间倒流」 herd7 的可视化结果
herd7 的可视化结果