前言
Intel 提出了一种基于微架构视角的性能分析方法,称为TMAM (Top-down Microarchitecture Analysis Method)。虽然听似屠龙大刀,但其实用起来比水果刀还简单。这种方法不仅可以辅助分析看不出的“热点中的热点”,而且可以对 CPU 微架构有进一步的了解,值得学习。
论文标题及链接:A Top-Down Method for Performance Analysis and Counters Architecture。
微结构介绍
 微架构简化图示
微架构简化图示
现代 CPU 的流水线非常复杂,但是从抽象的角度可以将其拆分为两个部分:前端(frontend)和后端(backend)。前端负责内存取指(fetch instructions from memory)和转译微码(translate them into micro-operations / uops)。转译后得到的微指令将被馈送到后端部分。后端负责对每个微指令进行调度(schedule)、执行(execute)和提交退役(commit / retire)。这种生产 - 消费的流水线模型就是使用队列(“ready-uops-queue”)来缓存微指令,以待后端消费。
古法停滞预估
有一种对 CPU 停滞(stall)预估的传统办法,就是预设不同的丢失事件(cache miss, branch miss…)对应不同的惩罚时间,统计次数然后累加上去:
\[Stall\_Cycles = \sum_i Penalty_i * MissEvent_i\]但这种办法在现代乱序 CPU 中并不凑效。原因很多:
- 停滞叠加:不同单元的工作是可以并行的。
- 投机执行:错误的投机路径实际应(相比正确路径)使用更低停滞权重。
- 负载依赖:惩罚时间需要看当前的负载,而不是固定的值。
- 预设事件限制:微架构细节众多,但硬件只能统计多数丢失事件。
- 超标量误差:CPU 可以在一个周期延迟内并行完成流水线操作,应用更需关注流水线带宽。
这促使性能分析要回归到微架构本身来解决这种错误的统计方式。
自顶向下分析

自顶向下进行了层级划分,比如第一层就划分为四种类型:
- Frontend Bound.
- Bad Speculation.
- Retiring.
- Backend Bound.
先不管具体定义,通过示例可以知道自顶向下的快速定位用法:
- 假设存在一个未知的性能瓶颈,分析器反馈 Backend Bound 标记。
- 往 Backend Bound 子树分析(无视同层其它子树),反馈 Memory Bound 标记。
- 往 Memory Bound 子树分析(无视 Core Bound 子树),反馈 L1 Bound 标记。
最终可定位为 L1 瓶颈,因此你只需关注这一领域就能解决性能问题。
并且作者说这种方法具有“安全网络”的特性。比如当你进行 Level 3 的分析时,可能反馈得出 L1 Bound 和 Divider 同时标记(PMU 同时统计),但因为此前已在 Level 2 确定了是 Memory Bound 而非 Core Bound,所以可以无视 Divider 标记,从而得到正确的 L1 瓶颈。
工作原理
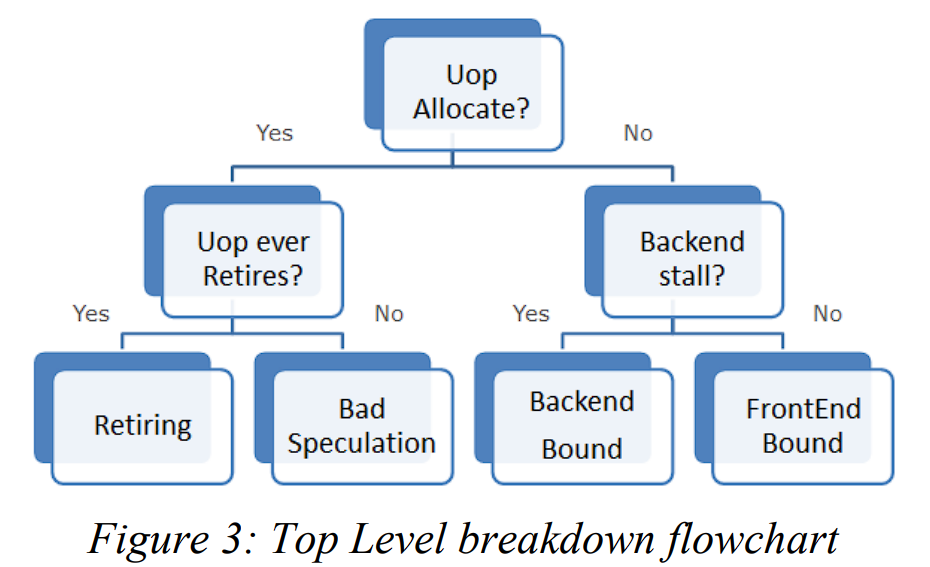
其实自顶向下方法是基于流水线槽(pipeline slot)的特性来进行划分的,比如第一层就是每个流水线槽被精确地分为上图的四类之一。
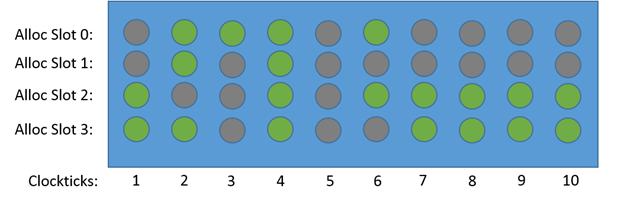 四宽度 CPU 的流水线槽示意图,这里有 20 个槽处于停顿状态
四宽度 CPU 的流水线槽示意图,这里有 20 个槽处于停顿状态
A pipeline slot represents hardware resources needed to process one uOp.
对于一个投机执行的 CPU 来说,已经发射的 uop 只有两种命运:正常退役、或者因错误投机而被取消。
而 Backend stall 指的是虽然前端可以处理更多 uop,但是后端认为此时没有合适的消费时机(比如 load buffer 不够用,见微架构图示),使得没法继续执行。并且作者认为后端重要性高于前端,因此判断条件就是按 Backend stall 优先处理。
往下的章节就是各个分类的详细说明,包括问题原因和优化建议,推荐搭配图 2 阅读。
Frontend Bound
Frontend Latency Bound 是 i-cache miss、i-TLB miss 或者 Branch Resteers 问题所造成的。其中我个人对 Branch Resteers 的理解是因为投机错误后流水线刷新需要重新取指,这就导致了前端的延迟。(这种情况也和 Bad Speculation 关系很大,可能重叠统计)
Frontend Bandwidth Bound 反映了指令解码效率过低(也就是转译阶段存在问题)。这种情况会发生在高 IPC 的场合下,或者是使用了特殊的指令(CPUID)。
要解决前端问题是需要增加额外硬件的(除了 i-cache miss 和 i-TLB miss),比如 Intel 在 Sandy Bridge 家族引入了 Decoded-uop Stream Buffer。正是因为它太“硬”了,软件无法干涉,因此在前面的图 3 中是仅当 Backend 没有问题时才显现。
NOTE: 看来买个好点的 CPU 也是一种优化手段啊!
Bad Speculation
Bad Speculation 反映了因错误投机而导致流水线槽的浪费。
Branch Misspredict 很常见,就是程序实现的控制流对 CPU(或者说是分支预测器)不够友好,也可能是编译器实现不佳导致的。解决办法是手动消除间接分支和使用 PGO 选项(profile-guided optimization),或者……换个编译器版本试试?
Machine Clears 说的比较含糊,typically unexpected situations,不清楚啥意思,也没有建议。
Retiring
Retiring 达到 100% 则意味着拥有了 CPU 理论最高的 IPC 值。
Retiring 高占比也并非没有优化空间。作者给了一些建议:
- 考虑避免 Microcode sequences 中的 FP assists,有些浮点操作并没办法放入到流水线中而必须使用 Microcode。这个指标放到 Micro Sequencer 供人参考。
- 考虑使用向量化实现来替代 Retiring 高占比的非向量化代码。本质是让单个 uop 干更多事情。
Backend Bound
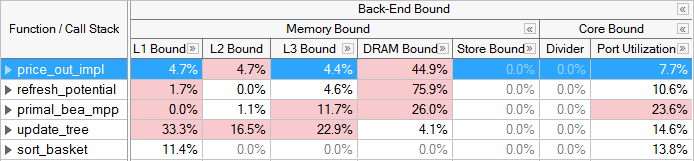 VTune 官网的截图
VTune 官网的截图
大多数未调优的应用程序是处于后端瓶颈的情况。
Backend Bound 可进一步划分为 Memory Bound 和 Core Bound。划分方式是基于执行单元(execution unit)在每周期时的占比,只要有任意一个周期没有拉满执行单元(比如四发射的流水线,此时只有 3 个 uop 被执行),这个周期就认为是执行停滞(ExecutionStall)。
Core Bound 是非(重度)内存访问引起的执行停滞,可理解为计算资源未被充分利用。其中 Divider 指的是除法器的使用指标,可能是一个长延迟的除法操作(导致串行执行)相关;而 Execution Ports Utilization 用于识别离散计算的执行单元竞争程度。解决办法就是更好的代码生成,尤其是算法。无依赖的算术操作和向量化都是优化方向。
Memory Bound 是内存访问(缓存也算入)引起的执行停滞。通常的原因是 data-cache miss,比如一个 load 操作没有命中到任何 cache。基本建议就是考虑局部性还有避免指令依赖于内存访问(让乱序调度器更好的调度 uop)。再补充点实用建议:store 操作一般不影响性能,但多线程下 Stores Bound 可能是伪共享(false sharing)引起的,考虑局部性就是解决方法;另外,MEM Latency 作为瓶颈则需要考虑预取操作,这部分见论文中的案例展示章节。
NOTE: Memory Bound 可能还需要进一步讨论。比如 store forwarding,4K aliasing 等复杂案例,有空再找下资料。
理想的数据范围
Intel 实验室给出了不同场合下已调优程序的指导阈值:
| Category | Client/Desktop Application | Server/Database/Distributed application | High Performance Computing (HPC) application |
|---|---|---|---|
| Retiring | 20-50% | 10-30% | 30-70% |
| Back-End Bound | 20-40% | 20-60% | 20-40% |
| Front-End Bound | 5-10% | 10-25% | 5-10% |
| Bad Speculation | 5-10% | 5-10% | 1-5% |
NOTE: 这不是论文部分,但可以在 VTune 文档找到。
计数器架构
这部分主要是列出从性能计数器事件到指标的计算过程,不想看了就简单记录下表格。
Event 表格
| Event | Definition | |-------------------|------------------------------------------------------------------------------------------| | TotalSlots* | Total number of issue-pipeline slots. | | SlotsIssued* | Utilized issue-pipeline slots to issue operations. | | SlotsRetired* | Utilized issue-pipeline slots to retire (complete) operations. | | FetchBubbles | Unutilized issue-pipeline slots while there is no backend-stall. | | RecoveryBubbles | Unutilized issue-pipeline slots due to recovery from earlier miss-speculation. | | BrMispredRetired* | Retired miss-predicted branch instructions. | | MachineClears* | Machine clear events (pipeline is flushed). | | MsSlotsRetired* | Retired pipeline slots supplied by the micro sequencer fetch-unit. | | OpsExecuted* | Number of operations executed in a cycle. | | MemStalls.AnyLoad | Cycles with no uops executed and at least 1 in-flight load that is not completed yet. | | MemStalls.L1miss | Cycles with no uops executed and at least 1 in-flight load that has missed the L1-cache. | | MemStalls.L2miss | Cycles with no uops executed and at least 1 in-flight load that has missed the L2-cache. | | MemStalls.L3miss | Cycles with no uops executed and at least 1 in-flight load that has missed the L3-cache. | | MemStalls.Stores | Cycles with few uops executed and no more stores can be issued. | | ExtMemOutstanding | Number of outstanding requests to the memory controller every cycle. |
Metric 表格
| Metric Name | Formula | |-----------------------|-------------------------------------------------------------| | Frontend Bound | FetchBubbles / TotalSlots | | Bad Speculation | (SlotsIssued – SlotsRetired + RecoveryBubbles) / TotalSlots | | Retiring | SlotsRetired / TotalSlots | | Backend Bound | 1 – (Frontend Bound + Bad Speculation + Retiring) | | Fetch Latency Bound | FetchBubbles[≥ #MIW] / Clocks | | Fetch Bandwidth Bound | Fetch Bandwidth Bound | | #BrMispredFraction | BrMispredRetired / (BrMispredRetired + MachineClears) | | Branch Mispredicts | #BrMispredFraction * Bad Speculation | | Machine Clears | Bad Speculation – Branch Mispredicts | | MicroSequencer | MsSlotsRetired / TotalSlots | | BASE | Retiring – MicroSequencer | | #ExecutionStalls | ΣOpsExecuted[= FEW] / Clocks | | Memory Bound | (MemStalls.AnyLoad + MemStalls.Stores) / Clocks | | Core Bound | #ExecutionStalls – Memory Bound | | L1 Bound | (MemStalls.AnyLoad – MemStalls.L1miss) / Clocks | | L2 Bound | (MemStalls.L1miss – MemStalls.L2miss) / Clocks | | L3 Bound | (MemStalls.L2miss – MemStalls.L3miss) / Clocks | | Ext. Memory Bound | MemStalls.L3miss / Clocks | | MEM Bandwidth | ExtMemOutstanding[≥ THRESHOLD] / ExtMemOutstanding[≥ 1] | | MEM Latency | (ExtMemOutstanding[≥ 1] / Clocks) - MEM Bandwidth |
后记
这是失眠时看的文章,可惜看到一半觉得细节问题太多更睡不着了。昏迷到白天起来又修缮了一点。
其实我个人觉得这是一篇推销 VTune 软件和牙膏厂 CPU 的“广告论文”,不过能学到点方法论也不亏。(如果平台支持,也可以用 perf 进行 top-down 分析,见这篇 wiki。)以后多写点问题代码来练手吧。
References
A Top-Down Method for Performance Analysis and Counters Architecture
CPU Metrics Reference – Intel® VTune™ Profiler User Guide
Top-down Microarchitecture Analysis Method