本文是 Parsing JSON Really Quickly: Lessons Learned 的个人观片笔记,演讲者为 Daniel Lemire(simdjson 作者)。主要内容是分享基本的高性能解析思路,以及早期 simdjson 的具体实现。
一点说明:
- 个人笔记会相对简短,主要是补充作者略过太快的算法细节。
- InfoQ 有演讲的全文记录(English),喜欢原味的同学不要错过!
动机
What I hear a lot - not from everyone, but from enough people - is that they have all these cool AI stuff, but their servers are just spending all their time producing JSON and parsing JSON. I see a few people laughing so maybe this happens to you. It’s kind of silly if you think about it, but that’s life.
总而言之,这就是生活 :)
CPU 瓶颈

JSON 解析的瓶颈在于 CPU。对于朴素实现的 JSON parser,其解析吞吐甚至不到磁盘读取速度的 1/4(比如 RapidJSON),因此一个 JSON parser 的首要任务就是增加 CPU 的吞吐性能。(从后面的做法可以看出,IPC 指标不一定会抬高,因为作者倾向于使用减少指令数的实现。)
基本思路
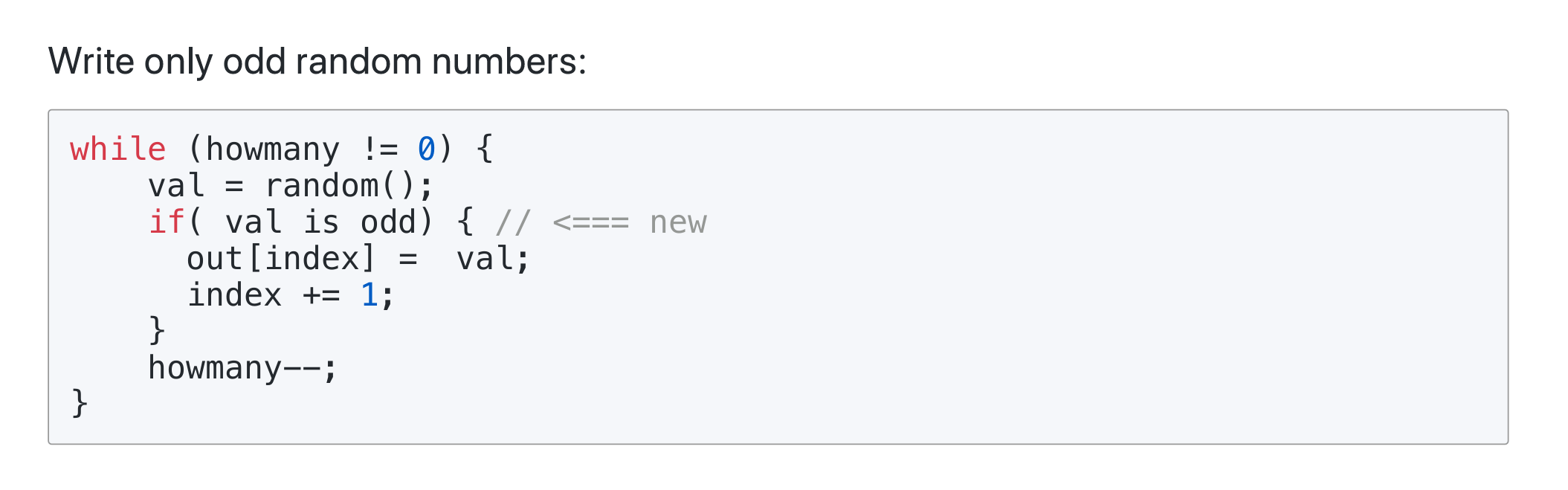 预测不友好的代码,需要 15 个周期的开销
预测不友好的代码,需要 15 个周期的开销
 预测友好的代码,降为 4 个周期的开销
预测友好的代码,降为 4 个周期的开销
提高性能的思路很简单:
- 避免难以分支预测的代码。也就是在高随机场景中使用无分支编程。
- 使用「宽字」(wide words)处理。按字节处理的算法尽量尝试使用 SIMD 替代。
- 避免内存分配。simdjson 的 DOM 对象都有自己的内存池,增强局部性。
- 跑分驱动开发,部署 CI 等等……
都学会了吧,那就来看场景分析!
场景一:UTF-8
 分支极多的 UTF-8 验证方法
分支极多的 UTF-8 验证方法
JSON 解析的步骤之一就是验证 UTF-8,以避免将垃圾丢进数据库。但是 UTF-8 编码是变长的,因此分支极多。
// Example: Verify that all byte values are no larger than 244
// Saturated subtraction: x - 244 is non-zero if an only if x > 244 .
_mm256_subs_epu8(current_bytes, 244 );
// One instruction, checks 32 bytes at once!
作者使用的优化方法很多。其中一个观察是:标准 Unicode 中,不会有任何字节超过 244 数值。因此使用 SIMD 饱和减法即可快速判断,也就是说,向量减去 244,还有大于 0 的数值即为非法。
结论:与常规分支实现相比,使用 20 条左右的 SIMD 无分支指令可以提高 20 倍性能。
场景二:字符分类
字符分类指的是处理 ','/':'/'[]{}'/' ' 这些有特殊意义的字符,比如标记它后续会映射到一个 JSON array 等等用途。
 ARM NEON 实现的字符分类
ARM NEON 实现的字符分类
ARM NEON and x64 processors have instructions to lookup 16-byte tables in a vectorized manner (16 values at a time): pshufb, tbl
作者在这里应用 SIMD 结合查表法去 shuffle。首先将每个字节拆分为两个半字节(nibble),又因为每个半字节只有 16 种可能性,而 16 则刚好可以塞进 SIMD 运算当中作为掩码表。
// 作者设计好的枚举值
brackets (0x5b,0x5d, 0x7b, 0x7d): 1
comma (0x2c): 2
colon (0x3a): 4
most white-space (0x09, 0x0a, 0x0d): 8
white space (0x20): 16
others: 0
所以通过精心设计的掩码表,构造出类似 table1[lo] & table2[hi] 的算法后,只需得到的枚举值结果足以区分不同类型的字符即可。
table1[lo] & table2[hi]
=> table1[0xc] & table2[0x2]
=> 2 & 18
=> 2
以标量为例,',' 的数值为 0x2c,拆分后 0x2为高半字节 hi,0xc 为低半字节 lo。查表后得到 2,对应于 comma 的枚举值。
结论:字符分类能通过 shuffle 技巧做到无分支的向量实现。
场景三:转义检测

(这一块我看演讲都要搞晕了……)
转义就是类似 \" 👉 \\\" 的概念,而 parser 也是要处理转义符的。作者发现一个重要性质:被转义的符号前面肯定是奇数个反斜杠。借助这个性质可以实现对应的 SIMD 运算,单次无分支地处理 32/64 个字符。
Identify backslashes:
{ "\\\"Nam[{": [ 116,"\\\\"
___111________________1111_: B
通过 set1(\) 和 cmp 即可完成上述操作,得到 B 向量
Odd and even positions
1_1_1_1_1_1_1_1_1_1_1_1_1_1: E (constant)
_1_1_1_1_1_1_1_1_1_1_1_1_1_: O (constant)
预设好的 E 和 O 常数向量
Do a bunch of arithmetic and logical operations...
(((B + (B &~(B << 1)& E))& ~B)& ~E) | (((B + ((B &~(B << 1))& O))& ~B)& E)
位运算领域大神!
Result:
{ "\\\"Nam[{": [ 116,"\\\\"
______1____________________
No branch!
第三步有点疯狂,作者也没多说什么。不负责地分析(猜测)一下:
- 对于一个字符串来说,它共有四种字符集:奇数位反斜杠、奇数位非反斜杠、偶数位反斜杠、偶数位非反斜杠。因此 B 代表的是
奇数位反斜杠 | 偶数位反斜杠的字符集,~B 代表的是奇数位非反斜杠 | 偶数位非反斜杠的字符集。 - 对于算式来说,左半侧
& ~E必会使得偶数位结果归零,右半侧& E必会使得奇数位结果归零。所以我们能得到的贡献只能是来自于两侧(B + 一坨)所带来的进位(carry)。 - 对于左半侧的「一坨」,即
(B &~(B << 1)& E)指的是非连续的偶数位反斜杠。「连续」指的是偶数位和与之高一位的奇数位同时是反斜杠。这样后续能消除掉偶数个数对。 - 对于左半侧完整的
(B + (B &~(B << 1)& E)) & ~B,指的是只允许「非连续的偶数位反斜杠」且「与之高一位的必须是奇数位非反斜杠」才能进一位。所以它能匹配到转义后(奇数个≈非连续)的引号(非反斜杠)。 - 右半侧是对称的,就不重复分析了。
NOTES:
- 步骤 3 应该是右移一位(个人觉得),可能作者实际使用的字节序是相反的;
- 步骤 4 当中的 ~B 总感觉有点多余?
不管怎么说,总之找到转义引号了!

{ "\\\"Nam[{": [ 116,"\\\\"
__1___1_____1________1____1: all quotes 通过 set1(") 搞到手
______1____________________: escaped quotes 前面我们算出来的
__1_________1________1____1: string-delimiter quotes 然后一起 xor
再一次 SIMD。通过 set1(“) 和 cmp 操作,我们又得到了标记所有引号的向量。再由上面的求出的转义引号向量一块异或,就能得到每个真实字符串的起始和末端!
输入法打 yihuo 会冒出颜文字啊 (・∀・(・∀・(・∀・*)
mask = quote xor (quote << 1);
mask = mask xor (mask << 2);
mask = mask xor (mask << 4);
mask = mask xor (mask << 8);
mask = mask xor (mask << 16);
__1_________1________1____1 (quotes)
becomes
__1111111111_________11111_ (string region)
最后来一点位移运算就能搞到字符串区域。
// 并行的前缀和算法
for(auto l = 0; l < log2[n]; l++)
for(auto i = n-1; i >= 0; --i)
mask[i] += mask[i - (1<<l)];
其实熟悉并行计算的话可以看出这是前缀异或和的算法,类比到前缀和的话差不多一个意思。
作者也提到上述操作实际只要一条指令就能实现。(即 clmul 无进位乘法,作者在油管评论中指出。)
结论:整个 JSON 文档的解析都可以无分支实现。
场景四:数字解析
作者通过跑分确认 strtod 具有大量 branch miss,且是解析过程的性能瓶颈(90 MB/s)。
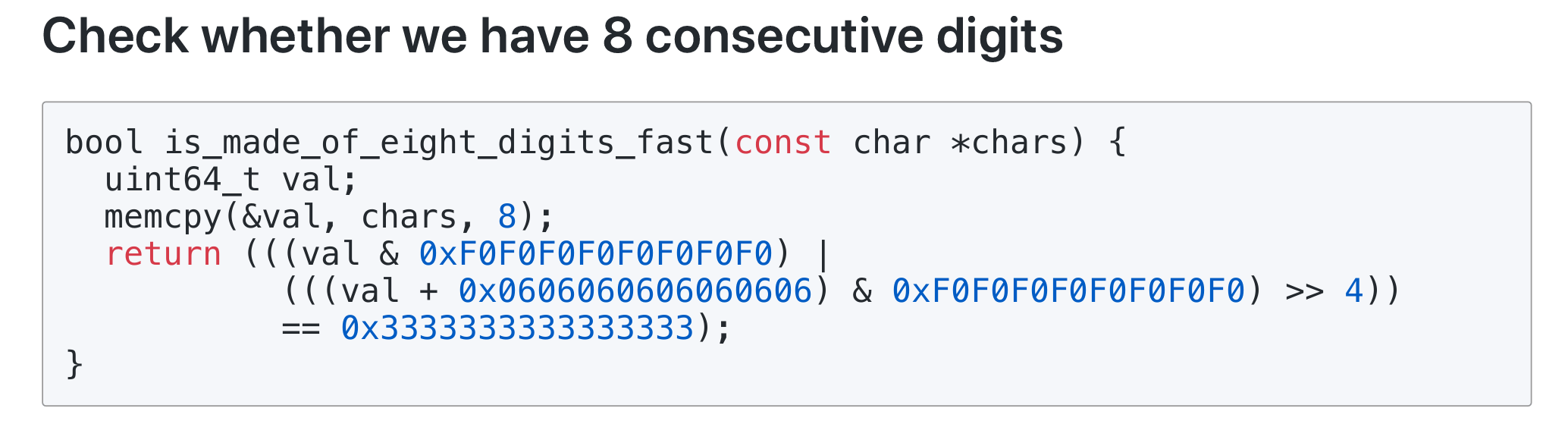 批处理 8 次的 isdigit 加强版
批处理 8 次的 isdigit 加强版
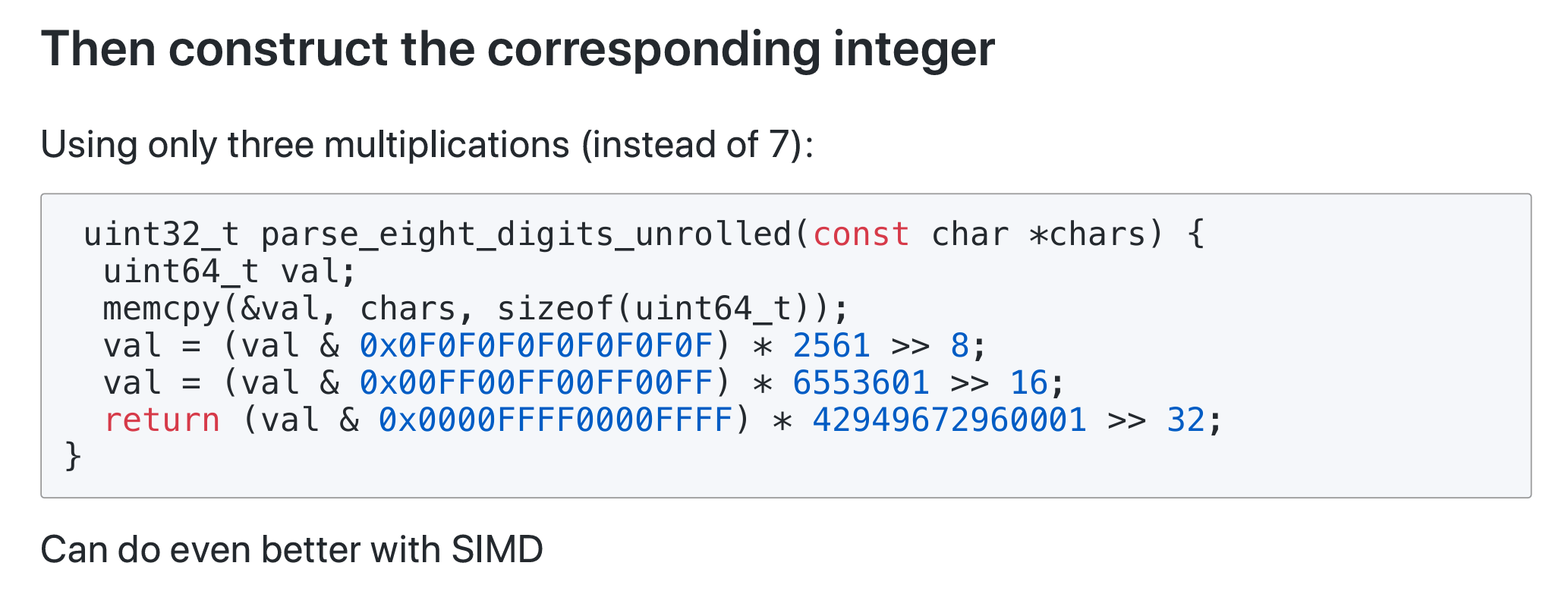 无分支的数值转换
无分支的数值转换
要改进它只需使用一些计算上的技巧。不过作者也是没有细说,还是自己动手吧。
// 转为标量后:
((val & 0xf0 ) | (((val + 0x06) & 0xf0) >> 4)) == 0x33
// 继续拆分,
// 左半侧等价于:
(val & 0xf0) == 0x30
// 右半侧等价于:
(((val + 0x06) & 0xf0) >> 4) == 0x03
is_made_of_eight_digits_fast 化简标量后就是上述公式。观察到 Unicode/ASCII 码中 '0'-'9' 对应于数值 [0x30, 0x39],也就是高半字节必然是 0x3,低半字节范围是 [0x0, 0x9]。显然,左半侧就是用于判断高半字节;而右半侧通过计算得知 [0x30, 0x39] + 0x06 = [0x36, 0x3f],对该集合右移 4 转换为低半字节后总能得到 0x03,这是为了避免对非数字的 [0x3a, 0x3f] 产生误判。
// parse digits 的初步拆解(先不管 mask)
// 需要注意拆解后其实增加了加法运算,而且位运算的操作数会更多
val = ( ((val & mask1) << 8 ) * 10 + (val & mask1) ) >> 8
val = ( ((val & mask2) << 16) * 100 + (val & mask2) ) >> 16
val = ( ((val & mask3) << 32) * 10000 + (val & mask3) ) >> 32
至于 parse digits 部分……虽然 2561、6553601 和 42949672960001 这些数字有点哈人,但是可以联想到 256、65536 还有 4294967296,它们分别是 \(2^8\)、\(2^{16}\) 和 \(2^{32}\)。进行简单的算式拆解后,可以得知这些数值不仅使得朴素实现的 7 次乘法指令降低为 3 次,也能让加法和位运算的操作数更加少。
mask1 = 0x0f0f0f0f0f0f0f0f
mask2 = 0x00ff00ff00ff00ff
mask3 = 0x0000ffff0000ffff
前面我们说过,Unicode/ASCII 码中 '0'-'9' 对应于数值 [0x30, 0x39]。因此转换为 0-9 整数的方法就是使用 & 0x0f 获取低半字节 [0x00, 0x09],
这也对应于第一个掩码 mask1。注意单字节只是独立的一位数,现在需要处理双字节(两位数)。所以要通过左移 8 将十位 digit 放入到高 8 位(bit,小端)的个位 digit 上,这需要乘上 10 再与原个位数相加;随后结果都存放在个位 digit 对应的字节上;最后右移 8 位抹去已经无用的十位(并且保证后续作为整数的正确表示)。随后的 mask2 和 mask3 是类似的四位数、八位数掩码,就不分析了。
结论:数字解析也可以做到无分支实现!
THE END
还有一些小场景就不摘录了,都是在把玩位运算。有机会就多看点《黑客的高兴》吧,前人许多精妙的算法都帮大家归纳好了,也不要套一层 SIMD 外皮就不认识了。
最后不得不感叹 lemire 大神的水平是真高啊。