前言
这篇文章简单介绍一下最近写的小项目 uring_exec。它适配 liburing 到 stdexec,并且可以作为一个基于 io_uring 和 sender/receiver 的网络库去使用。
uring_exec 具体提供以下特性:
- 适配到 NVIDIA stdexec 的 sender factory;
- 可扩展的动态线程池;
- 以及每个 I/O 操作的取消点(打断)支持。
- (当然了,结构化并发本来就支持。)
性能不算重点(至少基准测试能强于 Asio),本文的主要目标还是适配使用和实现要点。Part A 告诉你一个基于 std::execution 的 sender/receiver 网络库可能是长什么样的,Part B 讨论如何为一个通用的库适配到 std::execution 当中。
NOTE: 我之前翻译过一篇关于 C++26 std::execution 的介绍,不了解背景的读者请务必查阅一下。
适配使用
sender/receiver
// An echo server example.
using uring_exec::io_uring_exec;
// READ -> WRITE -> [CLOSE]
// <-
stdexec::sender
auto echo(io_uring_exec::scheduler scheduler, int client_fd) {
return
// 分配缓冲,是否在栈上取决于你怎么发射任务
stdexec::just(std::array<char, 512>{})
// 使得缓冲(`buf`)在整个异步作用域内可访问
| stdexec::let_value([=](auto &buf) {
// 先读后写,不断循环(当然这都是异步操作)
// 直到写入返回 0 或者检测到 '@' 开头
return
uring_exec::async_read(scheduler, client_fd, buf.data(), buf.size())
| stdexec::then([=, &buf](int read_bytes) {
auto copy = std::ranges::copy;
auto view = buf | std::views::take(read_bytes);
auto to_console = std::ostream_iterator<char>{std::cout};
copy(view, to_console);
return read_bytes;
})
| stdexec::let_value([=, &buf](int read_bytes) {
return uring_exec::async_write(scheduler, client_fd, buf.data(), read_bytes);
})
| stdexec::let_value([=, &buf](int written_bytes) {
return stdexec::just(written_bytes == 0 || buf[0] == '@');
})
| exec::repeat_effect_until();
})
// 可以写一个析构时执行异步关闭的 sender
// 只是我不打算支持 RAII 风格的文件描述符,让接口尽可能贴近 liburing
// 如有需要可以自己做组合扩展
| stdexec::let_value([=] {
std::cout << "Closing client..." << std::endl;
return uring_exec::async_close(scheduler, client_fd) | stdexec::then([](...){});
});
}
// ACCEPT -> ACCEPT
// -> ECHO
stdexec::sender
auto server(io_uring_exec::scheduler scheduler, int server_fd, exec::async_scope &scope) {
return
uring_exec::async_accept(scheduler, server_fd, nullptr, nullptr, 0)
| stdexec::let_value([=, &scope](int client_fd) {
// 相当于 fork,产出新的异步链路 echo
scope.spawn(echo(scheduler, client_fd));
return stdexec::just(false);
})
| exec::repeat_effect_until();
}
int main() {
// 一些辅助函数,和 sender/receiver 没关系
auto server_fd = uring_exec::utils::make_server({.port=8848});
auto server_fd_cleanup = uring_exec::utils::defer([=] { close(server_fd); });
// 这是 uring_exec 的执行上下文
io_uring_exec uring({.uring_entries=512});
exec::async_scope scope;
// 从中获取调度器描述符
// 这里让 stdexec 感知到 io_uring_exec::scheduler 类型是一个调度器
// 因为它符合 stdexec::scheduler concept
stdexec::scheduler auto scheduler = uring.get_scheduler();
// 简单的 fire and forget
scope.spawn(stdexec::starts_on(scheduler,
server(scheduler, server_fd, scope)));
// 这个简单实例会一直执行 run,后续会说怎么提供退出操作
uring.run();
}
这里每一个 uring_exec::async_* 异步函数都对应于 io_uring_prep_*,并且具有近乎相同的函数签名(参数和返回值)。需要注意的是,这些 sender 属于 sender factory。在 std::execution 中,sender 的组合方式是 consumer(factory | adaptor | adaptor ...),这意味着你不能在管道中间写 uring_exec::async_*,因此 stdexec::let_value 基本上是必需品了,它让你能在组合过程中使用任意 factory。
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_sender.h#L76
// A [sender factory] factory for `io_uring_prep_*` asynchronous functions.
//
// These asynchronous senders have similar interfaces to `io_uring_prep_*` functions.
// That is, io_uring_prep_*(sqe, ...) -> async_*(scheduler, ...)
//
// Usage example:
// auto async_close = make_uring_sender_v<io_uring_prep_close>;
// stdexec::sender auto s = async_close(scheduler, fd);
template <auto io_uring_prep_invocable>
inline constexpr auto make_uring_sender_v = make_uring_sender_t<io_uring_prep_invocable>{};
////////////////////////////////////////////////////////////////////// Asynchronous senders
inline constexpr auto async_oepnat = make_uring_sender_v<io_uring_prep_openat>;
inline constexpr auto async_readv = make_uring_sender_v<io_uring_prep_readv>;
inline constexpr auto async_readv2 = make_uring_sender_v<io_uring_prep_readv2>;
inline constexpr auto async_writev = make_uring_sender_v<io_uring_prep_writev>;
inline constexpr auto async_writev2 = make_uring_sender_v<io_uring_prep_writev2>;
inline constexpr auto async_close = make_uring_sender_v<io_uring_prep_close>;
inline constexpr auto async_socket = make_uring_sender_v<io_uring_prep_socket>;
inline constexpr auto async_bind = make_uring_sender_v<io_uring_prep_bind>;
inline constexpr auto async_accept = make_uring_sender_v<io_uring_prep_accept>;
inline constexpr auto async_connect = make_uring_sender_v<io_uring_prep_connect>;
inline constexpr auto async_send = make_uring_sender_v<io_uring_prep_send>;
inline constexpr auto async_recv = make_uring_sender_v<io_uring_prep_recv>;
inline constexpr auto async_sendmsg = make_uring_sender_v<io_uring_prep_sendmsg>;
inline constexpr auto async_recvmsg = make_uring_sender_v<io_uring_prep_recvmsg>;
inline constexpr auto async_shutdown = make_uring_sender_v<io_uring_prep_shutdown>;
inline constexpr auto async_poll_add = make_uring_sender_v<io_uring_prep_poll_add>;
inline constexpr auto async_poll_update = make_uring_sender_v<io_uring_prep_poll_update>;
inline constexpr auto async_poll_remove = make_uring_sender_v<io_uring_prep_poll_remove>;
inline constexpr auto async_timeout = make_uring_sender_v<io_uring_prep_timeout>;
inline constexpr auto async_futex_wait = make_uring_sender_v<io_uring_prep_futex_wait>;
inline constexpr auto async_futex_wake = make_uring_sender_v<io_uring_prep_futex_wake>;
总之,如果没有特殊情况,具体的 sender API 就是直接映射到对应的 io_uring_prep_*。你可以理解为这是 std::execution 搭配 io_uring 作为异步网络库/文件库的主要接口。
NOTES:
- 我觉得简单的场景还是能减少
let_value的使用频率,可以后期尝试一下uring_exec::async_作为 adaptor 的可能性。 - 一点命名空间的说明:
uring_exec是这个适配库的实现,stdexec是后续将合并到 C++26 std::execution 的标准库参考实现,exec是 stdexec 的非标准扩展实现。
coroutine
// https://github.com/Caturra000/uring_exec/blob/for-blog/examples/hello_coro.cpp
using uring_exec::io_uring_exec;
int main() {
io_uring_exec uring(512);
stdexec::scheduler auto scheduler = uring.get_scheduler();
// 利用 jthread 提供的 stop token 机制
std::jthread j {[&](std::stop_token stop_token) {
// 跟前面的 echo 不同,它接受 stop_token,能感知到停止请求
// 另外,我这里提供的 io_uring_exec 对于任意线程的任务投递都是线程安全的(yes, lockfree)
uring.run(stop_token);
}};
// 同步等待
auto [n] = stdexec::sync_wait(std::invoke(
[=](auto scheduler) -> exec::task<int> {
// co_await 前,执行上下文为 main thread
co_await exec::reschedule_coroutine_on(scheduler);
// co_await 后,执行上下文为 jthread
// 异步地等待 2 秒
println("hello stdexec! and ...");
co_await uring_exec::async_wait(scheduler, 2s);
// 异步地写入到标准输出
std::string_view hi = "hello coroutine!\n";
stdexec::sender auto s =
uring_exec::async_write(scheduler, STDOUT_FILENO, hi.data(), hi.size());
// 返回 async_write 得到的值
co_return co_await std::move(s);
}, scheduler)
).value();
// 执行完成后,切换回 main thread
println("written bytes: ", n);
}
sender 可以作为是 C++20 coroutine 当中的 awaiter,因此利用 exec::task 可以直接当作协程去使用。虽说 std::execution 提案作者的观点是 sender/receiver 在结构化并发的支持上优于 C++20 coroutine(内存管理方面),不过这两个能结合起来让我也感到有点意外。
NOTES:
- 只要正确实现 execution 要求,你就能利用这个特性,
exec::task能帮你做 await trasform。 - 另外我认为 IO 还是避不开 spawn 产生的内存管理开销,这点应该和 stdexec 计算用途不一样。
- C++(可能的)标准网络库参考实现 sender-based net29 的示例大量使用了 coroutine,可能是作者之前给的早期 sender 示例过于
结构化了。
线程池
// https://github.com/Caturra000/uring_exec/blob/for-blog/examples/thread_pool.cpp
using uring_exec::io_uring_exec;
int main() {
io_uring_exec uring({.uring_entries=512});
stdexec::scheduler auto scheduler = uring.get_scheduler();
exec::async_scope scope;
constexpr size_t pool_size = 4;
constexpr size_t user_number = 4;
constexpr size_t some = 10000;
std::atomic<size_t> refcnt {};
auto thread_pool = std::array<std::jthread, pool_size>{};
for(auto &&j : thread_pool) {
j = std::jthread([&](auto token) { uring.run(token); });
}
auto users = std::array<std::jthread, user_number>{};
auto user_request = [&refcnt](int i) {
refcnt.fetch_add(i, std::memory_order::relaxed);
};
auto user_frequency = std::views::iota(1) | std::views::take(some);
auto user_post_requests = [&] {
for(auto i : user_frequency) {
stdexec::sender auto s =
stdexec::schedule(scheduler)
| stdexec::then([&, i] { user_request(i); })
// 这里是调试用途,丢给 TSAN 检测并发问题
| stdexec::let_value([scheduler] {
return
uring_exec::async_nop(scheduler)
| stdexec::then([](...){});
});
scope.spawn(std::move(s));
}
};
for(auto &&j : users) j = std::jthread(user_post_requests);
for(auto &&j : users) j.join();
// Fire but don't forget.
stdexec::sync_wait(scope.on_empty());
assert(refcnt == [&](...) {
size_t sum = 0;
for(auto i : user_frequency) sum += i;
return sum * user_number;
} ("Check refcnt value."));
std::cout << "done: " << refcnt << std::endl;
}
其实前面的示例也可以看出,它的上下文就是 Asio 的模样,不过接口只有一个 run(),只是定制点非常多(后面再说)。我个人觉得 asio::io_context 就是最理想的执行上下文。当你不需要额外线程时,仅需本地的 run() 调用;当你需要后台任务时,可以任意搭配 std::thread 或者 pthread 等。比如这里,你需要一个固定的线程池,无非就是四行代码;而如果需要动态扩容(或者缩容)的线程池,你随时可以添加 run() 也可以随时退出,这是线程安全的。我也在定制点那里提供了简单的任务进展统计作为一个启发式判断的标准。
另外我觉得它可以进一步做亲和性之类的优化,比如 auto local_scheduler = bind(scheduler, jthread) 返回一个附着到某个线程的调度器,从而进一步在所有的异步函数(sender)中使用类似 async_read(any_scheduler, ...) 的操作。不过我目前虽然实现好了 local_scheduler,该怎么和 jthread 搭配实现还没想好,算是常规画饼了。(考虑 stdexec::read_env() 可能有用,待查资料。)
停止令牌
// https://github.com/Caturra000/uring_exec/blob/for-blog/examples/stop_token.cpp
using uring_exec::io_uring_exec;
int main() {
// Default behavior: Infinite run().
// {
// io_uring_exec uring({.uring_entries=8});
// std::jthread j([&] { uring.run(); });
// }
// Per-run() user-defined stop source (external stop token).
auto user_defined = [](auto stop_source) {
io_uring_exec uring({.uring_entries=8});
auto stoppable_run = [&](auto stop_token) { uring.run(stop_token); };
std::jthread j(stoppable_run, stop_source.get_token());
stop_source.request_stop();
};
user_defined(std::stop_source {});
user_defined(stdexec::inplace_stop_source {});
std::cout << "case 1: stopped." << std::endl;
// Per-io_uring_exec stop source.
{
using uring_stop_source_type = io_uring_exec::underlying_stop_source_type;
static_assert(
std::is_same_v<uring_stop_source_type, std::stop_source> ||
std::is_same_v<uring_stop_source_type, stdexec::inplace_stop_source>
);
io_uring_exec uring({.uring_entries=8});
std::jthread j([&] { uring.run(); });
uring.request_stop();
}
std::cout << "case 2: stopped." << std::endl;
// Per-std::jthread stop source.
{
io_uring_exec uring({.uring_entries=8});
std::jthread j([&](std::stop_token token) { uring.run(token); });
}
std::cout << "case 3: stopped." << std::endl;
// Heuristic algorithm (autoquit).
{
io_uring_exec uring({.uring_entries=8});
constexpr auto autoquit_policy = io_uring_exec::run_policy {.autoquit=true};
std::jthread j([&] { uring.run<autoquit_policy>(); });
}
std::cout << "case 4: stopped." << std::endl;
}
P2300 有相当的篇幅是关于 stop_token 的改动。uring_exec 对于停止令牌的支持,目前可以定制这四种行为风格:内置或者外置上下文的停止源(stop source),关联 jthread 的停止令牌或者根本不使用令牌直接靠算法猜均可。(为什么说是猜?因为 io_uring 的特性让你不可能精确得知已提交未完成的 IO 操作数,我之前写的文章当中有提到)
另外也说明一下,未来跟着 std::exection 进标准的还有 std(exec)::inplace_stop_token、std(exec)::never_stop_token,主要是解决 std::stop_token 没有完善利用结构化并发(避免生命周期管理的额外开销)和类型系统(constexpr unstoppable)的问题,我这里都支持了。
运行循环
struct run_policy {
// Informal forward progress guarantees.
// NOTES:
// * These are exclusive flags, but using bool (not enum) for simplification.
// * `weakly_concurrent` is not a C++ standard part, which can make progress eventually
// with lower overhead compared to `concurrent`, provided it is used properly.
// * `parallel` (which makes progress per `step`) is NOT supported for IO operations.
bool concurrent {true}; // which requires that a thread makes progress eventually.
bool weakly_parallel {false}; // which does not require that the thread makes progress.
bool weakly_concurrent {false}; // which requires that a thread may make progress eventually.
// Event handling.
// Any combination is welcome.
bool launch {true};
bool submit {true};
bool iodone {true};
// Behavior details.
bool busyloop {false}; // No yield.
bool autoquit {false}; // `concurrent` runs infinitely by default.
bool realtime {false}; // (DEPRECATED) No deferred processing.
bool waitable {false}; // Submit and wait.
bool hookable {true}; // Always true beacause of per-object vtable.
bool detached {false}; // Ignore stop requests from `io_uring_exec`.
bool progress {false}; // run() returns run_progress_info.
bool no_delay {false}; // Complete I/O as fast as possible.
bool blocking {false}; // in-flight operations cannot be interrupted by a stop request.
bool transfer {false}; // For stopeed local context. Just a tricky restart.
bool terminal {false}; // For stopped remote context. Cancel All.
size_t iodone_batch {64}; // (Roughly estimated value) for `io_uring_peek_batch_cqe`.
size_t iodone_maxnr {512}; // Maximum number of `cqe`s that can be taken in one step.
};
其它的执行上下文的定制点,就全部写在 run_policy 里面(不难看出我有长度强迫症),它是可以 constexpr 构造的,因此把它插入到 uring.run<policy>([any-stop-token])即可。
NOTE: 进展保证(forward progress guarantees)本来就是 C++ 标准借用其它领域的概念,这里除去标准部分多加了一个 weakly_concurrent 定义,表示有任意进展就立刻退出。因为个人认为一次运行循环代表着一次批处理,这样你可以在循环的批处理中暂时退出以记录日志或者做负载调整等操作。
// run_policy: See the comments above.
// any_stop_token_t: Compatible with `std::jthread` and `std::stop_token` for a unified interface.
// Return type: Either `run_progress_info` or `void`, depending on `run_policy.progress`.
template <run_policy policy = {},
typename any_stop_token_t = stdexec::never_stop_token>
auto run(any_stop_token_t external_stop_token = {});
不过目前这里不好写 stop_token 的 concept,主要是 stdexec 不考虑 C++20/23 的兼容性(提案里的描述都有矛盾的地方),可能需要迭代几个版本号才会修复,总之先写一个 typename 意思一下。
取消点
// https://github.com/Caturra000/uring_exec/blob/for-blog/examples/per_operation_cancellation.cpp
auto make_sender(io_uring_exec::scheduler scheduler,
std::chrono::steady_clock::duration duration)
{
return
stdexec::schedule(scheduler)
| stdexec::let_value([=] {
auto sout = std::osyncstream{std::cout};
sout << duration.count() << " is on thread:"
<< std::this_thread::get_id() << std::endl;
return uring_exec::async_wait(scheduler, duration);
});
}
int main() {
io_uring_exec uring({.uring_entries = 8});
std::array<std::jthread, 5> threads;
for(auto &&j : threads) {
j = std::jthread([&](auto token) { uring.run(token); });
}
using namespace std::chrono_literals;
stdexec::scheduler auto s = uring.get_scheduler();
stdexec::sender auto _3s = make_sender(s, 3s);
stdexec::sender auto _9s = make_sender(s, 9s);
// Waiting for 3 seconds, not 9 seconds.
// 有一个 IO 操作先完成了,直接打断其它 IO 操作
stdexec::sender auto any = exec::when_any(std::move(_3s), std::move(_9s));
stdexec::sync_wait(std::move(any));
}
这个算是最有意思的点。正常的 IO 操作不是成功就是错误,很难有完善支持取消的特性(声明:不是整个 IO object 给干掉就叫取消)。sender/receiver 在设计时就已经考虑好了 receiver 有三条管道:value、error 和 stopped。取消点是内建且隐式的,不需要用户主动轮询停止令牌,而且可以在子图当中传播。
取消点在复杂的组合操作中相当好用:
- 比如任意 IO 操作的超时管理,使得 API/sender 不需要显式地支持超时参数。见另一个示例:ping_when_any,该示例由 scope 产出的异步 IO 操作不含任何超时参数。
- 或者并发 IO 操作的竞争优化,提高响应性能。具体例子见 IETF 快乐眼球算法说明。
NOTE: 虽然标准库在标准上提供了「内建」支持,但是具体要怎么「隐式」支持还是要自己想办法。
实现要点
其实我不太想写这一块,一方面是 uring_exec 的代码不多,直接看就行;另一方面是 stdexec 的文档只能用悲剧来形容(≈ 没有),我不能保证当前实现是最佳实践。但是现在有适配 std::execution 的参考实现实在是太少了,我希望在这里提供一个适配思路。
确定方向
首先需要明确的是,这个项目所需要适配的是面向 io_uring 异步函数的 sender factory,实际上不需要考虑 sender adaptor 和 sender consumer。理论上 factory 要比 adaptor 简单得多,后者需要你写 stdexec::set_value 定制,前者不需要注。除此以外,我们需要一个基本的 scheduler,而 scheduler 也需要 sender (factory) 去支持。
NOTE: 虽然说是不需要写,但是写了就可以做到更好!比如前面说了没计划安排一个 RAII fd 类型,假设你实现了一个 to_raii 的 sender adaptor,可以做到 async_accept(...) | to_raii 直接无痛生成一个产出 RAII fd 的 sender,并且通过组合保留了原有的接口。这就是 composable sender 的威力。(说得很好,但是我依然没计划安排)
scheduler
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal.h#L133
// For `stdexec::scheduler` concept.
// We might have several scheduler implementations, so make a simple template for them.
template <typename Context>
struct trivial_scheduler {
template <stdexec::receiver Receiver>
struct operation: io_uring_exec_task {
// 让 stdexec 知道你是谁
using operation_state_concept = stdexec::operation_state_t;
// operation state 的核心接口(kick off!)
// 因为整个 sender 描述的任务图是懒惰计算的,它需要一个明确开始执行的调用点
void start() noexcept {
// Private customization point.
// 私有实现,这里不好做 CRTP(嵌在子类里面了),所以额外做一个私有定制点
start_operation(context, this);
}
// 这个 vtable 是我的内部实现,你可以用 virtual 接口代替
// 该怎么写看具体需求,我是为了实现每个对象都有不同的虚表,并且能做到运行时切换
inline constexpr static vtable this_vtable {
{.complete = [](io_uring_exec_task *_self) noexcept {
auto &receiver = static_cast<operation*>(_self)->receiver;
using env_type = stdexec::env_of_t<Receiver>;
using stop_token_type = stdexec::stop_token_of_t<env_type>;
if constexpr (stdexec::unstoppable_token<stop_token_type>) {
// 它是(被执行上下文的运行循环 runloop 捞到后)立刻完成
stdexec::set_value(std::move(receiver));
return;
}
// 如果上游(receiver)的任务取消,它会传播 stop token 让你知道
// 那就不必调度并开始子任务了
auto stop_token = stdexec::get_stop_token(stdexec::get_env(receiver));
stop_token.stop_requested() ?
stdexec::set_stopped(std::move(receiver))
: stdexec::set_value(std::move(receiver));
}},
{.cancel = [](io_uring_exec_task *_self) noexcept {
auto self = static_cast<operation*>(_self);
stdexec::set_stopped(std::move(self->receiver));
}}
};
// 我们之所以需要 vtable,是因为需要擦除 Receiver 类型信息
// 以防你没留意,这个 operation 是模板的模板,继承于 io_uring_exec_task 就是为了抹掉类型
Receiver receiver;
// 比方说,前面的 io_uring_exec 就是一个适合作为 Context 的类型
Context *context;
};
struct sender {
using sender_concept = stdexec::sender_t;
using completion_signatures = stdexec::completion_signatures<
// 后续任务没有返回结果
stdexec::set_value_t(),
// 这个 sender 支持取消调度操作
stdexec::set_stopped_t()>;
// env 没怎么看提案了解,总之它可以让一些 sender/receiver 的性质被 stdexec 感知
// 一般通过 query 交互,或者通过 read_env 产生(异步 query 的)sender
struct env {
// 通常是提供 query() 接口,
// 而这里 get_completion_scheduler_t 是 stdexec::scheduler concept 必须提供的
// 简单来说是对应于执行 completion operation 时的调度器
// 这里面涉及到 domain 定制点等问题,而我们总是使用相同的调度器
// https://wg21.link/P2300#design-propagation
// <CPO> 指的是 completion tag 这个概念,有兴趣就自行看提案
template <typename CPO>
auto query(stdexec::get_completion_scheduler_t<CPO>) const noexcept {
return trivial_scheduler{context};
}
Context *context;
};
// 让 stdexec 感知到你的 env
env get_env() const noexcept { return {context}; }
// 拼接任务图,知道续体(receiver)是谁,这样你才能在完成/取消这些操作传递下去
// 在这里 sender 通过 connect 生成了 operation state
// 至于在哪里 connect 那是 sender adaptor 的事情
// 更多说明见我那篇翻译,或者别的资料
template <stdexec::receiver Receiver>
operation<Receiver> connect(Receiver receiver) noexcept {
return { {operation<Receiver>::this_vtable}, std::move(receiver), context};
}
Context *context;
};
bool operator<=>(const trivial_scheduler &) const=default;
// 让 stdexec::schedule 感知,
// 内部会帮你调用 `trivial_scheduler::sender::schedule()` 产生一个懒惰的 sender
// 然后在 consumer 面前它会帮你执行(factory 的) start()
sender schedule() const noexcept { return {context}; }
Context *context;
};
不考虑 __t/__id 编译效率优化的话,一个简单的调度器可以是这样。基本上我没说私有的就意味着它是作为 std::execution 接口去使用的,不是随便定的函数名字。
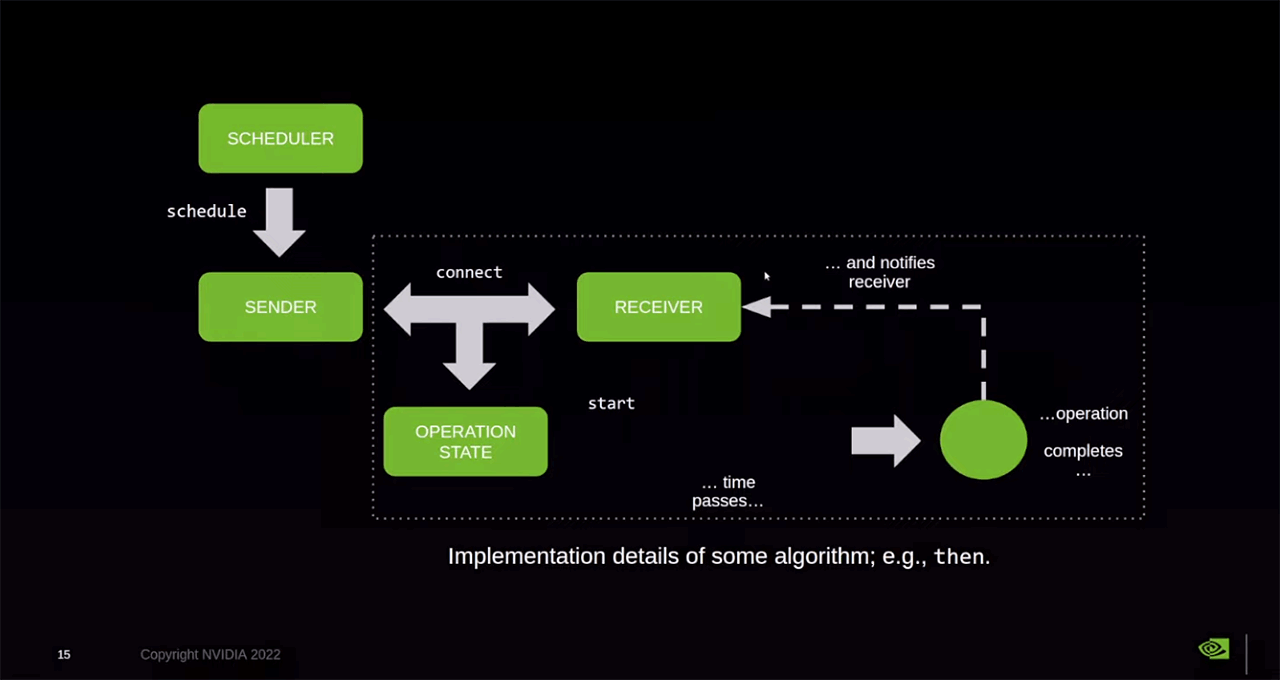 给个图对照一下,图源
给个图对照一下,图源
另外需要提示的是,有部分接口是明确要求 noexcept,没有仔细查过具体哪些接口,总之尽可能让你的库整体为 noexcept 即可。比如 start() 可能是有要求的,一些复杂操作需要 try-catch 并且使用 set_error() 传播下去。当然不知道哪里应该 noexcept,随便写也没关系,编译器到时候会拒绝你。
NOTES:
- 这里是一个很简单的调度器,从启动到完成都能保证不会有任何错误产生(后面可以看出
start_operation()的做法),所以completion_signatures并不包含set_error()。 - 这里的
this_vtable.cancel()不算打断,只是一个很常规的停止点,没有需求也可以不写。
task
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal.h#L21
// Avoid requiring a default constructor in derived classes.
struct intrusive_node {
intrusive_node *_i_next {nullptr};
};
// All the tasks are asynchronous.
// The `io_uring_exec_task` struct is queued by a user-space intrusive queue.
// NOTE: The io_uring-specified task is queued by an interal ring of io_uring.
struct io_uring_exec_task: detail::immovable, intrusive_node {
using vtable = detail::make_vtable<
detail::add_complete_to_vtable<void(io_uring_exec_task*)>,
detail::add_cancel_to_vtable <void(io_uring_exec_task*)>>;
io_uring_exec_task(vtable vtab) noexcept: vtab(vtab) {}
// Receiver types erased.
vtable vtab;
};
// Atomic version.
using intrusive_task_queue = detail::intrusive_queue<io_uring_exec_task, &io_uring_exec_task::_i_next>;
// `internal::start_operation` is a customization point for `trivial_scheduler` template.
inline void start_operation(intrusive_task_queue *self, auto *operation) noexcept {
self->push(operation);
}
前面调度器关联的 operation 是一个模板,实际上是继承于一个 task,主要是做两件事:
- 提供虚表。
- 提供链表。这个链表是侵入式的,不需要额外的动态内存分配,也不可能分配时抛出异常。
detail:: 里面的就不展示了,比较占版面。
NOTES:
- 这里
intrusive_task_queue可以是一个最为直接的执行上下文,理论上使用using ... = trivial_scheduler<intrusive_task_queue>就能得到一个完整的调度器,但是这只是作为一个参考示例,实用的设计需要做一个完善的执行上下文(execution context),让调度器能把任务放置于运行循环(runloop)中。 - 非常重要的一点:operation state 必须是不可移动的类型。它有点像 Asio 当中的稳定内存资源(POSM)的意思。这是你可以肆无忌惮地使用侵入式链表等免除智能指针设计的根本原因。
execution context
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal.h#L250
////////////////////////////////////////////////////////////////////// control block
class io_uring_exec: public underlying_io_uring, // For IORING_SETUP_ATTACH_WQ.
public io_uring_exec_run<io_uring_exec, io_uring_exec_operation_base>,
private detail::unified_stop_source<stdexec::inplace_stop_source>
{
using io_uring_exec_run::run_policy;
using io_uring_exec_run::run;
// Required by stdexec.
// Most of its functions are invoked by stdexec.
using scheduler = trivial_scheduler<io_uring_exec>;
auto get_scheduler() noexcept { return scheduler{this}; }
// ...
private:
friend void start_operation(io_uring_exec *self, auto *operation) noexcept {
self->_immediate_queue.push(operation);
}
intrusive_task_queue _immediate_queue;
}
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal_run.h
// template <...>
struct io_uring_exec_run {
template <run_policy policy = {},
typename any_stop_token_t = stdexec::never_stop_token>
auto run(any_stop_token_t external_stop_token = {}) {
// ...
for(auto step : std::views::iota(1 /* 0 means no-op. */)) {
if constexpr (policy.launch) {
auto launch = [&launched](auto &intrusive_queue) {
auto &q = intrusive_queue;
// 这里是被类型擦除后的 io_uring_exec_task* 类型
auto op = q.move_all();
// NOTE:
// We need to get the `next(op)` first.
// Because `op` will be destroyed after complete/cancel().
auto safe_for_each = [&q, op](auto &&f) mutable {
// It won't modify the outer `op`.
// If we need any later operation on it.
for(; op; f(std::exchange(op, q.next(op))));
};
safe_for_each([&launched](auto op) {
if constexpr (policy.terminal) {
op->vtab.cancel(op);
// Make Clang happy.
(void)launched;
} else {
op->vtab.complete(op);
launched++;
}
});
};
// ...
launch(remote._immediate_queue);
}
}
// ...
}
};
我这里省略了很多,一个直接的思路是调度任务就是把任务(io_uring_exec_task)放置于无锁队列中,然后在运行循环中捞起来,执行虚表完成即可。
注意执行前务必先获取 next 结点。具体看上面的注释或者 C++ 标准,这是我用调试器瞪了好几遍才意识到的事情。
从现在开始,这里已经适配好了一个空的 stdexec 应用库。你可以在这个简单的库上做线程安全的 stdexec::schedule() | stdexec::then() 等计算操作。
operation
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal.h#L108
// External structured callbacks support.
// See io_uring_exec_operation.h and io_uring_exec_sender.h for more details.
struct io_uring_exec_operation_base: detail::immovable, intrusive_node_with_meta {
using result_t = decltype(std::declval<io_uring_cqe>().res);
using _self_t = io_uring_exec_operation_base;
using vtable = detail::make_vtable<
detail::add_complete_to_vtable<void(_self_t*, result_t)>,
detail::add_cancel_to_vtable <void(_self_t*)>,
detail::add_restart_to_vtable <void(_self_t*)>>;
constexpr io_uring_exec_operation_base(vtable vtab) noexcept: vtab(vtab) {}
vtable vtab;
// We might need a bidirectional intrusive node for early stopping support.
// However, this feature is rarely used in practice.
// We can use hashmap instead to avoid wasting footprint for every object's memory layout.
};
接下来就是 IO 操作的适配。同样是在队列上操作,所以我们需要 vtable 擦除类型。
NOTE: 不考虑取消点设计的话,我们不需要使用侵入式结点,因为 io_uring 具有 SQ 环,利用 user_data 就可以间接实现 IO 操作之间的链表。
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_operation.h#L28
// F 是一个 io_uring_prep_* 函数
template <auto F, stdexec::receiver Receiver, typename ...Args>
struct io_uring_exec_operation: io_uring_exec::operation_base {
using operation_state_concept = stdexec::operation_state_t;
void start() noexcept {
// 入队前(尚未提交)检查上游是否已停止
// 如果是就可以提前结束
if(stop_requested()) [[unlikely]] {
stdexec::set_stopped(std::move(receiver));
return;
}
if(auto sqe = io_uring_get_sqe(&local)) [[likely]] {
using op_base = io_uring_exec::operation_base;
// IO 操作结点挂入到 user_data
io_uring_sqe_set_data(sqe, static_cast<op_base*>(this));
// 可以理解为 io_uring_prep_*(sqe, args...)
std::apply(F, std::tuple_cat(std::tuple(sqe), std::move(args)));
// ...
// 省略一些取消点打断支持
// ...
// 后续在运行循环的 run() 里面会被提交到 io_uring 当中
} else {
// The SQ ring is currently full.
// ...
// 这块看你取舍,你可以直接 set_error 结束流程
// 也可以先提交再尝试获取 sqe
// 我这里选择的是重新调度,需要一点小技巧
async_restart();
}
}
// 由运行循环调用的函数集合
inline constexpr static vtable this_vtable { /* ... */ };
};
在具体的 IO 操作类型上,start() 自然是等价于入队操作,将 operation state 挂入到 sqe.user_data,后续可以 peek cqe 过程中重新映射回 operation state 基类,那么可以根据 vtable 来做 set_value 或者 set_error。
NOTES:
- 这里在
operation_state.start()前已经被调度到某个上下文中。 - 直接传播错误感觉不是一个好思路,因为 uring entries 本身的数目是比较有限的,你的 IO 操作会在高峰期快速失败,也没法提供高优先级绝不失败的语义。具体见 thread_pool.cpp 示例。
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal_run.h
// template <...>
struct io_uring_exec_run {
template <run_policy policy = {},
typename any_stop_token_t = stdexec::never_stop_token>
auto run(any_stop_token_t external_stop_token = {}) {
// ...
for(auto step : std::views::iota(1 /* 0 means no-op. */)) {
// ...
// 先批处理提交
if constexpr (policy.submit) {
// TODO: wait_{one|some|all}.
if constexpr (policy.waitable) {
submitted = io_uring_submit_and_wait(&local, 1);
} else {
submitted = io_uring_submit(&local);
}
}
// 后批处理收割
if constexpr (policy.iodone) {
std::array<io_uring_cqe*, policy.iodone_batch> cqes;
auto produce_some = [&] {
return io_uring_peek_batch_cqe(
&local, cqes.data(), cqes.size());
};
auto consume_one = [&](io_uring_cqe* cqe) {
auto user_data = io_uring_cqe_get_data(cqe);
using uop = io_uring_exec_operation_base;
// CQE 的私有用户数据映射回 IO 操作的基类
auto uring_op = std::bit_cast<uop*>(user_data);
if constexpr (policy.transfer) {
uring_op->vtab.restart(uring_op);
} else {
// 再通知上游已经完成,
// 根据 cqe->res 确定是 set_value 还是 set_error
uring_op->vtab.complete(uring_op, cqe->res);
}
};
auto consume_some = [&](std::ranges::view auto some_view) {
for(auto one : some_view) consume_one(one);
};
auto greedy = [&](auto some) { /* ... */ };
for(unsigned some; (some = produce_some()) > 0;) {
consume_some(cqes | std::views::take(some));
io_uring_cq_advance(&local, some);
// ...
if(greedy(some)) break;
}
}
}
}
};
其实也应该能猜到大概要怎么做,io_uring 本身是鼓励使用批处理且有完善接口的,因此一个运行循环的原型很容易实现。
当然这是不考虑 run() 线程安全的前提下。虽然前面 launch 阶段可以做到多线程的计算,这是因为无锁队列的 move_all() 以单次原子操作把 task 批量拉到线程本地去处理。但是我们的 IO 操作是会 SQE 分配、IO 提交和 CQE 完成相互竞争,这并非线程安全。一个最直接的免互斥做法是使用线程本地的 uring 设计(ring per thread),也就是说不同线程的运行循环所对应的 io_uring 不是共享实例。
到这里基本就是一个能动的能处理 IO 的 stdexec 应用库,不考虑细节其实不难。
NOTES:
- 至于提交后立刻收割是否合理取决于用户。我的意思是提交本批操作后处理上一批已完成操作的同时由内核并行收集本批未完成操作,而且 run_policy 可以让任意阶段以任意顺序组合。
- 不要想着见缝插针地使用 ring per thread 以外的无锁设计来支持多线程提交/完成,io_uring 作者对此是明确的不鼓励且不支持。并且从基准测试也可看出,单核心的 io_uring 其实相当能打。
- ring per thread 也有小问题,就是每个 ring 后端都有内核线程池去支撑,而多线程池的极端情况会有性能倒退的可能性(目前的负载还没到线程瓶颈,暂时测不出数据),有需求请自行查阅 man 文档找到合适的 flag 去解决问题。
- 最后,ring per thread 的设计有一个麻烦事情,就是 C++ 其实并不支持 per-object thread_local,不同的 context/runloop 对象甚至能通过 thread_local 在同一线程内拿到相同的 io_uring 线程本地实例。能不能有单例以外的设计去处理这个问题?当然有,RTFSC。
cancellation
前面可以看出,start() 阶段检测上游停止显然很好做,但是处于 in-flight 状态的 IO 操作该怎么打断仍然没有解决。
先整理一下我们的取消点需求:
- 一是它必须内建且隐式,这方面的理由和异常一样;
- 二是它要求被动执行且不能使用异常实现,除了语义问题以外,开销极大也是一个问题;
- 三是它必须异步,这个取消点是随时会被触发,也是会在任意线程被触发。
NOTE: 现在完善支持取消点的库似乎比较少,就算强如 async_simple……那是根本不支持啊。
要求挺多,我一开始也没啥思路。虽然我知道有 io_uring_prep_cancel,但是并没有足够好的办法去结合 stdexec,直到翻了一下 exec::io_uring_context 的实现(对,官方是有提供 io_uring 实现,只是不支持任何 IO 操作,非常诡异的存在)。
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_operation.h#L28
template <auto F, stdexec::receiver Receiver, typename ...Args>
struct io_uring_exec_operation: io_uring_exec::operation_base {
using operation_state_concept = stdexec::operation_state_t;
using stop_token_type = stdexec::stop_token_of_t<stdexec::env_of_t<Receiver>>;
// using stop_callback_type = ...; // See below.
void start() noexcept {
if(stop_requested()) [[unlikely]] {
stdexec::set_stopped(std::move(receiver));
return;
}
// NOTE: Don't store the thread_local value to a class member.
// It might be transferred to a different thread.
// See restart()/exec_run::transfer_run() for more details.
auto &local = uring_control->get_local();
if(auto sqe = io_uring_get_sqe(&local)) [[likely]] {
using op_base = io_uring_exec::operation_base;
local.add_inflight();
if(false /* temporarily disabled && have_set_stopped() */) {
// Changed to a static noop.
io_uring_sqe_set_data(sqe, static_cast<op_base*>(&hidden::noop));
io_uring_prep_nop(sqe);
} else {
io_uring_sqe_set_data(sqe, static_cast<op_base*>(this));
std::apply(F, std::tuple_cat(std::tuple(sqe), std::move(args)));
// 初始化 callback,使得上游停止时被动触发 cancellation
// 注意触发回调可以在不同的线程间执行
install_stoppable_callback(local);
}
} else {
// The SQ ring is currently full.
//
// One way to solve this is to make an inline submission here.
// But I don't want to submit operations at separate execution points.
//
// Another solution is to make it never fails by deferred processing.
// TODO: We might need some customization points for minor operations (cancel).
async_restart();
}
}
// 在 operation state 实际启动前安装好被动回调
// 当然,如果已经得知上游不可能发出停止请求,一切都是零开销(卸载同理)
// 这里用 not-un-... 是因为 stdexec 的问题,过一段时间不用这样写了
void install_stoppable_callback(auto &local) noexcept {
if constexpr (not stdexec::unstoppable_token<stop_token_type>) {
local_scheduler = local.get_scheduler();
auto stop_token = stdexec::get_stop_token(stdexec::get_env(receiver));
stop_callback.emplace(std::move(stop_token), cancellation{this});
}
}
// Called by the local thread.
// 通过运行循环的方式使得能在本地线程执行
// 能调用卸载意味着它已经不是 in-flight 的状态
void uninstall_stoppable_callback() noexcept {
if constexpr (not stdexec::unstoppable_token<stop_token_type>) {
// 这里能直接 reset 而不考虑其它因素,是因为 stop_callback 语义上保证了
// 析构与 operator() 同步,也就是说如果其它线程在 reset 前并发调用,那这里的析构必须等待直到回调结束
stop_callback.reset();
auto &q = local_scheduler.context->get_stopping_queue(this);
auto op = q.move_all();
if(!op) return;
// See the comment in `io_uring_exec_operation_base`.
// 这是为了避免每个 operation 都要承担双向结点的内存开销,而采用的时间换空间
// 如果能维护双向结点就能直接拔掉自身了
// 但是这些打断操作就是只有少数存在的
q.push_all(op, [this](auto node) { return node && node != this; });
q.push_all(q.next(this), [](auto node) { return node; });
}
}
struct cancellation {
// May be called by the requesting thread.
// So we need an atomic operation.
void operator()() noexcept {
auto local = _self->local_scheduler.context;
auto &q = local->get_stopping_queue(_self);
// `q` and `self` are stable.
q.push(_self);
}
io_uring_exec_operation *_self;
};
// For stdexec.
using stop_callback_type = typename stop_token_type::template callback_type<cancellation>;
inline constexpr static vtable this_vtable {
{.complete = [](auto *_self, result_t cqe_res) noexcept {
auto self = static_cast<io_uring_exec_operation*>(_self);
self->uninstall_stoppable_callback();
// ...
}},
// ...
};
Receiver receiver;
io_uring_exec *uring_control;
std::tuple<Args...> args;
// 一个附着到指定线程的调度器
io_uring_exec::local_scheduler local_scheduler;
// Maikel 大神指出的最佳实践:
// 停止回调建议放在最后一位,使得 operation 析构时,同步语义使得(其他线程的)回调仍可安全访问上方所有成员
// 我们这里好像用不到这个性质(因为保证在析构前就手动处理好),但是保持习惯
std::optional<stop_callback_type> stop_callback;
};
关键点是 stop_callback。虽然实现不一定是 std::stop_callback,但是你可以从中了解它的语义(见 cppreference),其中析构能提供的同步语义也非常重要。
知道了这个工具的妙处以后,就是安装和卸载停止回调的实现了。这里有一个 stopping queue 用于记录被动原子打断的 IO 操作。如果有 stop_requested(),已安装的 cancellation.operator() 就能调用并记录,否则在完成阶段时会被卸载。在这中间的过程中,IO 操作可能会被动地挂在到 stopping queue 当中。
// https://github.com/Caturra000/uring_exec/blob/for-blog/include/uring_exec/io_uring_exec_internal_run.h
// template <...>
struct io_uring_exec_run {
template <run_policy policy = {},
typename any_stop_token_t = stdexec::never_stop_token>
auto run(any_stop_token_t external_stop_token = {}) {
// ...
for(auto step : std::views::iota(1 /* 0 means no-op. */)) {
// ...
// Not accounted in progress info.
if constexpr (not policy.blocking) {
// No need to traverse the map.
// 你可以理解为有一个 hashmap,每次 step 只会拿取一个桶,最终会全部处理掉
auto &q = local.get_stopping_queue_robin(step);
// No need to use `safe_for_each`.
// 这不是一个真正的完成收割操作,不需要上述的安全操作
for(auto op = q.move_all(); op;) {
auto sqe = io_uring_get_sqe(&local);
// `uring` is currently full. Retry in the next round.
if(!sqe) [[unlikely]] {
q.push_all(op, [](auto node) { return node; });
break;
}
// 这里会有两个 SQE 产生关联:
// * noop 挂载到 cancel SQE 当中,该 SQE 用于打断 op 的 IO 操作
// * 提交 noop 后,op 关联的 SQE 会(立刻)生成 cqe->res = -ECANCELED 的 CQE,
// 在收割时, complete() 过程中会最终定位到 set_stopped()
// * 同时,收割得到的 noop 关联的 CQE 不会有任何操作,它甚至不是一个 operation state
io_uring_sqe_set_data(sqe, &noop);
io_uring_prep_cancel(sqe, op, {});
local.add_inflight();
// 断链操作,因为 transfer 可以把它拉到别的地方(然后另一个 op 也被拉过去,形成了环),
// 还有这里 q.next(op) 当中,q 只是起到类型推导的作用,并没有真的链表
// 这些细节因项目而异,不再讨论了
q.clear(std::exchange(op, q.next(op)));
}
}
}
}
// 它可以用于 cancel SQE 和其他用途
// 至少能免除额外 if-statement 的条件判断
inline constexpr static io_uring_exec_operation_base::vtable noop_vtable {
{.complete = [](auto, auto) noexcept {}},
{.cancel = [](auto) noexcept {}},
{.restart = [](auto) noexcept {}},
};
inline constinit static io_uring_exec_operation_base noop {noop_vtable};
};
剩下的工作就在执行循环,如果 IO 操作存在被动挂入 stopping queue 的可能性,那就会产生对应的 cancel SQE 让他立刻生成 -ECANCELD CQE。并且从上面的卸载函数可知,无论如何 operation_queue 都会回收 stopping queue 当中的结点,并且是在本地线程执行。这里不考虑打一个标记表示没必要检查,是因为打断操作是低频行为,但是你企图提供标记那就是全体 operation 都要徒增内存开销,这里使用 hashmap 配合 round robin 而非双向结点也是同理。
NOTE: 这可能只是一种较为曲折的实现思路,还没想到更简洁的方案。目前我只能说 TSAN 没问题以及测试没问题。至于性能,我不建议高频使用,(据询问大佬后)std::stop_callback 标准库实现是存在额外原子开销和慢路径锁开销的,也就是说只适用于长 IO 的网络场景。
其他细节?
没太记得实现的时候碰到一堆琐碎事情,既然跟适配没啥关系,就随便提一下。
IO 操作的重新调度
当遇到 SQE 分配不足无法完成 start() 时,一个思路是内置 async_scope。因为有结构化并发保证,通过 schedule 和 spawn 并不影响 operation 本身的生命周期,也就是说,你可以异步地反复 start() 直到成功。
别忘了异常处理,spawn 不是免费午餐。
每对象的线程本地存储
你可以在 context 的构造函数中声明一个独特的 NTTP(比如,auto X = [](){}),然后传递到内部的 vtable<X> 模板,该模板由于独特的 NTTP,每次都能为不同的对象实例化不同的 vtable。那问题就好办了,vtable 里面再分配 thread_local 即可。
当然这是仅限 context 的用途,这种做法有限制,但是相比使用一个运行时 hashmap 的 key/value 匹配做法,它的性能更优,很容易被编译器优化掉中间层。
场景调参
尽管我用了一些 flag 去为 io_uring 做场景暗示,但是跑分好像没啥变化,大概可以理解为 io_uring 默认模式已经足够好了。(再次)但是,较新版本内核(6.6+)的网络场景下,io_uring 依然是被 epoll 打个半死。
现有的结论是:epoll 能在低线程数和低连接数时获得惊人的吞吐量(四线程能打对方八线程!),但是并不像 io_uring 随着线程数增加而提供更高的扩展性。这种后端之间的本质差距不是靠 uring_exec/Asio 前端努力优化就能解决的。
异步信号等待
既然已经做了取消点,类似 asio::signal_set 的信号异步等待(以及取消)特性也应该安排一下。做了点简单的调研,Asio 使用的是 self-pipe 的经典做法,主要是为了考虑跨平台的能力。而 uring_exec 使用的是更加平台特定的 signalfd(),配合 io_uring_prep_poll_add(POLLIN) 应该是个绝妙的搭配。不使用异步读操作是因为 signalfd_siginfo 是一个非常巨大的结构体,如果使用异步读操作是必须要提供至少一个结构体大小的缓冲区,所以我这里是只异步等待事件而不获取具体的信号信息。另外两个原因是:一,我可以选择多提供一个功能全面的重载版本;二,uring_exec::async_sigwait() 是可以组合多个的,每一个 sender 传递一个特定信号即可在子图中做出区分。(FIXME: 很可惜,signalfd 并没有 signal 的所有权,还是必须要读操作的)
结合取消点的异步信号等待可以参考该示例。
在写了
前面提到的都是已解决的问题,其实还剩下不少处于新建文件夹的特性支持。
比如,对于零拷贝的支持并不是一个 using make_uring_sender_v<io_uring_prep_send_zc> 就能解决的。尽管我认为 uring_exec 没有必要支持(因为市面上真的使用零拷贝的网络库并不多见),但是简单 profile 发现高频大报文确实有大量时间花在拷贝上。如果考虑支持的话,注意 man 手册 指出:对于 IORING_OP_SEND_ZC,其 CQE 可能携带 IORING_CQE_F_MORE 且必须检查。这意味着它是 multi-shot 的设计,而这刚好是 operation state concept 做不到不好做的事情(你如果想着多次 set_value(),那肯定是错的)。
怎么办?Maikel 大神指出可以设计非标准的 exec::set_next() 以提供「部分完成」的语义。P2300 也提供过另一种更加灵活的思路,就是协程化转换为 range of senders 再去处理。感觉思路都是值得参考的,我有空再写。
不写了
从整体来看,这里 io_uring 的网络场景并非「满血版」。什么叫满血?至少 accept 使用 multi-shot 特性;read 带有 provided buffers;write 正如前面所说,可选 zc 版本(并非必选的原因见我之前摸的 内核态 webserver,你可以使能 zerocopy_flag 跑一遍代码试试),再玩花一点还要利用 direct fd 等等……
当然,要适配这些特性到 sender/receiver 是要花费大量时间的。之前的丐版协程倒是尝试过适配,现在也没精力更新了。所以这部分我也只是口嗨而已 (´_ゝ`)。
总结
总之细节还是看代码吧。