前言
为了提供最佳的用户体验,AOSP 在 user space 上做了非常深入的定制优化,进程管理也不例外。
本文尝试从进程本身及其生命周期角度去描述 AOSP 众多的进程管理机制,包括:进程状态及其容器、oom adjuster、memory factor 和 userspace lowmemorykiller。
文章话题涉及比较宽泛,本人才疏学浅,如有错误还请指正。
进程的启动
先说明一点,Android 本身大量使用 server/client 模型,并通过 socket/binder 等 IPC 机制进行通信。通常来说,用户使用的 application 就是 client,而 OS/framework/library/daemon 侧就是 server。
在 framework 层面上,进程启动的关键函数是 startProcessLocked。
这个函数会在不同组件的处理时机由 server 端拉起进程:
- ActivityManagerService.startProcess() -> startProcessLocked()
- BroadcastQueue.processNextBroadcast() -> ActivityManagerService.startProcessLocked()
- ContentProviderHelper.getContentProviderImpl() -> ActivityManagerService.startProcessLocked()
- ActiveServices.bringUpServiceLocked() -> ActivityManagerService.startProcessLocked()
- TaskFragment.resumeTopActivity() -> ActivityTaskManagerService.startProcessAsync() -> ActivityManagerService.startProcess() (async handler message)
一个典型的(经过大量简化的)调用流程如图:
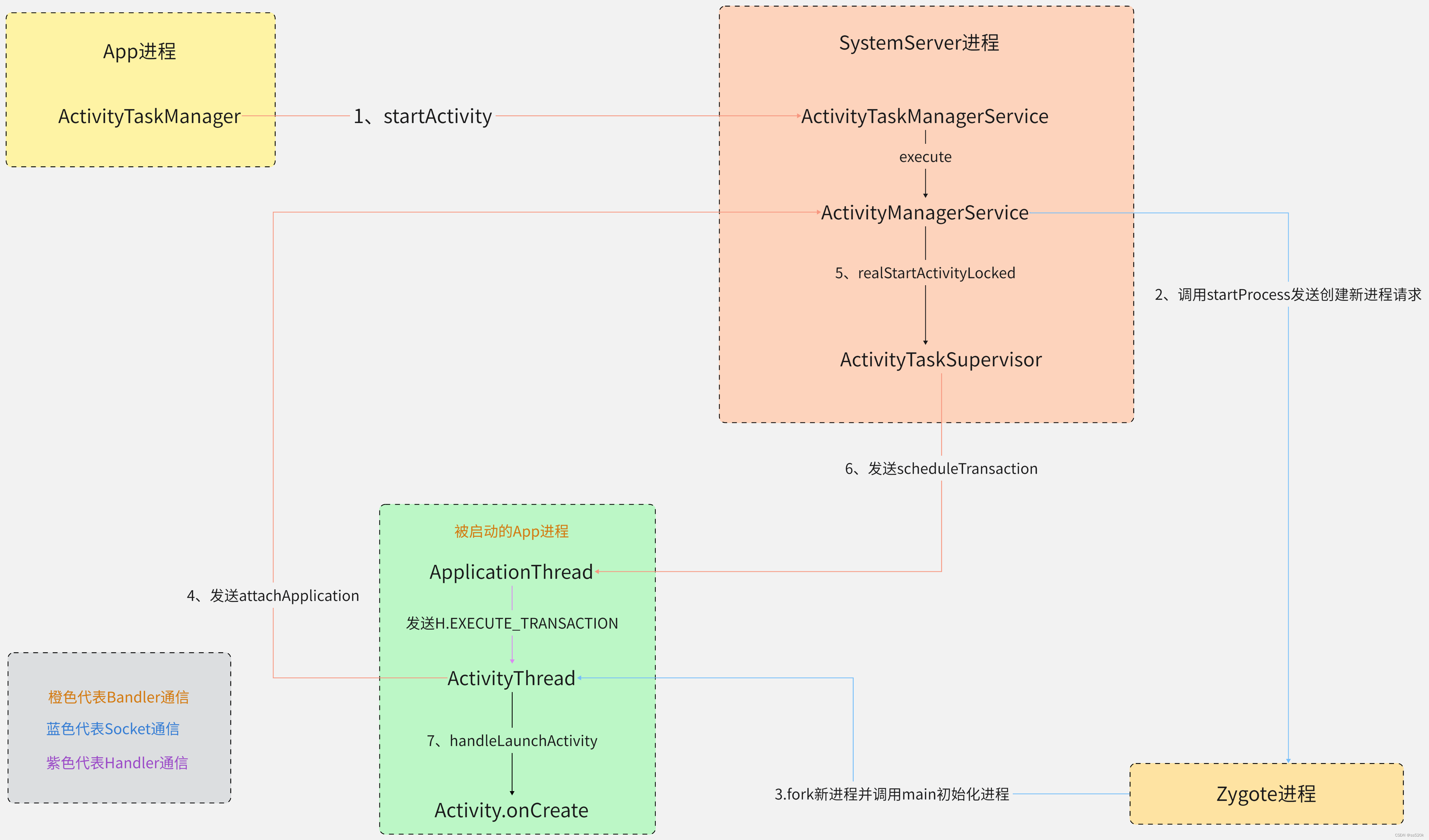
图源:Android13 Activity 启动流程_ss520k 的博客。
当 server 的 startProcess 请求发出,并从 zygote 进程中 fork 出一个新的进程供 app(即 client)使用后,app 层面将最终运行在 ActivityThread::main 上下文中,负责在消息循环中监听 handler 的事件到来。
注 1:比如这里紧接着就来了一个
EXECUTE_TRANSACTION事件。
注 2:
zygote进程可以视为是Android runtime的始祖,由Linux下的init进程派生出来,但是相比init,zygote含有JVM运行时,且有进程池管理,因此由它来负责(高效的)“孵化”其它安卓应用进程(但是不能说是所有安卓下的进程都由它派生出来,比如下面会说到的lmkd仍然是由init来启动,详细点你需要查阅init.rc文件)。
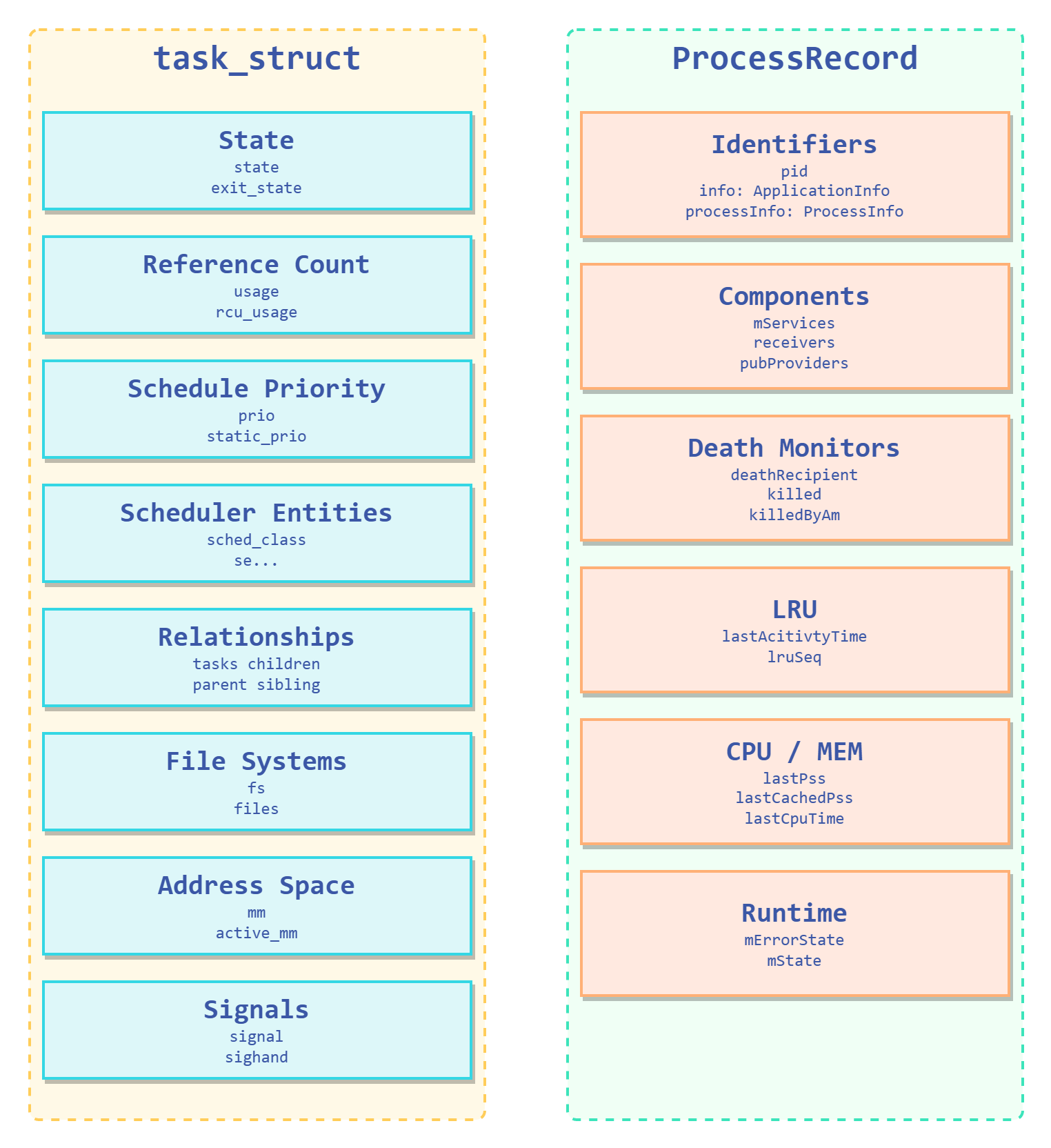
“进程描述符”:ProcessRecord
一个 application 动起来了,那么 server 端需要对它的进程生命周期进行管理。
而之前提到,server 调用的 startProcessLocked 接口进行一个 framework 层面的进程启动过程,将会得到名为 ProcessRecord 的数据结构,由 server 接管:
final ProcessRecord startProcessLocked(String processName,
ApplicationInfo info, boolean knownToBeDead, int intentFlags,
HostingRecord hostingRecord, int zygotePolicyFlags, boolean allowWhileBooting,
boolean isolated) {
return mProcessList.startProcessLocked(processName, info, knownToBeDead, intentFlags,
hostingRecord, zygotePolicyFlags, allowWhileBooting, isolated, 0 /* isolatedUid */,
false /* isSdkSandbox */, 0 /* sdkSandboxClientAppUid */,
null /* sdkSandboxClientAppPackage */,
null /* ABI override */, null /* entryPoint */,
null /* entryPointArgs */, null /* crashHandler */);
}
注:
ProcessList的代码比较长,感兴趣可以看:ProcessList.java - Android Code Search。
类比于 linux kernel 的进程描述符 task_struct,这个 ProcessRecord 数据结构维护的即是进程的运行时信息。下面有简单的图示:
LRU list
在 server 中需要一个容器去维护众多的 ProcessRecord,AOSP 的实现使用的是一个定制的 LRU 列表:
/**
* List of running applications, sorted by recent usage.
* The first entry in the list is the least recently used.
*/
@CompositeRWLock({"mService", "mProcLock"})
private final ArrayList<ProcessRecord> mLruProcesses = new ArrayList<ProcessRecord>();
mLruProcesses 本质是非常简单的一个可变长数组,类似于 std::vector;但是从数据结构层面来看,它其实还被划分为多个 area,如图所示:
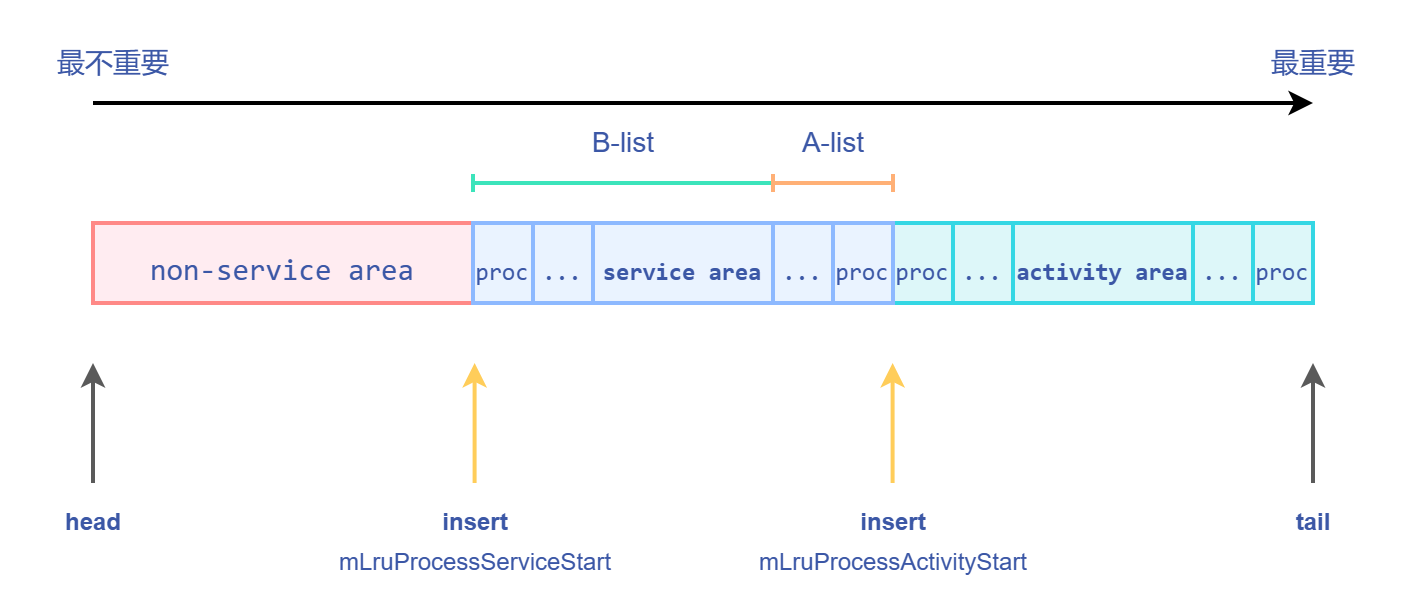
LRU list 会被划分为三个区域:
- activity area
- service area
- non-service area (others)
很好理解,如果一个进程含有 activity 组件,那就会被插入到 activity area;否则再看是否有 service 组件,有的话就插入到 service area,否则只能插入 others。
而插入行为是放到每个 area 的尾部,比如 activity area 的插入就是 \(O(1)\) 时间复杂度的,因为它是插入到 tail,而像 service area 的插入行为则是放入到 mLruProcessActivityStart(同时该变量需要增加 1 个单位),此时是 \(O(n)\) 的时间复杂度(n 指的是进程个数)。
注: LRU 会在以下关键路径进行更新操作(即可选的移除和必选的插入):
- AMS 启动一个进程的时候。
- 绑定/解绑服务。
- start/kill service 的时候。
- remove connection 的时候。
- update processInfo 的时候。
- 处理 broadcast receiver 的时候。
- setSystemProcess 的时候。
- getConnectionProvider 和 addApp 的时候。
- (其它略)
那么问题来了,如此精美的设计到底是为了什么?
自然是为了管理进程——更具体地,是淘汰进程(或者说,为了让其它进程更持久地活着)。
在一个调用非常频繁的操作 updateAndTrimProcessLSP 当中,就有 LRU 的用途,它用于查杀已缓存进程(cached process)以及空进程(empty process,可视为不含组件的已缓存进程),表示不需要过多的缓存进程。这种算法会抑制 LRU 的长度,换个角度来看就是压制可运行进程的个数,让内存保持良好状态且不影响用户体验。
注:cached 允许存在于不同的 area 中。
注:进程的分类非常的多,后面章节有更详细的介绍。
在具体的实现中,查杀规则如下:
- LRU 倒序遍历。
- 维护
numCached和numEmpty计数器,每触发一个对应进程则将对应的计数器加 1。 - 确定 cached 和 empty 最多各保留 16 个进程,如超过则执行步骤 5。
- 如果
numEmpty计数器超过 8 且当前 empty 进程的 activity 活跃时间超过 30min,执行步骤 5。 - 计数器超过 16,则执行
app.killLocked()。
这里查杀过程使用的是倒序遍历,即将各个 area 中相对活跃的 cached/empty 先算入计数器从而避免被杀,并且确保了一个较粗粒度的进程优先级:activity area > service area > non-service area。
memory factor 和 trim memory
前面维护的是 cache/empty 进程的数量平衡。但这显然是不够的,因为运行当中的 non-cached/empty 可能会占用大量内存,AOSP 也需要对这部分进程进行管理。此时引入了新的概念——内存因子(memory factor),来衡量当前内存使用的压力情况。
AOSP 实现了一个 updateLowMemStateLSP 函数,它使用 Linux 中的 PSI 指标来监视 memory stall 的事件。
注:
PSI相关代码在这里:com_android_server_am_LowMemDetector.cpp - Android Code Search。
注:这个
updateLowMemStateLSP函数的调用时机是紧接着上述updateAndTrimProcessLSP执行的。
一些具体的指标如下:
- 无事件到来,则认为是 none(
Java端对应于ADJ_MEM_FACTOR_NORMAL字段)。 - 1s 内发生 SOME 级别的 15ms stall,则认为是 low(
ADJ_MEM_FACTOR_MODERATE)。 - 1s 内发生 FULL 级别的 30ms stall,则认为是 medium(
ADJ_MEM_FACTOR_LOW)。 - 1s 内发生 FULL 级别的 50ms stall,则认为是 high(
ADJ_MEM_FACTOR_CRITICAL)。
而在一些旧的内核版本无法支持 PSI 指标时,AOSP 是通过检测当前 cached 和 empty 的进程个数来确认:
ADJ_MEM_FACTOR_NORMAL: cache > 5 || empty > 8ADJ_MEM_FACTOR_MODERATE: cache <= 5 && empty <= 8 && cache + empty > 5ADJ_MEM_FACTOR_LOW: cache + empty <= 5ADJ_MEM_FACTOR_CRITICAL: cache + empty <= 3
只要有事件到来(意味着存在着一定的内存压力),那就会触发一定程度的 trim memory。
而 trim memory 的设计诀窍是要求用户(app 开发者)配合,如果不配合,那自求多福(指下一个杀的就是你)。具体一点指的是让 app 主动释放内存,OS 会提供一个回调接口 onTrimMemory(level),开发者根据 OS 提示的 level 设计分级的内存回收机制,释放不是必要的内存资源,比如已加载的图片、不再显示的 UI、非必须的服务等。
首先这里有 2 个维度:trim memory level 和 trim 进程的划分。
trim memory level 的分类和说明可以见这里。不过问题在于它的说明也比较含糊,只是作为一个 OS 上报给应用层回调接口的一个提示。一个说明不太细致的总结如下:
| 划分标准 | trim 等级及说明 |
|---|---|
| 按 LRU 位置 | · TRIM_MEMORY_COMPLETE:最高级别,进程位于 LRU 末端,最容易被杀进程盯上· TRIM_MEMORY_MODERATE:大约位于 LRU 中部· TRIM_MEMORY_BACKGROUND:其余的情况,但触发了回调,可进行一定的清理
|
| 按 UI 可见性变化 | · TRIM_MEMORY_UI_HIDDEN:进程曾经显示过 UI,但以后都不会有机会用到,需要释放这些资源
|
| 按 app 运行状态 | · TRIM_MEMORY_RUNNING_CRITICAL:OS 已进入极低内存状态,难以支撑后台进程,当前进程并非是后台进程· TRIM_MEMORY_RUNNING_LOW:OS 已进入低内存状态,当前进程并非是后台进程,不会被杀· TRIM_MEMORY_RUNNING_MODERATE:OS 已进入轻微低内存状态,当前进程并非是后台进程
|
注:注释的
TRIM_MEMORY_COMPLETE说到“进程位于 LRU 末端”,在上面的 LRU 图示中其实是 LRU 的前一段。
至于传递给回调接口的 level 是怎么决定的,先了解下 trim 进程的划分吧。这里需要说明 framework 并没有定义 trim 进程(作为一个严格的分类),而是把 HOME 进程优先级以下的进程都是作为 trim 进程,而其它的则算是 foreground 进程。
注:除了 trim 进程以外,实现上还有 heavy weight process 这个特殊情况,但是
AOSP并没有在实际运行的情况下用到它(但是国产 ROM 会用到,别问为什么,问就是云控用户体验)。
注:进程优先级后面会说。
当触发事件时,memory factor 会决定 foreground 进程的 trim 等级,即 fgTrimLevel,对应于 TRIM_MEMORY_LEVEL_*,比如:ADJ_MEM_FACTOR_MODERATE 对应于 TRIM_MEMORY_RUNNING_MODERATE。
而其它的 trim 进程则分为 3 个桶,按照 trim 进程在 LRU 列表的前后顺序,依次是:
- 前 1/3 的进程:
TRIM_MEMORY_COMPLETE。 - 中间 1/3 的进程:
TRIM_MEMORY_MODERATE。 - 后 1/3 的进程:
TRIM_MEMORY_BACKGROUND。
总结就是,trim 进程按照 LRU 位置提供 level,foreground 进程按照 app 运行状态提供 level。
注:不管 trim 还是 foreground 都会在合适时机针对 UI 可见性变化提供
level。
注:trim 操作还涉及到其它的硬件资源上的回收,这里不做介绍
(我不懂渲染绘制)。
进程的优先级和 OOM adjustment
很显然不该相信用户,AOSP 有另一套措施——根据 app 在运行时的状态进行评分,评分表现不好的,就会被强制裁决。
ProcessRecord 会按照运行时的状态区分出不同类型的进程。
可参考代码:ActivityManager.java - Android Code Search。
| 进程状态 | 说明 |
|---|---|
PROCESS_STATE_UNKNOWN
| Not a real process state. |
PROCESS_STATE_PERSISTENT
| Process is a persistent system process. |
PROCESS_STATE_PERSISTENT_UI
| Process is a persistent system process and is doing UI. |
PROCESS_STATE_TOP
| Process is hosting the current top activities. Note that this covers all activities that are visible to the user. |
PROCESS_STATE_BOUND_TOP
| Process is bound to a TOP app. |
PROCESS_STATE_FOREGROUND_SERVICE
| Process is hosting a foreground service. |
PROCESS_STATE_BOUND_FOREGROUND_SERVICE
| Process is hosting a foreground service due to a system binding. |
PROCESS_STATE_IMPORTANT_FOREGROUND
| Process is important to the user, and something they are aware of. |
PROCESS_STATE_IMPORTANT_BACKGROUND
| Process is important to the user, but not something they are aware of. |
PROCESS_STATE_TRANSIENT_BACKGROUND
| Process is in the background transient so we will try to keep running. |
PROCESS_STATE_BACKUP
| Process is in the background running a backup/restore operation. |
PROCESS_STATE_SERVICE
| Process is in the background running a service. Unlike oom_adj, this level is used for both the normal running in background state and the executing operations state. |
PROCESS_STATE_RECEIVER
| Process is in the background running a receiver. Note that from the perspective of oom_adj, receivers run at a higher foreground level, but for our prioritization here that is not necessary and putting them below services means many fewer changes in some process states as they receive broadcasts. |
PROCESS_STATE_TOP_SLEEPING
| Same as {@link #PROCESS_STATE_TOP} but while device is sleeping. |
PROCESS_STATE_HEAVY_WEIGHT
| Process is in the background, but it can’t restore its state so we want to try to avoid killing it. |
PROCESS_STATE_HOME
| Process is in the background but hosts the home activity. |
PROCESS_STATE_LAST_ACTIVITY
| Process is in the background but hosts the last shown activity. |
PROCESS_STATE_CACHED_ACTIVITY
| Process is being cached for later use and contains activities. |
PROCESS_STATE_CACHED_ACTIVITY_CLIENT
| Process is being cached for later use and is a client of another cached process that contains activities. |
PROCESS_STATE_CACHED_RECENT
| Process is being cached for later use and has an activity that corresponds to an existing recent task. |
PROCESS_STATE_CACHED_EMPTY
| Process is being cached for later use and is empty. |
PROCESS_STATE_NONEXISTENT
| Process does not exist. |
这些进程状态可以提供给 OOM adjuster 做参考,影响 adj 打分机制。
注:也可用于帮助开发者排查问题时了解当前进程的所处的状态,它可以
dump出来。
注:
adj的名字来自于Linux下sysfs文件系统给出的oom_adj_score接口(但是时过境迁,AOSP 已经在内存管理上去 kernel 化,尽可能在 user space 层面解决问题,因此把 kernel shrinker 移除了)。
事实上 adj 也有类似的数值区分,数值越小,表示优先级(进程的重要程度)越高。
| ADJ | 值 | 说明 |
|---|---|---|
INVALID_ADJ
| -10000 | Uninitialized value for any major or minor adj fields |
UNKNOWN_ADJ
| 1001 | Adjustment used in certain places where we don’t know it yet. (Generally this is something that is going to be cached, but we don’t know the exact value in the cached range to assign yet.) |
CACHED_APP_MAX_ADJ CACHED_APP_MIN_ADJ
| 999 900 | This is a process only hosting activities that are not visible, so it can be killed without any disruption. |
CACHED_APP_LMK_FIRST_ADJ
| 950 | This is the oom_adj level that we allow to die first. This cannot be equal to CACHED_APP_MAX_ADJ unless processes are actively being assigned an oom_score_adj of CACHED_APP_MAX_ADJ. |
SERVICE_B_ADJ
| 800 | The B list of SERVICE_ADJ – these are the old and decrepit services that aren’t as shiny and interesting as the ones in the A list. |
PREVIOUS_APP_ADJ
| 700 | This is the process of the previous application that the user was in. This process is kept above other things, because it is very common to switch back to the previous app. This is important both for recent task switch (toggling between the two top recent apps) as well as normal UI flow such as clicking on a URI in the e-mail app to view in the browser, and then pressing back to return to e-mail. |
HOME_APP_ADJ
| 600 | This is a process holding the home application – we want to try avoiding killing it, even if it would normally be in the background, because the user interacts with it so much. |
SERVICE_ADJ
| 500 | This is a process holding an application service – killing it will not have much of an impact as far as the user is concerned. |
HEAVY_WEIGHT_APP_ADJ
| 400 | This is a process with a heavy-weight application. It is in the background, but we want to try to avoid killing it. Value set in system/rootdir/init.rc on startup. |
BACKUP_APP_ADJ
| 300 | This is a process currently hosting a backup operation. Killing it is not entirely fatal but is generally a bad idea. |
PERCEPTIBLE_LOW_APP_ADJ
| 250 | This is a process bound by the system (or other app) that’s more important than services but not so perceptible that it affects the user immediately if killed. |
PERCEPTIBLE_MEDIUM_APP_ADJ
| 225 | This is a process hosting services that are not perceptible to the user but the client (system) binding to it requested to treat it as if it is perceptible and avoid killing it if possible. |
PERCEPTIBLE_APP_ADJ
| 200 | This is a process only hosting components that are perceptible to the user, and we really want to avoid killing them, but they are not immediately visible. An example is background music playback. |
VISIBLE_APP_ADJ
| 100 | This is a process only hosting activities that are visible to the user, so we’d prefer they don’t disappear. |
PERCEPTIBLE_RECENT_ FOREGROUND_APP_ADJ
| 50 | This is a process that was recently TOP and moved to FGS. Continue to treat it almost like a foreground app for a while. see TOP_TO_FGS_GRACE_PERIOD |
FOREGROUND_APP_ADJ
| 0 | This is the process running the current foreground app. We’d really rather not kill it! |
PERSISTENT_SERVICE_ADJ
| -700 | This is a process that the system or a persistent process has bound to, and indicated it is important. |
PERSISTENT_PROC_ADJ
| -800 | This is a system persistent process, such as telephony. Definitely don’t want to kill it, but doing so is not completely fatal. |
SYSTEM_ADJ
| -900 | The system process runs at the default adjustment. |
NATIVE_ADJ
| -1000 | Special code for native processes that are not being managed by the system (so don’t have an oom adj assigned by the system). |
注:为什么既有
PROC_STATE又有adj,这两个 info 看着是高度重合的啊?其实作者在 README 提到,进程状态是给上层server看的,而adj是给下层lmkd使用。
这个 adj 评分机制分为 3 个步骤:
- update:updateOOomAdjLocked(String reason)触发
OOM adjuster流程。 - compute:computeOomAdjLSP()计算
adj。 - apply:applyOomAdjLSP()应用
adj。
就具体实现来说,其计算过程非常非常复杂,这里只提一些实现上的关键路径。同样你可以先看看作者写的 README 来获得灵感。
首先是 update 过程的调用时机,代码层面的 references 比较复杂,但你可以从一些 reason 中得知,基本就是组件发生更新操作时都会调用:
static final String TAG = "OomAdjuster";
static final String OOM_ADJ_REASON_METHOD = "updateOomAdj";
static final String OOM_ADJ_REASON_NONE = OOM_ADJ_REASON_METHOD + "_meh";
static final String OOM_ADJ_REASON_ACTIVITY = OOM_ADJ_REASON_METHOD + "_activityChange";
static final String OOM_ADJ_REASON_FINISH_RECEIVER = OOM_ADJ_REASON_METHOD + "_finishReceiver";
static final String OOM_ADJ_REASON_START_RECEIVER = OOM_ADJ_REASON_METHOD + "_startReceiver";
static final String OOM_ADJ_REASON_BIND_SERVICE = OOM_ADJ_REASON_METHOD + "_bindService";
static final String OOM_ADJ_REASON_UNBIND_SERVICE = OOM_ADJ_REASON_METHOD + "_unbindService";
static final String OOM_ADJ_REASON_START_SERVICE = OOM_ADJ_REASON_METHOD + "_startService";
static final String OOM_ADJ_REASON_GET_PROVIDER = OOM_ADJ_REASON_METHOD + "_getProvider";
static final String OOM_ADJ_REASON_REMOVE_PROVIDER = OOM_ADJ_REASON_METHOD + "_removeProvider";
static final String OOM_ADJ_REASON_UI_VISIBILITY = OOM_ADJ_REASON_METHOD + "_uiVisibility";
static final String OOM_ADJ_REASON_ALLOWLIST = OOM_ADJ_REASON_METHOD + "_allowlistChange";
static final String OOM_ADJ_REASON_PROCESS_BEGIN = OOM_ADJ_REASON_METHOD + "_processBegin";
static final String OOM_ADJ_REASON_PROCESS_END = OOM_ADJ_REASON_METHOD + "_processEnd";
update 是一个无返回的操作,只是一个 OOM adjuster 的入口,其操作可以简化为:
- 指定单个进程,partial list 或者整个 LRU list 进行
compute计算。 - 完成后尝试
trim memory(即OOM adjuster是trim memory的 caller)。
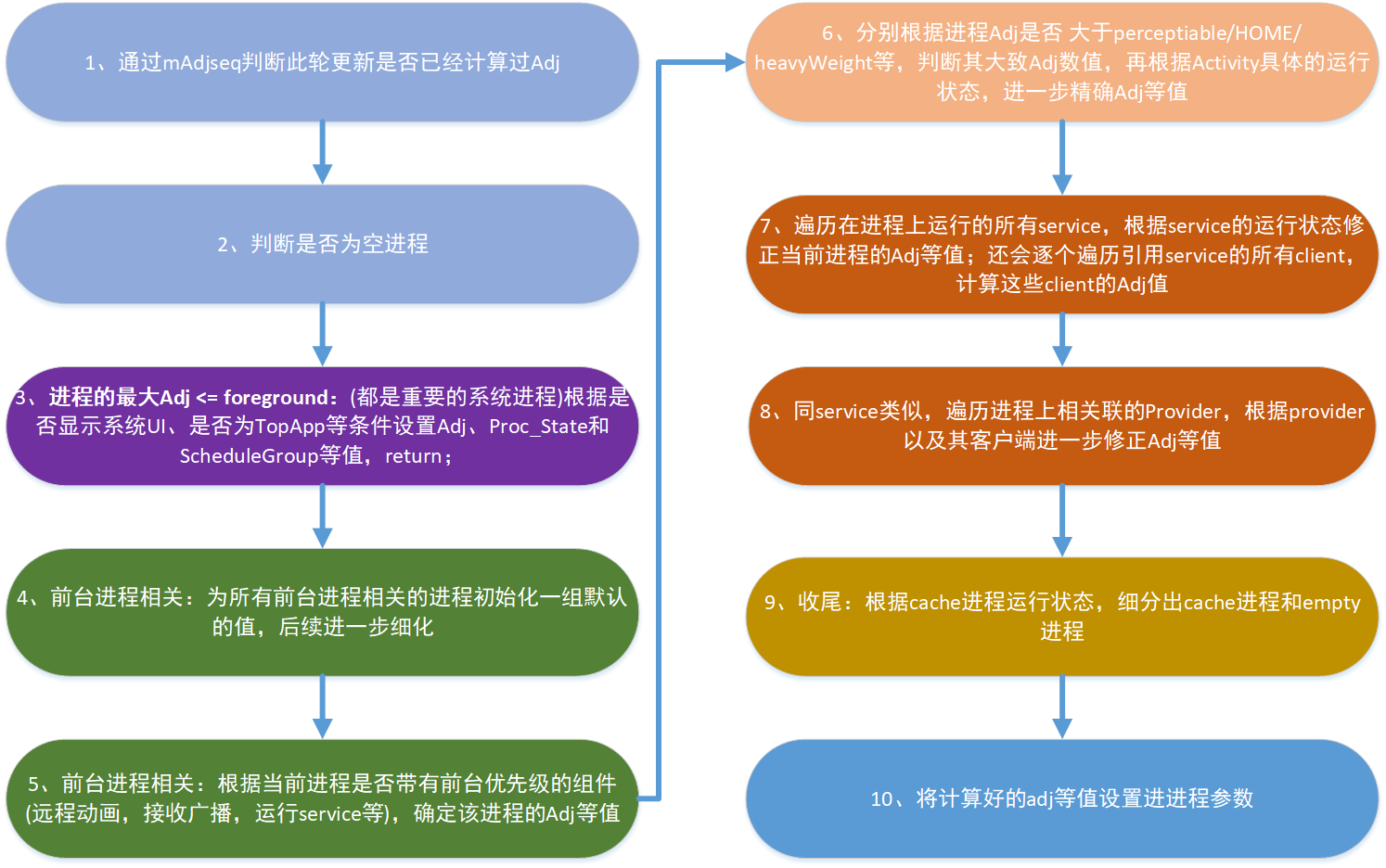
而 compute 阶段则是计算 adj、更新 procstate(并同时调整进程调度组的优先级)的算法,它会考虑多个方面来决定:
- 是否前台、亮屏。
- 是否运行
service和contentProvider。 - 是否特殊进程:如
persistent、systemNoUI。 - 是否使用特殊的
feature:如TREAT_LIKE_ACTIVITY。 - 其他略。
一个简单的流程图如下(图源自小米技术分享,无链接):
整个流程计算后可得到以下汇总图表(图源):
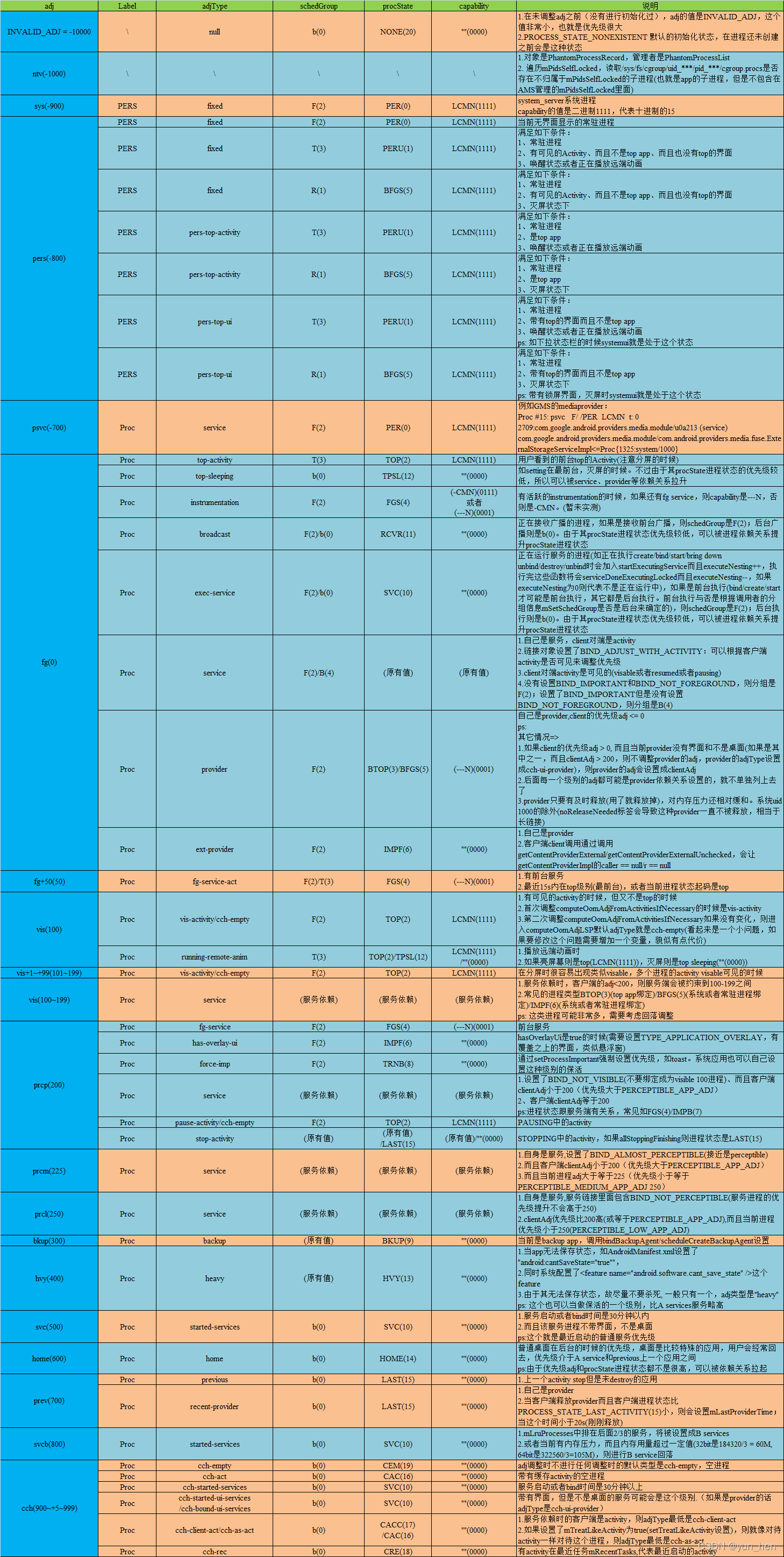
当 OOM adjuster 计算完成后,ProcessRecord 对应的 adj 和 state 将会更新,后续会将 adj 通过 apply 操作下发到 lowmemorykiller:caller 和 callee 见链接高亮处,其关键是使用 LMK_PROPRIO 的报文头与 lowmemorykiller 进行 socket 通信。
交接给 lowmemorykiller 后,framework 的工作先到此为止了!
lowmemorykiller
lowermemorykiller 简称 lmkd,是一个 daemon 进程,不受 system server 管理,但必要时可以通过 socket 进行通信,因此从 lmkd 的角度来看,我们前面所说的 server 其实(相对于 lmkd)是一个 client。
前面说到,OOM adjuster 的 apply 操作使用 LMK_PROPRIO 作为一个报文头进行 socket 通信。其实不只 PROPRIO,这些 command(lmk_cmd)都定义在 lmkd.h 头文件中,如代码所示:
/*
* Supported LMKD commands
*/
enum lmk_cmd {
LMK_TARGET = 0, /* Associate minfree with oom_adj_score */
LMK_PROCPRIO, /* Register a process and set its oom_adj_score */
LMK_PROCREMOVE, /* Unregister a process */
LMK_PROCPURGE, /* Purge all registered processes */
LMK_GETKILLCNT, /* Get number of kills */
LMK_SUBSCRIBE, /* Subscribe for asynchronous events */
LMK_PROCKILL, /* Unsolicited msg to subscribed clients on proc kills */
LMK_UPDATE_PROPS, /* Reinit properties */
LMK_STAT_KILL_OCCURRED, /* Unsolicited msg to subscribed clients on proc kills for statsd log */
LMK_STAT_STATE_CHANGED, /* Unsolicited msg to subscribed clients on state changed */
};
但是要想知道 lmkd 如何通信,得先明白 lmkd 是怎么运行的。
首先,lmkd 的启动由 init 进程通过解析 init.rc 文件的命令来完成的:
# Start lmkd before any other services run so that it can register them
write /proc/sys/vm/watermark_boost_factor 0
chown root system /sys/module/lowmemorykiller/parameters/adj
chmod 0664 /sys/module/lowmemorykiller/parameters/adj
chown root system /sys/module/lowmemorykiller/parameters/minfree
chmod 0664 /sys/module/lowmemorykiller/parameters/minfree
start lmkd
lmkd 启动后则会进入 main 主函数,整体来看是做了两件事情:
这些代码相对比较简短,我就直接贴上代码解析吧。
初始化流程
初始化流程代码如下:
static int init(void) {
static struct event_handler_info kernel_poll_hinfo = { 0, kernel_event_handler };
struct reread_data file_data = {
.filename = ZONEINFO_PATH,
.fd = -1,
};
struct epoll_event epev;
int pidfd;
int i;
int ret;
// 获取 page 大小,按 KB 算
page_k = sysconf(_SC_PAGESIZE);
if (page_k == -1)
page_k = PAGE_SIZE;
page_k /= 1024;
// 构造 epfd
epollfd = epoll_create(MAX_EPOLL_EVENTS);
if (epollfd == -1) {
ALOGE("epoll_create failed (errno=%d)", errno);
return -1;
}
// mark data connections as not connected
// data socket 的数据结构是
// static struct sock_event_handler_info data_sock[MAX_DATA_CONN];
// MAX_DATA_CONN 为 3,表示支持 AMS,init,test 各有一个 socket 连接
for (int i = 0; i < MAX_DATA_CONN; i++) {
data_sock[i].sock = -1;
}
// 构造 lmkd 的 control socket,后续作为 listen fd 使用
ctrl_sock.sock = android_get_control_socket("lmkd");
if (ctrl_sock.sock < 0) {
ALOGE("get lmkd control socket failed");
return -1;
}
// 开始监听
ret = listen(ctrl_sock.sock, MAX_DATA_CONN);
if (ret < 0) {
ALOGE("lmkd control socket listen failed (errno=%d)", errno);
return -1;
}
epev.events = EPOLLIN;
// 这里 ctrl_connect_handler 是用于 accept 系统调用来接收 client
// 并且为各个 client(如 AMS)提供 callback 为 ctrl_data_handler
ctrl_sock.handler_info.handler = ctrl_connect_handler;
epev.data.ptr = (void *)&(ctrl_sock.handler_info);
// 挂到 epoll 上去
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, ctrl_sock.sock, &epev) == -1) {
ALOGE("epoll_ctl for lmkd control socket failed (errno=%d)", errno);
return -1;
}
maxevents++;
has_inkernel_module = !access(INKERNEL_MINFREE_PATH, W_OK);
use_inkernel_interface = has_inkernel_module;
// 自 Linux4.12 后就不使用 kernel shrinker 了
// 认为 use_inkernel_interface == false,略
if (use_inkernel_interface) {
ALOGI("Using in-kernel low memory killer interface");
if (init_poll_kernel()) {
epev.events = EPOLLIN;
epev.data.ptr = (void*)&kernel_poll_hinfo;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, kpoll_fd, &epev) != 0) {
ALOGE("epoll_ctl for lmk events failed (errno=%d)", errno);
close(kpoll_fd);
kpoll_fd = -1;
} else {
maxevents++;
/* let the others know it does support reporting kills */
property_set("sys.lmk.reportkills", "1");
}
}
} else {
// 见 PSI 流程
if (!init_monitors()) {
return -1;
}
/* let the others know it does support reporting kills */
property_set("sys.lmk.reportkills", "1");
}
// 相关数据结构
// #define ADJTOSLOT(adj) ((adj) + -OOM_SCORE_ADJ_MIN)
// #define ADJTOSLOT_COUNT (ADJTOSLOT(OOM_SCORE_ADJ_MAX) + 1)
// static struct adjslot_list procadjslot_list[ADJTOSLOT_COUNT];
// struct adjslot_list {
// struct adjslot_list *next;
// struct adjslot_list *prev;
// };
for (i = 0; i <= ADJTOSLOT(OOM_SCORE_ADJ_MAX); i++) {
procadjslot_list[i].next = &procadjslot_list[i];
procadjslot_list[i].prev = &procadjslot_list[i];
}
// 相关数据结构
// /*
// * Because killcnt array is sparse a two-level indirection is used
// * to keep the size small. killcnt_idx stores index of the element in
// * killcnt array. Index KILLCNT_INVALID_IDX indicates an unused slot.
// */
// static uint8_t killcnt_idx[ADJTOSLOT_COUNT];
// static uint16_t killcnt[MAX_DISTINCT_OOM_ADJ];
// static int killcnt_free_idx = 0;
// static uint32_t killcnt_total = 0;
memset(killcnt_idx, KILLCNT_INVALID_IDX, sizeof(killcnt_idx));
/*
* Read zoneinfo as the biggest file we read to create and size the initial
* read buffer and avoid memory re-allocations during memory pressure
*/
if (reread_file(&file_data) == NULL) {
ALOGE("Failed to read %s: %s", file_data.filename, strerror(errno));
}
/* check if kernel supports pidfd_open syscall */
// 我也不太懂 pidfd 机制 orz
// 这里认为是不支持
pidfd = TEMP_FAILURE_RETRY(pidfd_open(getpid(), 0));
if (pidfd < 0) {
pidfd_supported = (errno != ENOSYS);
} else {
pidfd_supported = true;
close(pidfd);
}
ALOGI("Process polling is %s", pidfd_supported ? "supported" : "not supported" );
// 提供 hook 机制,有需要的话就用
if (!lmkd_init_hook()) {
ALOGE("Failed to initialize LMKD hooks.");
return -1;
}
return 0;
}
总结如下:
- 构造
epoll实例。 - 构造
lmkd自身的control socket,启用listen作为一个server接收client。 - 注册接收回调后,把
control socket挂入到epoll当中。 - 初始化
PSI事件监听。
强硬插入广告:如果你不太了解 epoll,可以来看下我的文章:epoll in depth。
先说 server 注册部分,lmkd 是自身作为一个监听 server,构建一个名为 ctrl_socket 的 socket 描述符,使用 listen 并挂入 epoll 来等待事件,事件到达后则 accept 对应的 client,见回调函数 ctrl_connect_handler:
static void ctrl_connect_handler(int data __unused, uint32_t events __unused,
struct polling_params *poll_params __unused) {
struct epoll_event epev;
int free_dscock_idx = get_free_dsock();
if (free_dscock_idx < 0) {
/*
* Number of data connections exceeded max supported. This should not
* happen but if it does we drop all existing connections and accept
* the new one. This prevents inactive connections from monopolizing
* data socket and if we drop ActivityManager connection it will
* immediately reconnect.
*/
for (int i = 0; i < MAX_DATA_CONN; i++) {
ctrl_data_close(i);
}
free_dscock_idx = 0;
}
data_sock[free_dscock_idx].sock = accept(ctrl_sock.sock, NULL, NULL);
if (data_sock[free_dscock_idx].sock < 0) {
ALOGE("lmkd control socket accept failed; errno=%d", errno);
return;
}
ALOGI("lmkd data connection established");
/* use data to store data connection idx */
data_sock[free_dscock_idx].handler_info.data = free_dscock_idx;
data_sock[free_dscock_idx].handler_info.handler = ctrl_data_handler;
data_sock[free_dscock_idx].async_event_mask = 0;
epev.events = EPOLLIN;
epev.data.ptr = (void *)&(data_sock[free_dscock_idx].handler_info);
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, data_sock[free_dscock_idx].sock, &epev) == -1) {
ALOGE("epoll_ctl for data connection socket failed; errno=%d", errno);
ctrl_data_close(free_dscock_idx);
return;
}
maxevents++;
}
实际上 lmkd 能接受的 client 类型是有限的,见 MAX_EPOLL_EVENTS:
/*
* 1 ctrl listen socket, 3 ctrl data socket, 3 memory pressure levels,
* 1 lmk events + 1 fd to wait for process death + 1 fd to receive kill failure notifications
*/
#define MAX_EPOLL_EVENTS (1 + MAX_DATA_CONN + VMPRESS_LEVEL_COUNT + 1 + 1 + 1)
// 第一个 1 表示 listen socket
// DATA_CONN 指的是连接的客户端,设为 3
// 包括 AMS,init,test
// VMPRRESS_LEVEL 有 3 种,
// 包括 LOW,MEDIUM,CRITICAL
// 后续 3 个 1 表示:
// • lmk 事件
// • 等待进程死亡
// • 查杀失败通知
除此以外,初始化流程还有 PSI 的初始化 init_psi_monitors(还记得 PSI 吗,前面章节有讲过):
static bool init_psi_monitors() {
/*
* When PSI is used on low-ram devices or on high-end devices without memfree levels
* use new kill strategy based on zone watermarks, free swap and thrashing stats.
* Also use the new strategy if memcg has not been mounted in the v1 cgroups hiearchy since
* the old strategy relies on memcg attributes that are available only in the v1 cgroups
* hiearchy.
*/
// 默认情况下 use_minfree_levels 是 false
// 因此 use_new_strategy 是 true
bool use_new_strategy =
GET_LMK_PROPERTY(bool, "use_new_strategy", low_ram_device || !use_minfree_levels);
// 旧策略仅支持 v1 cgroup
if (!use_new_strategy && memcg_version() != MemcgVersion::kV1) {
ALOGE("Old kill strategy can only be used with v1 cgroup hierarchy");
return false;
}
/* In default PSI mode override stall amounts using system properties */
// 新策略指的就是覆盖默认的 PSI 指标,以及事件到来后使用不同的 handler
if (use_new_strategy) {
/* Do not use low pressure level */
// psi_thresholds 默认值见下方,监听窗口为 1s
// 这里总结就是:
// - low: ignored
// - medium: some, 70ms
// - critical: full, 700ms
// (也可以通过 AMS 的指令来修改)
// 见这里:https://cs.android.com/android/platform/superproject/+/android-13.0.0_r18:system/memory/lmkd/lmkd.cpp;l=3765
psi_thresholds[VMPRESS_LEVEL_LOW].threshold_ms = 0;
psi_thresholds[VMPRESS_LEVEL_MEDIUM].threshold_ms = psi_partial_stall_ms;
psi_thresholds[VMPRESS_LEVEL_CRITICAL].threshold_ms = psi_complete_stall_ms;
}
// 应用层决定好 PSI 监控指标后,这里会注册回调和开始监听
// 如果 threshold_ms 为 0,那就不干任何事情
if (!init_mp_psi(VMPRESS_LEVEL_LOW, use_new_strategy)) {
return false;
}
if (!init_mp_psi(VMPRESS_LEVEL_MEDIUM, use_new_strategy)) {
destroy_mp_psi(VMPRESS_LEVEL_LOW);
return false;
}
if (!init_mp_psi(VMPRESS_LEVEL_CRITICAL, use_new_strategy)) {
destroy_mp_psi(VMPRESS_LEVEL_MEDIUM);
destroy_mp_psi(VMPRESS_LEVEL_LOW);
return false;
}
return true;
}
// 一些 PSI 默认值{stall type, threshold (ms)},但是会被覆盖
static struct psi_threshold psi_thresholds[VMPRESS_LEVEL_COUNT] = {
{ PSI_SOME, 70 }, /* 70ms out of 1sec for partial stall */
{ PSI_SOME, 100 }, /* 100ms out of 1sec for partial stall */
{ PSI_FULL, 70 }, /* 70ms out of 1sec for complete stall */
};
static bool init_mp_psi(enum vmpressure_level level, bool use_new_strategy) {
int fd;
/* Do not register a handler if threshold_ms is not set */
// low 不干任何事情
if (!psi_thresholds[level].threshold_ms) {
return true;
}
// 构造 psi fd,后续 register 挂到 epoll 里去,PSI 窗口固定 1s
fd = init_psi_monitor(psi_thresholds[level].stall_type,
psi_thresholds[level].threshold_ms * US_PER_MS,
PSI_WINDOW_SIZE_MS * US_PER_MS);
if (fd < 0) {
return false;
}
// 监听到事件后的回调,即 mp_event_psi
vmpressure_hinfo[level].handler = use_new_strategy ? mp_event_psi : mp_event_common;
// 私有 data 就传递压力 level
vmpressure_hinfo[level].data = level;
// 把 psi fd 挂到 epoll 上
if (register_psi_monitor(epollfd, fd, &vmpressure_hinfo[level]) < 0) {
destroy_psi_monitor(fd);
return false;
}
maxevents++;
// 一个 level 到 fd 的映射
mpevfd[level] = fd;
return true;
}
PSI 指标会监听以下事件:
medium: some, 70mscritical: full, 700ms
并且对应的事件会注册回调 mp_event_psi,我们后面再聊。
主循环流程
主循环是很简单的,你可认为是不断等待事件并执行回调,伪代码如下:
LOOP:
n <- epoll_wait()
for e in n events:
e->call_handler()
goto LOOP
注:对于
epoll_wait的超时参数,以及触发事件后是否立刻处理等细节,lmkd是用一个poll_params的数据结构来单独控制,感兴趣你可以翻代码看下实现细节。
这里要关注的是有哪些事件,前面已提到了 2 种最为关键的事件集合:
PSI的 memory stall 事件mp_event_psiclient的command事件ctrl_command_handler
PSI 事件
先看 PSI 事件:
static void mp_event_psi(int data, uint32_t events, struct polling_params *poll_params) {
enum reclaim_state {
NO_RECLAIM = 0,
KSWAPD_RECLAIM,
DIRECT_RECLAIM,
};
// 关于 refault
// 可参考:https://zhuanlan.zhihu.com/p/502768917
// 首次获取会从 vmstat 解析得到的 workingset_refault_file 赋值给 init_ws_refault
static int64_t init_ws_refault;
static int64_t prev_workingset_refault;
// LRU 大小 = inactive + active
static int64_t base_file_lru;
// kswapd 扫到的 page
static int64_t init_pgscan_kswapd;
static int64_t init_pgscan_direct;
static bool killing;
// 抖动界限,普通设备 100,低内存 30
// README 文件介绍:
// number of workingset refaults as a percentage of the file-backed pagecache size
// used as a threshold to consider system thrashing its pagecache.
// 就是 refault 占比
static int thrashing_limit = thrashing_limit_pct;
// zone 得到的水位
static struct zone_watermarks watermarks;
static struct timespec wmark_update_tm;
static struct wakeup_info wi;
static struct timespec thrashing_reset_tm;
static int64_t prev_thrash_growth = 0;
static bool check_filecache = false;
// max_thrashing 并不参与实际计算
// 仅作为 INFO 日志参考
static int max_thrashing = 0;
union meminfo mi;
union vmstat vs;
struct psi_data psi_data;
struct timespec curr_tm;
// 当前的 page cache 抖动值
int64_t thrashing = 0;
bool swap_is_low = false;
// PSI/vmpressure事件传来的压力level
enum vmpressure_level level = (enum vmpressure_level)data;
enum kill_reasons kill_reason = NONE;
bool cycle_after_kill = false;
enum reclaim_state reclaim = NO_RECLAIM;
enum zone_watermark wmark = WMARK_NONE;
char kill_desc[LINE_MAX];
bool cut_thrashing_limit = false;
int min_score_adj = 0;
int swap_util = 0;
int64_t swap_low_threshold;
long since_thrashing_reset_ms;
int64_t workingset_refault_file;
bool critical_stall = false;
if (clock_gettime(CLOCK_MONOTONIC_COARSE, &curr_tm) != 0) {
ALOGE("Failed to get current time");
return;
}
record_wakeup_time(&curr_tm, events ? Event : Polling, &wi);
bool kill_pending = is_kill_pending();
// 如果上一个被杀 pid 还在则为 true,且被杀间隔小于 100ms,则跳过本回合
if (kill_pending && (kill_timeout_ms == 0 ||
get_time_diff_ms(&last_kill_tm, &curr_tm) < static_cast<long>(kill_timeout_ms))) {
/* Skip while still killing a process */
wi.skipped_wakeups++;
goto no_kill;
}
/*
* Process is dead or kill timeout is over, stop waiting. This has no effect if pidfds are
* supported and death notification already caused waiting to stop.
*/
// 如果进程还在,就 wait
stop_wait_for_proc_kill(!kill_pending);
// 解析 vmstat,meminfo
if (vmstat_parse(&vs) < 0) {
ALOGE("Failed to parse vmstat!");
return;
}
/* Starting 5.9 kernel workingset_refault vmstat field was renamed workingset_refault_file */
workingset_refault_file = vs.field.workingset_refault ? : vs.field.workingset_refault_file;
// 对照这里的表做解析
// https://cs.android.com/android/platform/superproject/+/android-13.0.0_r18:system/memory/lmkd/lmkd.cpp;l=408
if (meminfo_parse(&mi) < 0) {
ALOGE("Failed to parse meminfo!");
return;
}
/* Reset states after process got killed */
if (killing) {
killing = false;
cycle_after_kill = true;
/* Reset file-backed pagecache size and refault amounts after a kill */
base_file_lru = vs.field.nr_inactive_file + vs.field.nr_active_file;
init_ws_refault = workingset_refault_file;
thrashing_reset_tm = curr_tm;
prev_thrash_growth = 0;
}
/* Check free swap levels */
if (swap_free_low_percentage) {
// swap_free_low_percentage 默认是 10
// README 介绍是有区分的,低端设备 10,高端设备有 20,但是代码中并没有体现出来
swap_low_threshold = mi.field.total_swap * swap_free_low_percentage / 100;
swap_is_low = mi.field.free_swap < swap_low_threshold;
} else {
swap_low_threshold = 0;
}
/* Identify reclaim state */
// 确认当前 kernel 的回收状态
if (vs.field.pgscan_direct > init_pgscan_direct) {
init_pgscan_direct = vs.field.pgscan_direct;
init_pgscan_kswapd = vs.field.pgscan_kswapd;
// 参考:https://zhuanlan.zhihu.com/p/72998605
// 这种状态下的内存回收会同步于内存分配操作,需要更高优先级的关注
reclaim = DIRECT_RECLAIM;
} else if (vs.field.pgscan_kswapd > init_pgscan_kswapd) {
init_pgscan_kswapd = vs.field.pgscan_kswapd;
// 没看出这个对于 lmkd 有啥用途
reclaim = KSWAPD_RECLAIM;
} else if (workingset_refault_file == prev_workingset_refault) {
/*
* Device is not thrashing and not reclaiming, bail out early until we see these stats
* changing
*/
goto no_kill;
}
prev_workingset_refault = workingset_refault_file;
/*
* It's possible we fail to find an eligible process to kill (ex. no process is
* above oom_adj_min). When this happens, we should retry to find a new process
* for a kill whenever a new eligible process is available. This is especially
* important for a slow growing refault case. While retrying, we should keep
* monitoring new thrashing counter as someone could release the memory to mitigate
* the thrashing. Thus, when thrashing reset window comes, we decay the prev thrashing
* counter by window counts. If the counter is still greater than thrashing limit,
* we preserve the current prev_thrash counter so we will retry kill again. Otherwise,
* we reset the prev_thrash counter so we will stop retrying.
*/
// 如果找不到 oom_adj_min 以上的进程
since_thrashing_reset_ms = get_time_diff_ms(&thrashing_reset_tm, &curr_tm);
// 每隔一段时间重置抖动参数
if (since_thrashing_reset_ms > THRASHING_RESET_INTERVAL_MS) {
long windows_passed;
/* Calculate prev_thrash_growth if we crossed THRASHING_RESET_INTERVAL_MS */
prev_thrash_growth = (workingset_refault_file - init_ws_refault) * 100
/ (base_file_lru + 1);
windows_passed = (since_thrashing_reset_ms / THRASHING_RESET_INTERVAL_MS);
/*
* Decay prev_thrashing unless over-the-limit thrashing was registered in the window we
* just crossed, which means there were no eligible processes to kill. We preserve the
* counter in that case to ensure a kill if a new eligible process appears.
*/
if (windows_passed > 1 || prev_thrash_growth < thrashing_limit) {
prev_thrash_growth >>= windows_passed;
}
/* Record file-backed pagecache size when crossing THRASHING_RESET_INTERVAL_MS */
base_file_lru = vs.field.nr_inactive_file + vs.field.nr_active_file;
init_ws_refault = workingset_refault_file;
thrashing_reset_tm = curr_tm;
thrashing_limit = thrashing_limit_pct;
// 在重置时间内,就更新当前抖动
} else {
/* Calculate what % of the file-backed pagecache refaulted so far */
thrashing = (workingset_refault_file - init_ws_refault) * 100 / (base_file_lru + 1);
}
/* Add previous cycle's decayed thrashing amount */
// 算上滑动窗口的衰减因子
thrashing += prev_thrash_growth;
if (max_thrashing < thrashing) {
max_thrashing = thrashing;
}
/*
* Refresh watermarks once per min in case user updated one of the margins.
* TODO: b/140521024 replace this periodic update with an API for AMS to notify LMKD
* that zone watermarks were changed by the system software.
*/
// 初始化/每一分钟刷新一次水位信息
if (watermarks.high_wmark == 0 || get_time_diff_ms(&wmark_update_tm, &curr_tm) > 60000) {
struct zoneinfo zi;
if (zoneinfo_parse(&zi) < 0) {
ALOGE("Failed to parse zoneinfo!");
return;
}
calc_zone_watermarks(&zi, &watermarks);
wmark_update_tm = curr_tm;
}
/* Find out which watermark is breached if any */
// 用 meminfo 中的 MemFree 减去 CmaFree,依次比较水位
// 返回高于该值的最低水位
wmark = get_lowest_watermark(&mi, &watermarks);
if (!psi_parse_mem(&psi_data)) {
// avg10 > 100??
// 整个系统已经 stall,后续会把 min_score_adj 设为 0
critical_stall = psi_data.mem_stats[PSI_FULL].avg10 > (float)stall_limit_critical;
}
/*
* TODO: move this logic into a separate function
* Decide if killing a process is necessary and record the reason
*/
// 下面一堆 if-else 是用于确认启动 kill 流程的条件
// 只要有 kill_reason,就会执行
//
// 仍在 killing 且 free 低于 low 水位
// 通常发生在压测
if (cycle_after_kill && wmark < WMARK_LOW) {
/*
* Prevent kills not freeing enough memory which might lead to OOM kill.
* This might happen when a process is consuming memory faster than reclaim can
* free even after a kill. Mostly happens when running memory stress tests.
*/
kill_reason = PRESSURE_AFTER_KILL;
strncpy(kill_desc, "min watermark is breached even after kill", sizeof(kill_desc));
// 内存压力出于 CRITICAL,从前面的分析得知,即 PSI FULL 700ms
// 此时意味着高压力回收导致 ANR
} else if (level == VMPRESS_LEVEL_CRITICAL && events != 0) {
/*
* Device is too busy reclaiming memory which might lead to ANR.
* Critical level is triggered when PSI complete stall (all tasks are blocked because
* of the memory congestion) breaches the configured threshold.
*/
kill_reason = NOT_RESPONDING;
strncpy(kill_desc, "device is not responding", sizeof(kill_desc));
// swap_is_low 意味着:meminfo 的 SwapFree 值小于 lmkd 阈值 swap_low_threshold(占比 10% 的 SwapTotal)
// 且 page cache 抖动已经大于限制
} else if (swap_is_low && thrashing > thrashing_limit_pct) {
/* Page cache is thrashing while swap is low */
kill_reason = LOW_SWAP_AND_THRASHING;
snprintf(kill_desc, sizeof(kill_desc), "device is low on swap (%" PRId64
"kB < %" PRId64 "kB) and thrashing (%" PRId64 "%%)",
mi.field.free_swap * page_k, swap_low_threshold * page_k, thrashing);
/* Do not kill perceptible apps unless below min watermark or heavily thrashing */
// thrashing_critical_pct 指的是 2 倍的 thrashing_limit_pct
if (wmark > WMARK_MIN && thrashing < thrashing_critical_pct) {
min_score_adj = PERCEPTIBLE_APP_ADJ + 1;
}
check_filecache = true;
} else if (swap_is_low && wmark < WMARK_HIGH) {
/* Both free memory and swap are low */
kill_reason = LOW_MEM_AND_SWAP;
snprintf(kill_desc, sizeof(kill_desc), "%s watermark is breached and swap is low (%"
PRId64 "kB < %" PRId64 "kB)", wmark < WMARK_LOW ? "min" : "low",
mi.field.free_swap * page_k, swap_low_threshold * page_k);
/* Do not kill perceptible apps unless below min watermark or heavily thrashing */
if (wmark > WMARK_MIN && thrashing < thrashing_critical_pct) {
min_score_adj = PERCEPTIBLE_APP_ADJ + 1;
}
// swap_util_max 默认 100,这里需要覆盖配置才启用
} else if (wmark < WMARK_HIGH && swap_util_max < 100 &&
// swap 利用率是怎么算的?
// https://cs.android.com/android/platform/superproject/+/android-13.0.0_r18:system/memory/lmkd/lmkd.cpp;l=2551
// 方法是解析 meminfo,推导如下
// (下面的小写下划线是应用层自定义的,大写驼峰是 meminfo 自带的信息)
// swap_used = SwapTotal - SwapFree
// total_swappable = Active(anon) + Inactive(anon) + Shmem + swap_used
// swap_util = swap_used / total_swappable * 100(%)
//
// 注:当前 master 分支改进了计算方式
// https://cs.android.com/android/_/android/platform/system/memory/lmkd/+/495db5c643a57be470a480642348af56028acde3
// swap_used = SwapTotal - min(SwapFree, easy_available)
// easy_available = MemFree + Inactive(file)
// 理由是 swap space is taken from the free memory or reclaimed
(swap_util = calc_swap_utilization(&mi)) > swap_util_max) {
/*
* Too much anon memory is swapped out but swap is not low.
* Non-swappable allocations created memory pressure.
*/
kill_reason = LOW_MEM_AND_SWAP_UTIL;
snprintf(kill_desc, sizeof(kill_desc), "%s watermark is breached and swap utilization"
" is high (%d%% > %d%%)", wmark < WMARK_LOW ? "min" : "low",
swap_util, swap_util_max);
} else if (wmark < WMARK_HIGH && thrashing > thrashing_limit) {
/* Page cache is thrashing while memory is low */
kill_reason = LOW_MEM_AND_THRASHING;
snprintf(kill_desc, sizeof(kill_desc), "%s watermark is breached and thrashing (%"
PRId64 "%%)", wmark < WMARK_LOW ? "min" : "low", thrashing);
cut_thrashing_limit = true;
/* Do not kill perceptible apps unless thrashing at critical levels */
if (thrashing < thrashing_critical_pct) {
min_score_adj = PERCEPTIBLE_APP_ADJ + 1;
}
check_filecache = true;
} else if (reclaim == DIRECT_RECLAIM && thrashing > thrashing_limit) {
/* Page cache is thrashing while in direct reclaim (mostly happens on lowram devices) */
kill_reason = DIRECT_RECL_AND_THRASHING;
snprintf(kill_desc, sizeof(kill_desc), "device is in direct reclaim and thrashing (%"
PRId64 "%%)", thrashing);
cut_thrashing_limit = true;
/* Do not kill perceptible apps unless thrashing at critical levels */
if (thrashing < thrashing_critical_pct) {
min_score_adj = PERCEPTIBLE_APP_ADJ + 1;
}
check_filecache = true;
// check_filecache 只在这些 killreason 过程中赋值 true
// 下一次触发时如果都不满足上述条件,但上一次已经触发某个条件,
// 则尝试确认 filecache
} else if (check_filecache) {
int64_t file_lru_kb = (vs.field.nr_inactive_file + vs.field.nr_active_file) * page_k;
// 可是不设置 property 的话
// filecache_min_kb 是 0
// 即不做处理
if (file_lru_kb < filecache_min_kb) {
/* File cache is too low after thrashing, keep killing background processes */
kill_reason = LOW_FILECACHE_AFTER_THRASHING;
snprintf(kill_desc, sizeof(kill_desc),
"filecache is low (%" PRId64 "kB < %" PRId64 "kB) after thrashing",
file_lru_kb, filecache_min_kb);
min_score_adj = PERCEPTIBLE_APP_ADJ + 1;
} else {
/* File cache is big enough, stop checking */
check_filecache = false;
}
}
/* Kill a process if necessary */
// 满足 kill 的条件
if (kill_reason != NONE) {
struct kill_info ki = {
.kill_reason = kill_reason,
.kill_desc = kill_desc,
.thrashing = (int)thrashing,
.max_thrashing = max_thrashing,
};
/* Allow killing perceptible apps if the system is stalled */
// 前面 PSI FULL 的判断会满足这个条件
// 通常在 kill_reason 确认时,min_score_adj 会被设为 PERCEPTIBLE_APP_ADJ + 1
// (但需要满足水位低于一定程度(小于等于 MIN)及 page cache 抖动达到 critical 阈值)
// 而这里 stall 严重就允许杀更高优先级的进程,0 对应着 FOREGROUND_APP_ADJ
if (critical_stall) {
min_score_adj = 0;
}
// 解析 psi 指标到 psi_data
psi_parse_io(&psi_data);
psi_parse_cpu(&psi_data);
// 返回的是被杀进程占有的 page
int pages_freed = find_and_kill_process(min_score_adj, &ki, &mi, &wi, &curr_tm, &psi_data);
// 如果查杀有正反馈
if (pages_freed > 0) {
killing = true;
max_thrashing = 0;
if (cut_thrashing_limit) {
/*
* Cut thrasing limit by thrashing_limit_decay_pct percentage of the current
* thrashing limit until the system stops thrashing.
*/
// thrashing_limit_decay_pct 介绍:
// thrashing threshold decay expressed as a percentage of the original threshold used to lower
// the threshold when system does not recover even after a kill
// 普通设备 10,低内存设备 50
thrashing_limit = (thrashing_limit * (100 - thrashing_limit_decay_pct)) / 100;
}
}
}
no_kill:
/* Do not poll if kernel supports pidfd waiting */
// 认为不支持 pidfd(返回 false),仍会继续轮询
if (is_waiting_for_kill()) {
/* Pause polling if we are waiting for process death notification */
poll_params->update = POLLING_PAUSE;
return;
}
/*
* Start polling after initial PSI event;
* extend polling while device is in direct reclaim or process is being killed;
* do not extend when kswapd reclaims because that might go on for a long time
* without causing memory pressure
*/
if (events || killing || reclaim == DIRECT_RECLAIM) {
poll_params->update = POLLING_START;
}
/* Decide the polling interval */
if (swap_is_low || killing) {
/* Fast polling during and after a kill or when swap is low */
// 比较急(低 swap 或者有杀到进程),把轮询间隔缩到 10ms
poll_params->polling_interval_ms = PSI_POLL_PERIOD_SHORT_MS;
} else {
/* By default use long intervals */
// 一般情况用是 100ms
poll_params->polling_interval_ms = PSI_POLL_PERIOD_LONG_MS;
}
}
总的来说,PSI 事件到来后,lmkd 会通过 meminfo 和 vmstat 来考察 page cache 的抖动情况,并结合一下其它因素(如 reclaim 的方式,当前的水位)来判定是否有一个 kill reason,如果有,则通过 find_and_kill_process 来真正执行杀进程操作。通常,传入的 min_score_adj 对应的是可感知进程以下的 adj 优先级,即不希望用户体验受到影响(视觉和听觉等感知)。
在继续了解查杀流程前,先这里补充一点:lmkd 维护的进程容器有别于 framework 下的 LRU list。它分别使用 2 个数据结构,一个是十字链表 adjslot_list,另一个是哈希表 pidhash。前者用于按照 adj 数值找到进程 proc,后者是按照 pid 找到 proc:
// 没有数据域的链表,侵入到 proc 中使用
struct adjslot_list {
struct adjslot_list *next;
struct adjslot_list *prev;
};
// 至少有 2 个途径可以找到 proc
// 如果已知 pid,则通过 pidhash_next 以及 pidhash 找到 proc(client 通过 CMD 指令传入 pid 要求 lmkd 干杂活时)
// 如果已知 adj,那么直接找 procadjslot_list 数组即可找到 proc(按 adj 杀进程时使用)
// 这两种方法都需要遍历
struct proc {
struct adjslot_list asl;
int pid;
int pidfd;
uid_t uid;
int oomadj;
pid_t reg_pid; /* PID of the process that registered this record */
bool valid;
struct proc *pidhash_next;
};
// 这个宏是修正下标负数的,把 minadj 给调整到 0
#define ADJTOSLOT(adj) ((adj) + -OOM_SCORE_ADJ_MIN)
// 即 COUNT = MAX - MIN + 1
#define ADJTOSLOT_COUNT (ADJTOSLOT(OOM_SCORE_ADJ_MAX) + 1)
// procadjslot_list should be modified only from the main thread while exclusively holding
// adjslot_list_lock. Readers from non-main threads should hold adjslot_list_lock shared lock.
//
// procadjslot_list 的初始化见 init 流程
// 就是 procadjslot_list[i].next = procadjslot_list[i].prev = procadjslot_list[i]
static struct adjslot_list procadjslot_list[ADJTOSLOT_COUNT];
#define PIDHASH_SZ 1024
// 如果已知 pid,可以通过 pidhash 桶遍历(结合 pidhash_next)得到对应的 proc
static struct proc *pidhash[PIDHASH_SZ];
// 简单的 hash,用于压缩桶个数
#define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1))
// 头插
static void adjslot_insert(struct adjslot_list *head, struct adjslot_list *new_element)
{
struct adjslot_list *next = head->next;
new_element->prev = head;
new_element->next = next;
next->prev = new_element;
head->next = new_element;
}
static void adjslot_remove(struct adjslot_list *old)
{
struct adjslot_list *prev = old->prev;
struct adjslot_list *next = old->next;
next->prev = prev;
prev->next = next;
}
// 从初始化和插入函数可知,仅有 head 并且指涉自身就是空,否则就是双向循环
static struct adjslot_list *adjslot_tail(struct adjslot_list *head) {
struct adjslot_list *asl = head->prev;
return asl == head ? NULL : asl;
}
// Should be modified only from the main thread.
// proc 的添加用于 cmd_procprio 指令
// 大概是 client 指定 pid,然后 pid_lookup 找到 proc,把对应的参数包括 oomadj 设为 client 指定数值
// 然后调用该函数插入 adjslot list 里面
static void proc_slot(struct proc *procp) {
int adjslot = ADJTOSLOT(procp->oomadj);
std::scoped_lock lock(adjslot_list_lock);
adjslot_insert(&procadjslot_list[adjslot], &procp->asl);
}
// Should be modified only from the main thread.
static void proc_unslot(struct proc *procp) {
std::scoped_lock lock(adjslot_list_lock);
adjslot_remove(&procp->asl);
}
static void proc_insert(struct proc *procp) {
// 简单对 pid 进行 hash
int hval = pid_hashfn(procp->pid);
// pidhash 默认值为 nullptr
// 用于后续传入 pid 参数找到 proc
// 找到后通过 for(;;) 遍历 proc->pidhash_next 得到下一个 proc
procp->pidhash_next = pidhash[hval];
// 此时 pidhash 桶入口就是 `procp`
pidhash[hval] = procp;
proc_slot(procp);
}
回到刚才已确定 kill reason 的流程里面,现在是进入 find_and_kill_process 流程:
/*
* Find one process to kill at or above the given oom_score_adj level.
* Returns size of the killed process.
*/
static int find_and_kill_process(int min_score_adj, struct kill_info *ki, union meminfo *mi,
struct wakeup_info *wi, struct timespec *tm,
struct psi_data *pd) {
int i;
int killed_size = 0;
bool lmk_state_change_start = false;
// 默认为 false
bool choose_heaviest_task = kill_heaviest_task;
// 从 max=1000 开始,到用户指定的 min_score_adj
// 虽然是一个 for 循环,但只需要收到一份正反馈就结束(杀死一个进程)
for (i = OOM_SCORE_ADJ_MAX; i >= min_score_adj; i--) {
struct proc *procp;
// 如果优先级已经高于可感知 adj,尝试挑选最为重量级(占内存最多)的进程,
// 这样可避免杀死更多的进程数
if (!choose_heaviest_task && i <= PERCEPTIBLE_APP_ADJ) {
/*
* If we have to choose a perceptible process, choose the heaviest one to
* hopefully minimize the number of victims.
*/
choose_heaviest_task = true;
}
// 只要杀到一个就足够了
while (true) {
procp = choose_heaviest_task ?
// proc_get_heaviest: 遍历当前 adj==i 的所有 task,找出 heaviest 的一个
// proc_adj_tail: 当前 adj 下的尾部元素,因为插入是头插的,因此尾部是最旧插入的
proc_get_heaviest(i) : proc_adj_tail(i);
if (!procp)
break;
// 调用 reaper 杀掉对应 procp
// 不考虑 async kill 的话,就是在 lmkd 里同步执行 kill 系统调用
// 异步没仔细看(要支持 pidfd 才行),因为 reaper 是单独于 lmkd 另起的一个线程,大概操作是
// lmkd 把 proc 就是放到队列里,然后 cv-notify 唤起 reaper 慢慢杀
killed_size = kill_one_process(procp, min_score_adj, ki, mi, wi, tm, pd);
if (killed_size >= 0) {
if (!lmk_state_change_start) {
lmk_state_change_start = true;
stats_write_lmk_state_changed(STATE_START);
}
break;
}
}
if (killed_size) {
break;
}
}
if (lmk_state_change_start) {
stats_write_lmk_state_changed(STATE_STOP);
}
return killed_size;
}
// Can be called only from the main thread.
static struct proc *proc_get_heaviest(int oomadj) {
// 找到对应 adj 的 list
struct adjslot_list *head = &procadjslot_list[ADJTOSLOT(oomadj)];
// 第一个 list 中的元素
struct adjslot_list *curr = head->next;
struct proc *maxprocp = NULL;
int maxsize = 0;
// adjslot_list 是一个双向链表,不断 next 遍历到 head 就意味着走完一遍了
while (curr != head) {
int pid = ((struct proc *)curr)->pid;
int tasksize = proc_get_size(pid);
if (tasksize < 0) {
struct adjslot_list *next = curr->next;
pid_remove(pid);
curr = next;
} else {
if (tasksize > maxsize) {
maxsize = tasksize;
maxprocp = (struct proc *)curr;
}
curr = curr->next;
}
}
return maxprocp;
}
// When called from a non-main thread, adjslot_list_lock read lock should be taken.
static struct proc *proc_adj_tail(int oomadj) {
return (struct proc *)adjslot_tail(&procadjslot_list[ADJTOSLOT(oomadj)]);
}
static struct adjslot_list *adjslot_tail(struct adjslot_list *head) {
struct adjslot_list *asl = head->prev;
return asl == head ? NULL : asl;
}
可以看出,这是一个从 min_adj 开始,遍历到最低 adj 优先级的流程,只需要 kill 得到一次正反馈(杀死 1 个有效的进程,能收回一定的内存页面 page),即表示查杀完成。
command 事件
至于 client 发出的 command 事件,那就简单了:
THE END
在这里总结一下吧,这篇文章通过以下路径来介绍 AOSP 进程管理的一些思路:
- 首先了解进程本身的数据结构,得知它所维护的有别于
task_struct的运行时信息。 - 并继续探讨存放进程的容器 LRU 列表,理解定制 LRU 下的三个 area 划分来定义一个粗粒度的优先级,并且利用 LRU 的淘汰机制来处理最不活跃的 cached 进程。
- 除了 cached 进程以外,运行中的进程也是内存大户,因此利用
memory factor和trim memory机制来要求开发者配合 OS,主动进行进程管理,以避免自身被杀。 - 但是出于对开发者的不信任,
AOSP仍然会在关键路径上用算法求出进程的adj,通过socket下发给lowmemorykiller。 lowmemorykiller在主循环接收上层发送的指令,通过特定的数据结构来维护adj及进程的关系,又使用PSI指标监听 memory stall 事件,一旦 low memory 事件到来并且 page cache 存在抖动行为,则立刻按adj杀死进程,并回收内存页面。